【案例】R語言與機器學習學習筆記(分類算法)
人工神經(jīng)網(wǎng)絡(ANN)��,簡稱神經(jīng)網(wǎng)絡����,是一種模仿生物神經(jīng)網(wǎng)絡的結(jié)構(gòu)和功能的數(shù)學模型或計算模型。神經(jīng)網(wǎng)絡由大量的人工神經(jīng)元聯(lián)結(jié)進行計算�。大多數(shù)情況下人工神經(jīng)網(wǎng)絡能在外界信息的基礎上改變內(nèi)部結(jié)構(gòu)�,是一種自適應系統(tǒng)?���,F(xiàn)代神經(jīng)網(wǎng)絡是一種非線性統(tǒng)計性數(shù)據(jù)建模工具,常用來對輸入和輸出間復雜的關系進行建模�,或用來探索數(shù)據(jù)的模式。
人工神經(jīng)網(wǎng)絡從以下四個方面去模擬人的智能行為:
-
物理結(jié)構(gòu):人工神經(jīng)元將模擬生物神經(jīng)元的功能
-
計算模擬:人腦的神經(jīng)元有局部計算和存儲的功能�����,通過連接構(gòu)成一個系統(tǒng)����。人工神經(jīng)網(wǎng)絡中也有大量有局部處理能力的神經(jīng)元,也能夠?qū)⑿畔⑦M行大規(guī)模并行處理
-
存儲與操作:人腦和人工神經(jīng)網(wǎng)絡都是通過神經(jīng)元的連接強度來實現(xiàn)記憶存儲功能�����,同時為概括�、類比、推廣提供有力的支持
-
訓練:同人腦一樣���,人工神經(jīng)網(wǎng)絡將根據(jù)自己的結(jié)構(gòu)特性�����,使用不同的訓練��、學習過程���,自動從實踐中獲得相關知識
神經(jīng)網(wǎng)絡是一種運算模型��,由大量的節(jié)點(或稱“神經(jīng)元”�,或“單元”)和之間相互聯(lián)接構(gòu)成���。每個節(jié)點代表一種特定的輸出函數(shù)��,稱為激勵函數(shù)���。每兩個節(jié)點間的連接都代表一個對于通過該連接信號的加權值,稱之為權重�����,這相當于人工神經(jīng)網(wǎng)絡的記憶��。網(wǎng)絡的輸出則依網(wǎng)絡的連接方式��,權重值和激勵函數(shù)的不同而不同�����。而網(wǎng)絡自身通常都是對自然界某種算法或者函數(shù)的逼近����,也可能是對一種邏輯策略的表達。
一�、感知器
感知器相當于神經(jīng)網(wǎng)絡的一個單層,由一個線性組合器和一個二值閾值原件構(gòu)成:

構(gòu)成ANN系統(tǒng)的單層感知器:
-
感知器以一個實數(shù)值向量作為輸入����,計算這些輸入的線性組合,如果結(jié)果大于某個閾值����,就輸出1,否則輸出‐1��。
-
感知器函數(shù)可寫為:sign(w*x)有時可加入偏置b��,寫為sign(w*x b)
-
學習一個感知器意味著選擇權w0,…,wn的值���。所以感知器學習要考慮的候選假設空間H就是所有可能的實數(shù)值權向量的集合
算法訓練步驟:
1���、定義變量與參數(shù)x(輸入向量),w(權值向量),b(偏置),y(實際輸出),d(期望輸出),a(學習率參數(shù))
2���、初始化,n=0,w=0
3��、輸入訓練樣本��,對每個訓練樣本指定其期望輸出:A類記為1�����,B類記為-1
4����、計算實際輸出y=sign(w*x b)
5、更新權值向量w(n 1)=w(n) a[d-y(n)]*x(n),0
6��、判斷���,若滿足收斂條件����,算法結(jié)束��,否則返回3
注意����,其中學習率a為了權值的穩(wěn)定性不應過大,為了體現(xiàn)誤差對權值的修正不應過小����,說到底,這是個經(jīng)驗問題�。
從前面的敘述來看,感知器對于線性可分的例子是一定收斂的�,對于不可分問題,它沒法實現(xiàn)正確分類�����。這里與我們前面講到的支持向量機的想法十分的相近�����,只是確定分類直線的辦法有所不同��??梢赃@么說��,對于線性可分的例子,支持向量機找到了“最優(yōu)的”那條分類直線�����,而單層感知器找到了一條可行的直線��。
我們以鳶尾花數(shù)據(jù)集為例�,由于單層感知器是一個二分類器���,所以我們將鳶尾花數(shù)據(jù)也分為兩類�,“setosa”與“versicolor”(將后兩類均看做第2類)��,那么數(shù)據(jù)按照特征:花瓣長度與寬度做分類�。
運行下面的代碼:
[plain]view plaincopyprint?

