如何報告回歸分析的結(jié)果_ 回歸分析結(jié)果報告
如何描述回歸模型和回歸系數(shù)
先簡單講一下一元回歸����。一元回歸��,即只涉及一個自變量(如X)����。這種模型在社會科學(xué)中既很少見(一個常見的例外是時間序列分析中以時間為自變量分析因變量的長期趨勢)���,也很容易報告。一般不需用表格����,只須寫一句話(如“自變量X的b = ?,std = ?, Beta = ?”)或給一個公式(如“Y = ? + ?b, where std = ?, Beta = ?”)就足夠了��。如果一項研究中有多個一元回歸分析���,那么就應(yīng)該也可以用一個表格來報告(參加��?)�����,以便于讀者對各模型之間作比較���。
接下來專門講多元回歸�。由于其涉及諸多參數(shù),有的必須報告�、有的酌情而定、有完全不必����,為了便于說明��,我按SPSS回歸分析的輸出結(jié)果(其它統(tǒng)計軟件大同小異)�����,做了一個如何報告回歸模型和回歸系數(shù)的一覽表(表一)�。如表所示��,我將各種參數(shù)分成“必須報告”��、“建議報告”����、“一般不必”和“完全不必”四類。我的分類標(biāo)準(zhǔn)來自于公認(rèn)的假設(shè)檢驗所涉及的四個方面�,即變量之間關(guān)系的顯著性、強(qiáng)度�����、方向和形式(詳見“解釋變量關(guān)系時必須考慮的四個問題”一文)�����。也就是說,每個參數(shù)的取舍���,應(yīng)該而且可以由其是否提供了不重復(fù)的顯著性(即Sig)����、強(qiáng)度(B或Beta的值)����、方向(B或Beta的符號)和形式(自變量的轉(zhuǎn)換)信息而定的。
表一�、如何報告回歸模型和回歸系數(shù)之一覽表
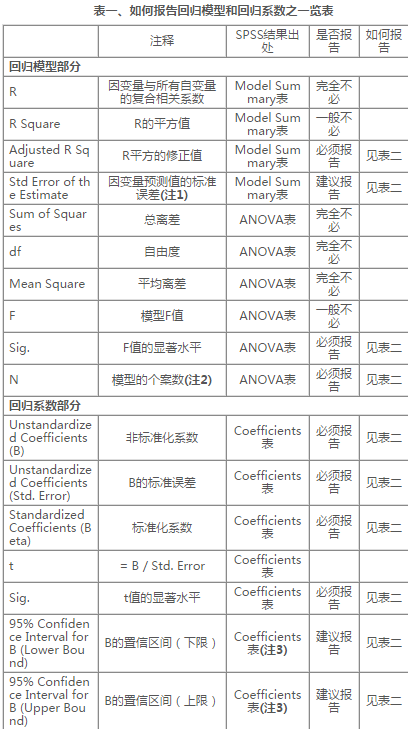
注1:因變量預(yù)測值的標(biāo)準(zhǔn)誤差描述了該模型的精確度(precision),如表二中的因變量是當(dāng)前年薪�����,其預(yù)測誤差為���?�����,即如果用該模型(包括起薪、工齡和性別三個自變量)去預(yù)測條件相同的企業(yè)中的員工年薪,則可以知道��?�。這種信息無法從模型的其它參數(shù)(如R平方或其修正值、顯著水平�����、各自變量的B或Beta)中得知���。
注2:如果因變量和所有自變量都沒有缺省值���,那么模型的個案數(shù)就等于樣本數(shù)。但變量常有缺省值�,這時模型的個案數(shù)就會小于樣本數(shù)、有時兩者相差很大(當(dāng)然是個嚴(yán)重問題)��,所以一定要報告前者����。SPSS并不直接顯示該信息,但很容易計算�,等于 ANOVA表中的Total df + 1就是了。
注3:B的置信區(qū)間�,是用來檢驗B的顯著水平的另一工具(如果上���、下限之間包含了0,說明B在95%的水平上不顯著)�����,以彌補(bǔ)t檢驗及其Sig值的不足�����。這是一個經(jīng)典又有復(fù)雜的問題����,叫做Null Hypothesis Significance Test (NHST),本文不做詳談��。有興趣的讀者可以參見有關(guān)網(wǎng)頁(R. C. Fraley; D. J. Denis)���。SPSS不直接給出B的置信區(qū)間����,需要在“Statistics”一項中要求添加��。如右圖所示�,SPSS回歸分析的輸出結(jié)果中�,內(nèi)定只顯示“Estimates” 和”Model fit”兩項(即會產(chǎn)生表一中除了置信區(qū)間之外的其它各項參數(shù))����。建議加選“Confidence intervals”�����。
