SPSS—描述性統(tǒng)計分析—探索性分析
菜單
除了可以計算基本的統(tǒng)計量之外,也可以給出一些簡單的檢驗結(jié)果和圖形�,有助于用戶進一步的分析數(shù)據(jù)����。使得用戶能夠從大量的分析結(jié)果之中挖掘到所需要的統(tǒng)計信息��。
適用范圍
對資料的性質(zhì)����、分布特點等完全不清楚的時候
Analyze -> Descriptive Statistics -> Expore
數(shù)據(jù)源
ceramics.sav
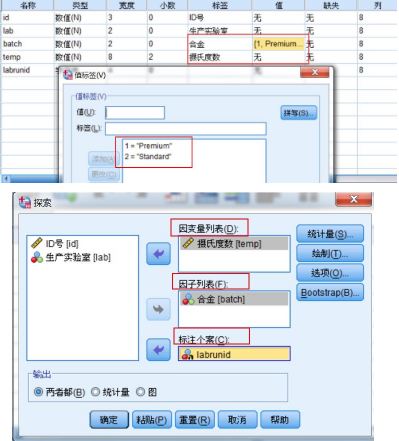
因變量列表
用于選入待分析的變量
因子列表
用于選擇分組變量�,根據(jù)該變量取值不同,分組分析因變量列表中的變量
標注個案
選擇標簽變量
統(tǒng)計量
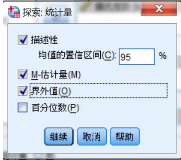
描述性
計算一般的描述性統(tǒng)計量���,及指定的均數(shù)可信區(qū)間
M-估計量
描述集中趨勢的統(tǒng)計量�,用于穩(wěn)健估計
界外值
分別輸出5個極大值和極小值
百分位數(shù)
輸出變量5%,10%,25%,50%,75%,90%,95%分位數(shù)
繪制
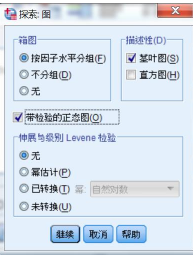
帶校驗的正態(tài)圖
選擇是否進行正態(tài)校驗�����,且是否輸出相應(yīng)的Q-Q圖
伸展與級別Levene檢驗
當選入分組變量時����,該功能才被激活�����,主要用于比較各組之間的離散程度是否一致�����。在這里可以選擇“未轉(zhuǎn)換”�,用于方差齊性檢驗
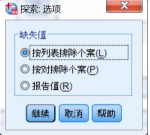
選項
輸出結(jié)果
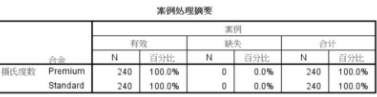
個案處理分析結(jié)果
包括觀測量�����、缺失值等信息
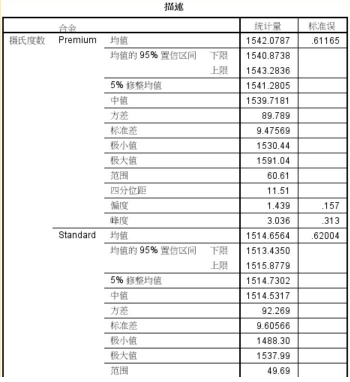
描述性統(tǒng)計量
包括:均值��、95%置信區(qū)間��、方差��、中位數(shù)�����、標準差、最大最小值�、偏度和峰度等信息
集中趨勢分布的3種較佳平穩(wěn)測度
較佳測度之一:中位數(shù)等
中位數(shù)
與均值和眾數(shù)大不相同,中位數(shù)是依賴于數(shù)據(jù)的主體部分而不是極值��,因此它的值不是過分地受某幾個觀察值的影響
平穩(wěn)估計量
如果對數(shù)據(jù)來源的總體做出某個假設(shè)(比如假定服從正態(tài)分布)����,則會有更佳分布位置的估計量,這種估計量稱為平穩(wěn)或穩(wěn)健測度的估計量
較佳測度之二:修正均值
由于均值深受極端值影響�,因此可通過去掉一些遠離主體數(shù)據(jù)的極端值,進而獲得一個對于分布位置簡單而平穩(wěn)的估計量
5%修正均值
是通過去掉所有觀察值中最大的5%和最小的5%的數(shù)據(jù)而獲得
調(diào)整后的均值與中位數(shù)可更好的利用數(shù)據(jù)
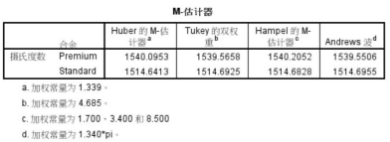
較佳測度之三:M估計
將極端值計算在內(nèi)���,而賦予比靠近中央值較小的一個權(quán)重,這種方法可借助M估計或采用廣義最大似然估計
M-estimators:平穩(wěn)分布位置的最大似然估計量
Huber的M估計值
Tukey雙權(quán)重估計值
Hampel重復(fù)遞減M估計值
Andrew波形估計值
M-估計器
極值
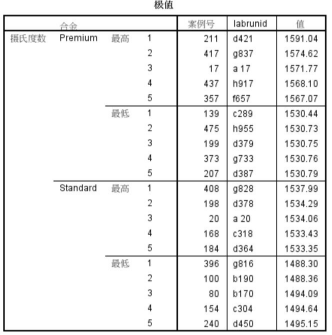
這里用標注個案來標記極值
正態(tài)性檢驗
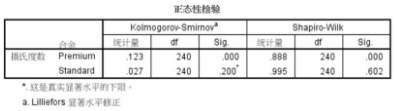
其中Premium變量對應(yīng)的K-S檢驗P值和Shapiro-Wilk檢驗P值均為0.000���,非常顯著����,應(yīng)該拒絕原假設(shè)���。所以,此變量的數(shù)據(jù)分布不是正態(tài)分布���。