-
#感知器訓練結(jié)果:
-
a<-0.2
-
w<-rep(0,3)
-
iris1<-t(as.matrix(iris[,3:4]))
-
d<-c(rep(0,50),rep(1,100))
-
e<-rep(0,150)
-
p<-rbind(rep(1,150),iris1)
-
max<-100000
-
eps<-rep(0,100000)
-
i<-0
-
repeat{
-
v<-w%*%p;
-
y<-ifelse(sign(v)>=0,1,0);
-
e<-d-y;
-
eps[i 1]<-sum(abs(e))/length(e)
-
if(eps[i 1]<0.01){
-
print("finish:");
-
print(w);
-
break;
-
}
-
w<-w a*(d-y)%*%t(p);
-
i<-i 1;
-
if(i>max){
-
print("max time loop");
-
print(eps[i])
-
print(y);
-
break;
-
}
-
}
-
#繪圖程序
-
plot(Petal.Length~Petal.Width,xlim=c(0,3),ylim=c(0,8),
-
data=iris[iris$Species=="virginica",])
-
data1<-iris[iris$Species=="versicolor",]
-
points(data1$Petal.Width,data1$Petal.Length,col=2)
-
data2<-iris[iris$Species=="setosa",]
-
points(data2$Petal.Width,data2$Petal.Length,col=3)
-
x<-seq(0,3,0.01)
-
y<-x*(-w[2]/w[3])-w[1]/w[3]
-
lines(x,y,col=4)
-
#繪制每次迭代的平均絕對誤差
-
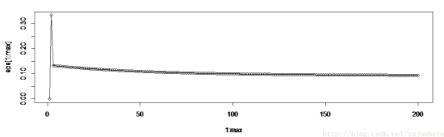
plot(1:i,eps[1:i],type="o")
分類結(jié)果如圖:
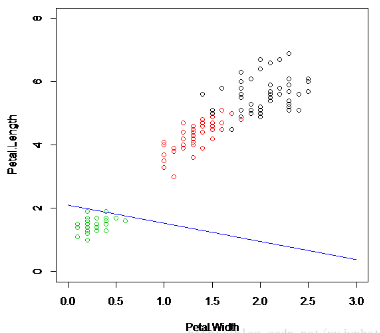
這是運行了7次得到的結(jié)果��。與我們前面的支持向量機相比,顯然神經(jīng)網(wǎng)絡的單層感知器分類不是那么的可信�,有些弱。
我們可以嘗試來做交叉驗證���,可以發(fā)現(xiàn)交叉驗證結(jié)果并不理想���。
二、線性神經(jīng)網(wǎng)絡
盡管當訓練樣例線性可分時�,感知器法則可以成功地找到一個權向量,但如果樣例不是線性可分時它將不能收斂��。因此����,人們設計了另一個訓練法則來克服這個不足,稱為delta法則�����。
如果訓練樣本不是線性可分的�,那么delta法則會收斂到目標概念的最佳近似。
delta法則的關鍵思想是使用梯度下降來搜索可能權向量的假設空間����,以找到最佳擬合訓練樣例的權向量。
我們將算法描述如下:
1���、定義變量與參數(shù)�。x(輸入向量),w(權值向量),b(偏置),y(實際輸出),d(期望輸出),a(學習率參數(shù))(為敘述簡便,我們可以將偏置并入權值向量中)
2����、初始化w=0
3、輸入樣本��,計算實際輸出與誤差��。e(n)=d-x*w(n)
4���、調(diào)整權值向量w(n 1)=w(n) a*x*e(n)
5��、判斷是否收斂���,收斂結(jié)束,否則返回3
Hayjin證明�����,只要學習率a<2/maxeign, delta法則按方差收斂���。其中maxeigen為x’x的最大特征值����。故我們這里使用1/maxeign作為a的值。
我們還是以上面的鳶尾花數(shù)據(jù)為例來說這個問題��。運行代碼:
[plain]view plaincopyprint?
