分類算法之決策樹(Decision tree)
在前面兩篇文章中,分別介紹和討論了樸素貝葉斯分類與貝葉斯網(wǎng)絡(luò)兩種分類算法���。這兩種算法都以貝葉斯定理為基礎(chǔ),可以對分類及決策問題進行概率推斷。在這一篇文章中�,將討論另一種被廣泛使用的分類算法——決策樹(decision tree)。相比貝葉斯算法����,決策樹的優(yōu)勢在于構(gòu)造過程不需要任何領(lǐng)域知識或參數(shù)設(shè)置��,因此在實際應(yīng)用中����,對于探測式的知識發(fā)現(xiàn),決策樹更加適用���。
3.2���、決策樹引導(dǎo)
通俗來說,決策樹分類的思想類似于找對象?�,F(xiàn)想象一個女孩的母親要給這個女孩介紹男朋友���,于是有了下面的對話:
女兒:多大年紀(jì)了����?
母親:26����。
女兒:長的帥不帥����?
母親:挺帥的���。
女兒:收入高不����?
母親:不算很高��,中等情況��。
女兒:是公務(wù)員不�?
母親:是,在稅務(wù)局上班呢�。
女兒:那好,我去見見���。
這個女孩的決策過程就是典型的分類樹決策���。相當(dāng)于通過年齡、長相�、收入和是否公務(wù)員對將男人分為兩個類別:見和不見�。假設(shè)這個女孩對男人的要求是:30歲以下���、長相中等以上并且是高收入者或中等以上收入的公務(wù)員�,那么這個可以用下圖表示女孩的決策邏輯(聲明:此決策樹純屬為了寫文章而YY的產(chǎn)物�,沒有任何根據(jù),也不代表任何女孩的擇偶傾向��,請各位女同胞莫質(zhì)問我^_^):
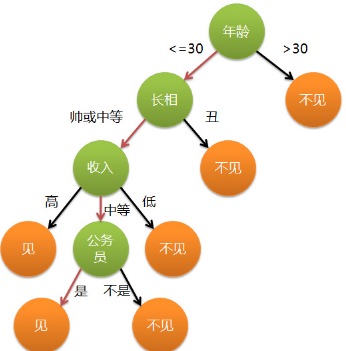
上圖完整表達了這個女孩決定是否見一個約會對象的策略��,其中綠色節(jié)點表示判斷條件���,橙色節(jié)點表示決策結(jié)果,箭頭表示在一個判斷條件在不同情況下的決策路徑�,圖中紅色箭頭表示了上面例子中女孩的決策過程。
這幅圖基本可以算是一顆決策樹�,說它“基本可以算”是因為圖中的判定條件沒有量化,如收入高中低等等��,還不能算是嚴(yán)格意義上的決策樹�,如果將所有條件量化,則就變成真正的決策樹了����。
有了上面直觀的認(rèn)識,我們可以正式定義決策樹了:
決策樹(decision tree)是一個樹結(jié)構(gòu)(可以是二叉樹或非二叉樹)。其每個非葉節(jié)點表示一個特征屬性上的測試��,每個分支代表這個特征屬性在某個值域上的輸出���,而每個葉節(jié)點存放一個類別�����。使用決策樹進行決策的過程就是從根節(jié)點開始�����,測試待分類項中相應(yīng)的特征屬性��,并按照其值選擇輸出分支���,直到到達葉子節(jié)點,將葉子節(jié)點存放的類別作為決策結(jié)果��。
可以看到�����,決策樹的決策過程非常直觀��,容易被人理解。目前決策樹已經(jīng)成功運用于醫(yī)學(xué)���、制造產(chǎn)業(yè)�、天文學(xué)�����、分支生物學(xué)以及商業(yè)等諸多領(lǐng)域��。知道了決策樹的定義以及其應(yīng)用方法���,下面介紹決策樹的構(gòu)造算法。
3.3��、決策樹的構(gòu)造
不同于貝葉斯算法����,決策樹的構(gòu)造過程不依賴領(lǐng)域知識,它使用屬性選擇度量來選擇將元組最好地劃分成不同的類的屬性�����。所謂決策樹的構(gòu)造就是進行屬性選擇度量確定各個特征屬性之間的拓撲結(jié)構(gòu)�。
構(gòu)造決策樹的關(guān)鍵步驟是分裂屬性�����。所謂分裂屬性就是在某個節(jié)點處按照某一特征屬性的不同劃分構(gòu)造不同的分支����,其目標(biāo)是讓各個分裂子集盡可能地“純”���。盡可能“純”就是盡量讓一個分裂子集中待分類項屬于同一類別��。分裂屬性分為三種不同的情況:
1���、屬性是離散值且不要求生成二叉決策樹。此時用屬性的每一個劃分作為一個分支�����。
2����、屬性是離散值且要求生成二叉決策樹。此時使用屬性劃分的一個子集進行測試�,按照“屬于此子集”和“不屬于此子集”分成兩個分支。
3�����、屬性是連續(xù)值。此時確定一個值作為分裂點split_point����,按照>split_point和<=split_point生成兩個分支。
構(gòu)造決策樹的關(guān)鍵性內(nèi)容是進行屬性選擇度量��,屬性選擇度量是一種選擇分裂準(zhǔn)則�,是將給定的類標(biāo)記的訓(xùn)練集合的數(shù)據(jù)劃分D“最好”地分成個體類的啟發(fā)式方法,它決定了拓撲結(jié)構(gòu)及分裂點split_point的選擇���。
屬性選擇度量算法有很多���,一般使用自頂向下遞歸分治法,并采用不回溯的貪心策略���。這里介紹ID3和C4.5兩種常用算法。
3.3.1�、ID3算法
從信息論知識中我們直到,期望信息越小����,信息增益越大�����,從而純度越高���。所以ID3算法的核心思想就是以信息增益度量屬性選擇,選擇分裂后信息增益最大的屬性進行分裂���。下面先定義幾個要用到的概念����。
設(shè)D為用類別對訓(xùn)練元組進行的劃分��,則D的熵(entropy)表示為:
=-\sum%20^m_{i=1}p_ilog_2(p_i) "info(D)=-\sum ^m_{i=1}p_ilog_2(p_i)")
其中pi表示第i個類別在整個訓(xùn)練元組中出現(xiàn)的概率�,可以用屬于此類別元素的數(shù)量除以訓(xùn)練元組元素總數(shù)量作為估計。熵的實際意義表示是D中元組的類標(biāo)號所需要的平均信息量���。
現(xiàn)在我們假設(shè)將訓(xùn)練元組D按屬性A進行劃分�����,則A對D劃分的期望信息為:
=\sum%20^v_{j=1}\frac{|D_j|}{|D|}info(D_j) "info_A(D)=\sum ^v_{j=1}\frac{|D_j|}{|D|}info(D_j)")
而信息增益即為兩者的差值:
=info(D)-info_A(D) "gain(A)=info(D)-info_A(D)")
ID3算法就是在每次需要分裂時�,計算每個屬性的增益率��,然后選擇增益率最大的屬性進行分裂。下面我們繼續(xù)用SNS社區(qū)中不真實賬號檢測的例子說明如何使用ID3算法構(gòu)造決策樹����。為了簡單起見,我們假設(shè)訓(xùn)練集合包含10個元素:
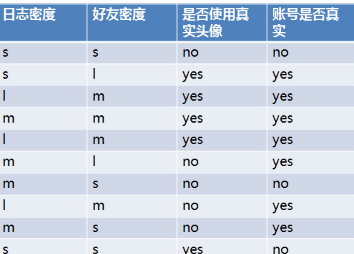
其中s�、m和l分別表示小、中和大�。
設(shè)L、F�、H和R表示日志密度、好友密度�、是否使用真實頭像和賬號是否真實,下面計算各屬性的信息增益����。
=-0.7log_20.7-0.3log_20.3=0.7*0.51+0.3*1.74=0.879 "info(D)=-0.7log_20.7-0.3log_20.3=0.7*0.51+0.3*1.74=0.879")
=0.3*(-\frac{0}{3}log_2\frac{0}{3}-\frac{3}{3}log_2\frac{3}{3})+0.4*(-\frac{1}{4}log_2\frac{1}{4}-\frac{3}{4}log_2\frac{3}{4})+0.3*(-\frac{1}{3}log_2\frac{1}{3}-\frac{2}{3}log_2\frac{2}{3})=0+0.326+0.277=0.603 "info_L(D)=0.3*(-\frac{0}{3}log_2\frac{0}{3}-\frac{3}{3}log_2\frac{3}{3})+0.4*(-\frac{1}{4}log_2\frac{1}{4}-\frac{3}{4}log_2\frac{3}{4})+0.3*(-\frac{1}{3}log_2\frac{1}{3}-\frac{2}{3}log_2\frac{2}{3})=0+0.326+0.277=0.603")