現(xiàn)在用一個實例來演示如何報告回歸分析結(jié)果�。為了便于大家重復(fù)這個實例,我使用的數(shù)據(jù)是SPSS自帶的world95.sav����。這是聯(lián)合國教科文組織(或世界銀行之類機(jī)構(gòu))發(fā)表的1995年全球109個國家或地區(qū)的“國情”數(shù)據(jù),其中含有人口����、地理、經(jīng)濟(jì)�����、社會���、文化等26個指標(biāo)�����。我以其中的birth_rt(每1000人的出生率)為因變量�,gpd_car(人均國內(nèi)生成總值)、urban(城市化����,即人口中城市人口比例)、literacy(識字率��、即人口中能閱讀者比例)和calories(每天卡路里攝入量)等四項為自變量�。按表一的原則,我將該回歸分析的結(jié)果報告在表二中:
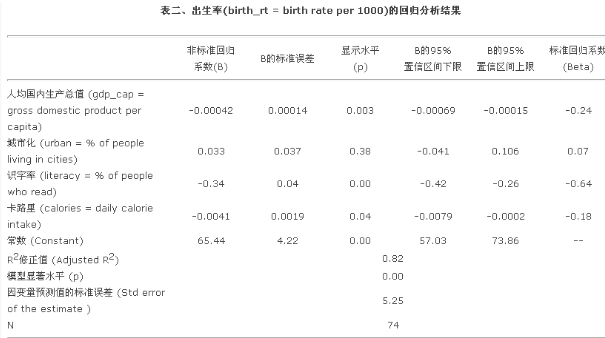
限于篇幅和本文目的�,我不對表二的各參數(shù)作解讀。但想對表中的有關(guān)格式做些補(bǔ)充說明�����。
-
如何給表格取標(biāo)題:一般只須描述表內(nèi)的內(nèi)容即可�����。那么���,本表的內(nèi)容是什么呢����?是出生率對四個自變量作回歸的結(jié)果���。該四個自變量在表內(nèi)均有詳細(xì)介紹���,故不必在表格標(biāo)題中重復(fù)�����。
-
如何描述變量(包括因變量和自變量):我先給出每個變量的理論概念名(如必要�,可以用英文)、然后在括號中注明其對應(yīng)的SPSS變量名(這并非必須��、而是為了便于大家對照手頭的SPSS數(shù)據(jù))和操作定義(很有必要���、強(qiáng)烈推薦�,從中讀者可以看到變量是否做過轉(zhuǎn)換��、從而得知有關(guān)關(guān)系的形式�����、即線性還是非線性)。為何要如何詳細(xì)地描述變量����?APA手冊對如何制作各種定量分析結(jié)果的表格或圖形有一條“獨立信息”的基本原則,即每個圖表要包含基本信息�、以致讀者不需參照正文而能夠獨立讀懂該圖表。因此���,簡單地將SPSS輸出結(jié)果黏貼過來��,雖是最常見的做法�、但是很壞的習(xí)慣�。
-
是否需要報告常數(shù)(Constant):一定要。常數(shù)對解讀回歸模型的實際社會意義����,有十分重要的作用。如本表中的常數(shù) = 65.444�,意即全球(74個國家或地區(qū))的平均出生率(即在控制了四項自變量的影響之后)為千分之65.4,等等�。有一點須注意的是在SPSS的輸出結(jié)果中,常數(shù)是放在第一行的��。應(yīng)該搬到其它自變量之后。
-
報告哪個回歸系數(shù)(即標(biāo)準(zhǔn)化還是非標(biāo)準(zhǔn)化系數(shù)):這是最常見問題�。以前曾有過“預(yù)測派”和“解釋派”之爭,前者主張只要報告B就夠了����、而后者則認(rèn)為只要報告Beta就行了。其實兩者反映的是不同的信息�,B不受因變量變異程度(variability)的影響、所以同一自變量在各回歸模型中的B是可以比較的(很多理論假設(shè)需要檢驗的就是這一問題)�;而Beta受因變量變異程度的影響而無法跨越本模型、但是卻因其標(biāo)準(zhǔn)化而可以與同一模型中的其它Beta相比(也有很多理論假設(shè)希望解決的是這個問題)�。因此���,APA手冊建議同時報告兩者(英文第五版pp. 160-161)����。