-
p<-rbind(rep(1,150),iris1)
-
d<-c(rep(0,50),rep(1,100))
-
w<-rep(0,3)
-
a<-1/max(eigen(t(p)%*%p)$values)
-
max<-1000
-
e<-rep(0,150)
-
eps<-rep(0,1000)
-
i<-0
-
for(i in 1:max){
-
v<-w%*%p;
-
y<-v;
-
e<-d-y;
-
eps[i 1]<-sum(e^2)/length(e)
-
w<-w a*(d-y)%*%t(p);
-
if(i==max)
-
print(w)
-
}
得到分類直線:
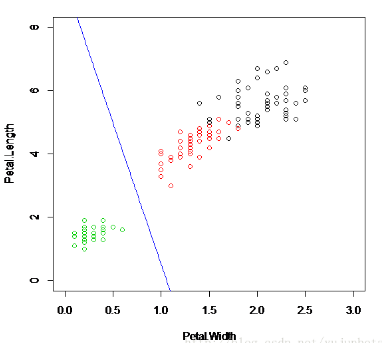
相比感知器分類而言已經(jīng)好了太多了����,究其原因不外乎傳遞函數(shù)由二值閾值函數(shù)變?yōu)榱司€性函數(shù)�,這也就是我們前面提到的delta法則會收斂到目標概念的最佳近似。增量法則漸近收斂到最小誤差假設�����,可能需要無限的時間�����,但無論訓練樣例是否線性可分都會收斂��。
為了明了這一點我們考慮鳶尾花數(shù)據(jù)后兩類花的分類(這里我們將前兩類看做一類)�����,使用感知器:
使用線性分類器:
但是要解釋的一點是�,收斂并不意味著分類效果更好,要解決線性不可分問題需要的是添加非線性輸入或者增加神經(jīng)元���。我們以Minsky & Papert (1969)提出的異或例子為例說明這一點����。
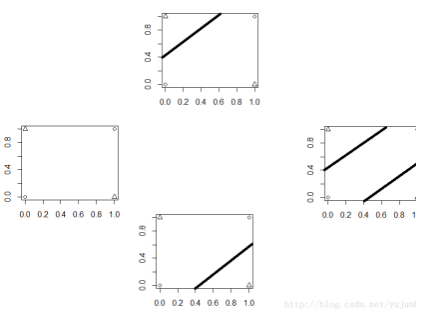
使用線性神經(jīng)網(wǎng)絡,代碼與上面完全相同����,略。
第一個神經(jīng)元輸出:
權值: [,1] [,2] [,3]
[1,] 0.75 0.5 -0.5
測試: [,1] [,2] [,3] [,4]
[1,] 1 0 1 1
第二個神經(jīng)元輸出:
權值: [,1] [,2] [,3]
[1,] 0.75 -0.5 0.5
測試: [,1] [,2] [,3] [,4]
[1,] 1 1 0 1
求解異或邏輯(相同取0����,不同取1)有結(jié)果:(代碼xor(c(1,0,1,1),c(1,1,0,1)))
[1] FALSE TRUE TRUE FALSE
即0,1�����,1���,0�����,分類正確����。
最后再說一點,Delta規(guī)則只能訓練單層網(wǎng)絡���,但這不會對其功能造成很大的影響����。從理論上說���,多層神經(jīng)網(wǎng)絡并不比單層神經(jīng)網(wǎng)絡更強大�����,他們具有同樣的能力。
三����、BP神經(jīng)網(wǎng)絡
1、sigmoid函數(shù)分類