而Standard數(shù)據(jù)的分布不是顯著的��,可以認為是正態(tài)分布
在‘探索’里出現(xiàn)的Kolmogorov-Smirnov 檢驗���,它的右上角有一個a 的注釋號���。它將Kolmogorov-Smirnov 檢驗改進用于一般的正態(tài)性檢驗。
而在‘非參數(shù)檢驗’里出現(xiàn)的Kolmogorov-Smirnov 檢驗�����,是沒有經(jīng)過糾正或改進的���。
該正態(tài)性檢驗只能做標準正態(tài)檢驗�����。
SPSS 規(guī)定:當樣本含量3≤n≤5000 時��,結(jié)果以Shapiro—Wilk(W 檢驗)為難�,當樣本含量n>5000 結(jié)果 以Kolmogorm —Smimov(D檢驗)為準�。
問題:
(1) 在實際應(yīng)用中常出現(xiàn)檢驗結(jié)果與直方圖、正態(tài)性概率圖不一致��,甚至幾種假設(shè)檢驗方法結(jié)果完全不同的情況。
(2) Shapiro—Wilk 檢驗(Ⅳ 檢驗)和經(jīng)過Lilliefors 顯著水平修正的Kolmogorov—Smirnov 檢驗(D 檢驗)是用 一個綜合指標(順序統(tǒng)計量Ⅳ 或D)來判定資料的正態(tài)性由于兩種方法都是用一個指標反映資料的正態(tài)性���,
所以當資料的正態(tài)峰和對稱性兩個特征有一個不滿足正態(tài)性要求時���,兩種方法出現(xiàn)假陰性錯誤的機率均較 大;而且兩種方法的檢驗統(tǒng)計量都是進行大小排序后得到�,所以易受異常值的影響。
(3) Kolmogorov—Smirnov 單一樣本檢驗是根據(jù)實際的累計頻數(shù)分布和理論的累計頻數(shù)分布的最大差異來檢驗資料的正態(tài)性�����,可對正態(tài)分布進行擬合優(yōu)度檢驗��。但它并非檢驗正態(tài)性的專用方法����,因此它的檢驗效率是最低的��,最容易受樣本量和異常值等因素的影響���。
方差齊性檢驗
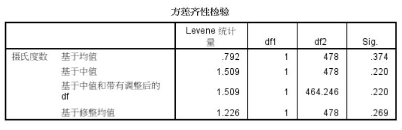
假設(shè)檢驗:
H0: 兩樣本方差齊性(相等���,或無顯著性差異)
如上圖,Sig > 0.2,并無顯著差異���。
正態(tài)Q-Q圖
正態(tài)性檢驗可以通過直觀的Q-Q圖��,進行人工驗證。
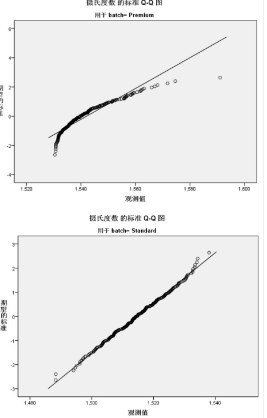
Q-Q圖是一種散點圖,對應(yīng)于正態(tài)分布的Q-Q圖,就是由標準正態(tài)分布的分位數(shù)為橫坐標,樣本值為縱坐標的散點圖. 要利用QQ圖鑒別樣本數(shù)據(jù)是否近似于正態(tài)分布,只需看QQ圖上的點是否近似地在一條直線附近,而且該直線的斜率為標準差,截距為均值.
如上圖�����,batch=Standard Q-Q圖上的點在一條直線附近����,可以認為是正態(tài)分布,和正態(tài)性檢驗Lilliefors�,Shapiro-Wilk得出的結(jié)果一致。
反趨勢正態(tài) Q-Q 圖
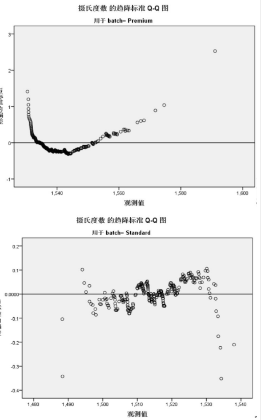
如上圖����,反趨勢正態(tài)概率Q-Q圖以變量的觀測值為X坐標,以變量的Z得分與期望值的偏差為Y坐標����。
batch=Standard 圖的觀測點離期望值很集中,說明符合正態(tài)分布����。
盒子圖
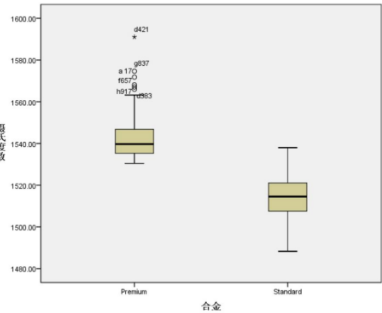
Premiun中有部分異常數(shù)據(jù)����,數(shù)據(jù)偏大�。需要進行異常值檢測。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學習CDA考試教材�,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330