-
小數(shù)點之后取幾位:APA手冊認(rèn)為��,一般的定量分析結(jié)果只須保留兩位小數(shù)足夠�����。對回歸結(jié)果來說���,Beta��、R2值�����、顯著水平等標(biāo)準(zhǔn)化參數(shù)(即其取值均在0與1之間)取兩位小數(shù)最合適��。B及其相關(guān)指標(biāo)(標(biāo)準(zhǔn)誤差�、置信區(qū)間)是非標(biāo)準(zhǔn)化的(即取值可以是任意大或任意小)��,所以要酌情而定�����,根據(jù)變量的量表(scale���,即取值范圍)大小而多取��、少取甚至不取小數(shù)點����。一般而言���,當(dāng)自變量的量表大于因變量時��,其B會取小值�、所以需要多取一至數(shù)位小數(shù);相反�,自變量的量表小于因變量時,其B會取大值��、所以可以少取甚至不取小數(shù)�����。在本例中��,GDP和卡路里的量表都遠(yuǎn)大于出生率����,所以它們的B值看上去很?����。ǖ灰欢ㄒ馕吨绊懶���。?����。因此�����,我就沒有機(jī)械地只取兩位小數(shù)���。大家如果仔細(xì)看一下表二��,就會發(fā)現(xiàn)我的“酌情”規(guī)則是“最后一位0之后取兩位”�,如-0.00042�、0.033、-0.034�、-0.0041,這與APA手冊的“取兩位小數(shù)”原則的基本精神是一致的�。我們?nèi)粘R姷降膯栴},主要是保留過多的小數(shù)點���,往往是是直接黏貼SPSS的結(jié)果(其內(nèi)定是6位小數(shù))而不加編輯而造成���。
-
表格內(nèi)是否有橫豎分割線:按APA的規(guī)定,除了表格頂部���、底部和列標(biāo)題底部有三條橫線外�����,其余一概不用�。很多人簡單照搬Word表格的內(nèi)定線條,不做任何修飾�����。審稿專家一看就知是“菜鳥”或懶漢所為�����。
-
p是什么東東�?就是SPSS輸出中的Sig。p是所有統(tǒng)計學(xué)教科書中通用的符號����,Sig則只是SPSS的專用。前者更廣為認(rèn)知���。
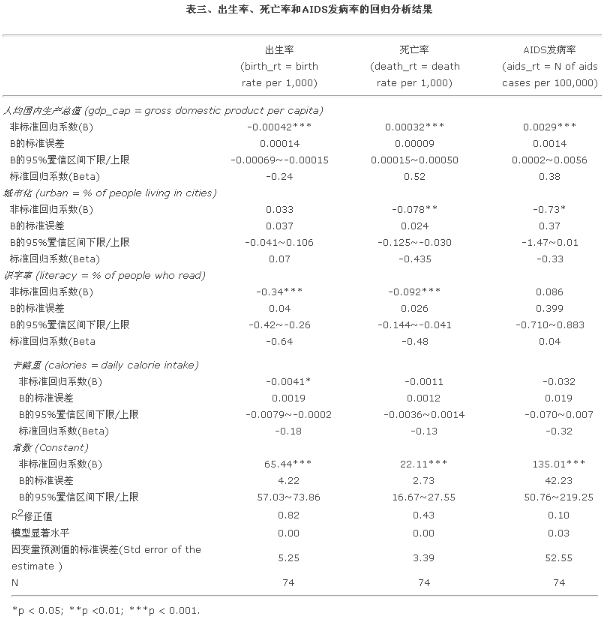
如何報告多個回歸模型?以上是如何報告一個回歸模型的結(jié)果���。實際上����,一項研究(即一篇論文)中往往涉及數(shù)個回歸模型。有些作者喜歡為每個回歸做一個類似表二的回歸結(jié)果表���。這種方法有兩個問題:一是占用過多的空間�、二是不利于對各模型進(jìn)行比較����。一般說來,應(yīng)該而且可以將平行(即全部自變量相同)或交集(即部分自變量相同)的回歸模型結(jié)果放在同一個表內(nèi)��。我們還是用world95數(shù)據(jù)����,再對死亡率和AIDS發(fā)病率分別做一個回歸,然后將三個模型的結(jié)果放在表三:
|
表三與表二的主要區(qū)別在于表二是橫向的(每列為同一類參數(shù))�����、而表三是縱向(每列為同一模型)����。表二中橫排的六類參數(shù)改成豎立的四行(其中的p值被星號代替��、置信區(qū)間的上下限合在一行)�����,以便讀者做橫向比較(這是所有定量分析結(jié)果的表格制作的一個基本原則)�。如果是英文報告�����,去掉中文后����,表三會變得簡潔明了很多。