回顧我們前面提到的感知器����,它使用示性函數(shù)作為分類的辦法。然而示性函數(shù)作為分類器它的跳點讓人覺得很難處理�����,幸好sigmoid函數(shù)y=1/(1 e^-x)有類似的性質(zhì),且有著光滑性這一優(yōu)良性質(zhì)�����。我們通過下圖可以看見sigmoid函數(shù)的圖像:

Sigmoid函數(shù)有著計算代價不高��,易于理解與實現(xiàn)的優(yōu)點但也有著欠擬合��,分類精度不高的特性���,我們在支持向量機一章中就可以看到sigmoid函數(shù)差勁的分類結(jié)果�。
2�、BP神經(jīng)網(wǎng)絡結(jié)構(gòu)
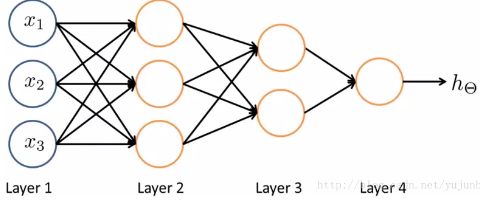
BP (Back Propagation)神經(jīng)網(wǎng)絡,即誤差反傳誤差反向傳播算法的學習過程��,由信息的正向傳播和誤差的反向傳播兩個過程組成�����。由下圖可知����,BP神經(jīng)網(wǎng)絡是一個三層的網(wǎng)絡:

-
輸入層(input layer):輸入層各神經(jīng)元負責接收來自外界的輸入信息,并傳遞給中間層各神經(jīng)元;
-
隱藏層(Hidden Layer):中間層是內(nèi)部信息處理層���,負責信息變換�,根據(jù)信息變化能力的需求����,中間層可以設計為單隱層或者多隱層結(jié)構(gòu);最后一個隱層傳遞到輸出層各神經(jīng)元的信息�,經(jīng)進一步處理后,完成一次學習的正向傳播處理過程��;
-
輸出層(Output Layer):顧名思義�,輸出層向外界輸出信息處理結(jié)果;
當實際輸出與期望輸出不符時��,進入誤差的反向傳播階段�。誤差通過輸出層���,按誤差梯度下降的方式修正各層權值����,向隱藏層����、輸入層逐層反傳�����。周而復始的信息正向傳播和誤差反向傳播過程����,是各層權值不斷調(diào)整的過程��,也是神經(jīng)網(wǎng)絡學習訓練的過程���,此過程一直進行到網(wǎng)絡輸出的誤差減少到可以接受的程度���,或者預先設定的學習次數(shù)為止。
3����、反向傳播算法
反向傳播這一算法把我們前面提到的delta規(guī)則的分析擴展到了帶有隱藏節(jié)點的神經(jīng)網(wǎng)絡。為了理解這個問題��,設想Bob給Alice講了一個故事�,然后Alice又講給了Ted,Ted檢查了這個事實真相�����,發(fā)現(xiàn)這個故事是錯誤的。現(xiàn)在 Ted 需要找出哪些錯誤是Bob造成的而哪些又歸咎于Alice���。當輸出節(jié)點從隱藏節(jié)點獲得輸入���,網(wǎng)絡發(fā)現(xiàn)出現(xiàn)了誤差,權系數(shù)的調(diào)整需要一個算法來找出整個誤差是由多少不同的節(jié)點造成的���,網(wǎng)絡需要問�����,“是誰讓我誤入歧途�?到怎樣的程度���?如何彌補���?”這時��,網(wǎng)絡該怎么做呢�?