=0.879-0.603=0.276 "gain(L)=0.879-0.603=0.276")
因此日志密度的信息增益是0.276。
用同樣方法得到H和F的信息增益分別為0.033和0.553���。
因為F具有最大的信息增益��,所以第一次分裂選擇F為分裂屬性,分裂后的結(jié)果如下圖表示:
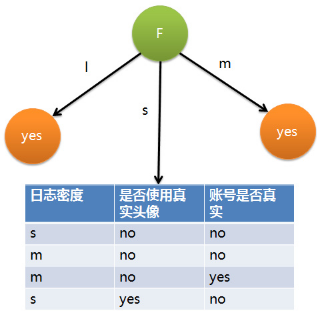
在上圖的基礎(chǔ)上�����,再遞歸使用這個方法計算子節(jié)點的分裂屬性,最終就可以得到整個決策樹�����。
上面為了簡便��,將特征屬性離散化了�,其實日志密度和好友密度都是連續(xù)的屬性。對于特征屬性為連續(xù)值�����,可以如此使用ID3算法:
先將D中元素按照特征屬性排序�,則每兩個相鄰元素的中間點可以看做潛在分裂點,從第一個潛在分裂點開始���,分裂D并計算兩個集合的期望信息���,具有最小期望信息的點稱為這個屬性的最佳分裂點,其信息期望作為此屬性的信息期望��。
3.3.2����、C4.5算法
ID3算法存在一個問題�����,就是偏向于多值屬性�����,例如����,如果存在唯一標(biāo)識屬性ID���,則ID3會選擇它作為分裂屬性���,這樣雖然使得劃分充分純凈,但這種劃分對分類幾乎毫無用處�����。ID3的后繼算法C4.5使用增益率(gain ratio)的信息增益擴充���,試圖克服這個偏倚�����。
C4.5算法首先定義了“分裂信息”���,其定義可以表示成:
=-\sum%20^v_{j=1}\frac{|D_j|}{|D|}log_2(\frac{|D_j|}{|D|}) "split\_info_A(D)=-\sum ^v_{j=1}\frac{|D_j|}{|D|}log_2(\frac{|D_j|}{|D|})")
其中各符號意義與ID3算法相同,然后��,增益率被定義為:
=\frac{gain(A)}{split\_info(A)} "gain\_ratio(A)=\frac{gain(A)}{split\_info(A)}")
C4.5選擇具有最大增益率的屬性作為分裂屬性����,其具體應(yīng)用與ID3類似,不再贅述���。
3.4�、關(guān)于決策樹的幾點補充說明
3.4.1���、如果屬性用完了怎么辦
在決策樹構(gòu)造過程中可能會出現(xiàn)這種情況:所有屬性都作為分裂屬性用光了,但有的子集還不是純凈集�����,即集合內(nèi)的元素不屬于同一類別�����。在這種情況下,由于沒有更多信息可以使用了��,一般對這些子集進行“多數(shù)表決”���,即使用此子集中出現(xiàn)次數(shù)最多的類別作為此節(jié)點類別���,然后將此節(jié)點作為葉子節(jié)點。
3.4.2�����、關(guān)于剪枝
在實際構(gòu)造決策樹時����,通常要進行剪枝,這時為了處理由于數(shù)據(jù)中的噪聲和離群點導(dǎo)致的過分?jǐn)M合問題�����。剪枝有兩種:
先剪枝——在構(gòu)造過程中���,當(dāng)某個節(jié)點滿足剪枝條件��,則直接停止此分支的構(gòu)造����。
后剪枝——先構(gòu)造完成完整的決策樹�����,再通過某些條件遍歷樹進行剪枝。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認(rèn)證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學(xué)習(xí)CDA考試教材,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫�,點擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330