如何報告變量特征和自變量關(guān)系
如前所述��,因變量和自變量的特征以及自變量之間的相關(guān)關(guān)系���,是需要酌情考慮的輔助信息�����。鑒于本文已經(jīng)很長了��,我們簡單說一下����。變量特征主要指
-
變量的操作定義(問卷原文)
-
取值范圍(如0-100�����、0-1��、0或1��、1-5��、1-7等等���;好雪問的��,如果數(shù)據(jù)做過對數(shù)���、平方、開方�����、倒數(shù)等轉(zhuǎn)換����,就應(yīng)該而且最適合在這里報告)
-
描述性統(tǒng)計值(均值����、標(biāo)準(zhǔn)差�����、偏度Skewness����、峰度Kurtosis等)
一種值得推薦的方法,是將所有變量的上述特征列在一個表中(表四)��、放到論文的附錄中去����、供有興趣的讀者查閱(類似的技術(shù)細(xì)節(jié)一般都可以放到附錄中去)。

最后我們談?wù)労醚┑牧硪粏栴}:如何報告自變量共線性的信息�。這其實就是自變量相關(guān)問題,初步的檢驗是看各自變量之間的相關(guān)矩陣(可以在上圖中添加Descriptive Statistics獲得)�,如果其中有相關(guān)系數(shù)超過0.50,就有必要作正式的共線性檢驗(即在上圖中選取Collinearity Diagnostics)�����,其會針對每個自變量產(chǎn)生兩個統(tǒng)計值:Tolerance和VIF (參見詳細(xì)解釋)。前者是該自變量對所有其它自變量做回歸的R2之余數(shù)(= 1 – R2����,如該自變量與其它自變量中的某些或全部高度相關(guān)����,Tolerance就會很少、甚至趨于0)�,而VIF則是Tolerance的倒數(shù)。兩者只須看其中之一就可以了�����。一般認(rèn)為��,Tolerance < 0.2或VIF > 5�,該變量就有較嚴(yán)重的共線性問題了。
如何報告這類問題��?通常和值得推薦的做法是將自變量的相關(guān)矩陣表放在附錄中�,而在論文正文中的方法部分(或結(jié)果部分),用文字簡單描述一下這些相關(guān)系數(shù)的最大和最小值�。如上所述,如果有系數(shù)>0.5,則還有接著用文字分別描述一下這些變量的tolerance值�����。另外����,還可以將Tolerance加到表四(作為新的一列)或自變量相關(guān)矩陣表(作為最底部新的一行)中去,但沒有必要專門替Tolerance和VIF做一個單獨的表格���。數(shù)據(jù)分析培訓(xùn)
|
推薦學(xué)習(xí)書籍
《CDA一級教材》適合CDA一級考生備考���,也適合業(yè)務(wù)及數(shù)據(jù)分析崗位的從業(yè)者提升自我。完整電子版已上線CDA網(wǎng)校����,累計已有10萬+在讀~

免費加入閱讀:https://edu.cda.cn/goods/show/3151?targetId=5147&preview=0
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認(rèn)證考試,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學(xué)習(xí)CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330