同樣源于梯度降落原理,在權系數(shù)調(diào)整分析中的唯一不同是涉及到t(p,n)與y(p,n)的差分。通常來說Wi的改變在于:
alpha * s'(a(p,n)) * d(n) *X(p,i,n)
其中d(n)是隱藏節(jié)點n的函數(shù)���,讓我們來看:
一方面��,n 影響一個輸出節(jié)點越多����,n 造成網(wǎng)絡整體的誤差也越多。另一方面���,如果輸出節(jié)點影響網(wǎng)絡整體的誤差越少�,n 對輸出節(jié)點的影響也相應減少����。這里d(j)是對網(wǎng)絡的整體誤差的基值,W(n,j) 是 n 對 j 造成的影響�,d(j) * W(n,j) 是這兩種影響的總和���。但是 n 幾乎總是影響多個輸出節(jié)點,也許會影響每一個輸出結(jié)點�,這樣,d(n) 可以表示為:SUM(d(j)*W(n,j))
這里j是一個從n獲得輸入的輸出節(jié)點�,聯(lián)系起來,我們就得到了一個培訓規(guī)則�。
第1部分:在隱藏節(jié)點n和輸出節(jié)點j之間權系數(shù)改變,如下所示:
alpha *s'(a(p,n))*(t(p,n) - y(p,n)) * X(p,n,j)
第 2 部分:在輸入節(jié)點i和輸出節(jié)點n之間權系數(shù)改變����,如下所示:
alpha *s'(a(p,n)) * sum(d(j) * W(n,j)) * X(p,i,n)
這里每個從n接收輸入的輸出節(jié)點j都不同。關于反向傳播算法的基本情況大致如此�����。
通常把第 1部分稱為正向傳播�����,把第2部分稱為反向傳播����。反向傳播的名字由此而來。
4��、最速下降法與其改進
最速下降法的基本思想是:要找到某函數(shù)的最小值�,最好的辦法是沿函數(shù)的梯度方向探尋,如果梯度記為d,那么迭代公式可寫為w=w-alpha*d��,其中alpha可理解為我們前面提到的學習速率�。
最速下降法有著收斂速度慢(因為每次搜索與前一次均正交,收斂是鋸齒形的)���,容易陷入局部最小值等缺點�,所以他的改進辦法也有不少����,最常見的是增加動量項與學習率可變。
增加沖量項(Momentum)
修改權值更新法則����,使第n次迭代時的權值的更新部分地依賴于發(fā)生在第n‐1次迭代時的更新
Delta(w)(n)=-alpha*(1-mc)*Delta(w)(n) mc*Delta(w)(n-1)
右側(cè)第一項就是權值更新法則,第二項被稱為沖量項
梯度下降的搜索軌跡就像一個球沿誤差曲面滾下���,沖量使球從一次迭代到下一次迭代時以同樣的方向滾動
沖量有時會使這個球滾過誤差曲面的局部極小值或平坦區(qū)域
沖量也具有在梯度不變的區(qū)域逐漸增大搜索步長的效果�����,從而加快收斂��。
改變學習率
當誤差減小趨近目標時��,說明修正方向是正確的�����,可以增加學習率����;當誤差增加超過一個范圍時,說明修改不正確��,需要降低學習率�。
5、BP神經(jīng)網(wǎng)絡的實現(xiàn)
(1)數(shù)據(jù)讀入����,這里我們還是使用R的內(nèi)置數(shù)據(jù)——鳶尾花數(shù)據(jù),由于神經(jīng)網(wǎng)絡本質(zhì)是2分類的�,所以我們將鳶尾花數(shù)據(jù)也分為兩類(將前兩類均看做第2類),按照特征:花瓣長度與寬度做分類��。
(2)劃分訓練數(shù)據(jù)與測試數(shù)據(jù)
(3)初始化BP網(wǎng)絡��,采用包含一個隱含層的神經(jīng)網(wǎng)絡,訓練方法使用包含動量的最速下降法����,傳遞函數(shù)使用sigmoid函數(shù)。
(4)輸入樣本����,對樣本進行歸一化��,計算誤差�,求解誤差平方和
(5)判斷是否收斂
(6)根據(jù)誤差調(diào)整權值。權值根據(jù)以下公式進行調(diào)整:
Delta(w)= alpha *s'(a(p,n))*(t(p,n) - y(p,n)) * X(p,n,j)
其中���,alpha為學習率���,s'(a(p,n))*(t(p,n)- y(p,n))為局部梯度。此外�,由于使用了有動量因子的最速下降法,除第一次外�,后續(xù)改變量應為:
Delta(w)(n)=-alpha*(1-mc)*Delta(w)(n) mc*Delta(w)(n-1)
(7)測試,輸出分類正確率�。
完整的R代碼:
[plain]view plaincopyprint?
-
iris1<-as.matrix(iris[,3:4])
-
iris1<-cbind(iris1,c(rep(1,100),rep(0,50)))
-
set.seed(5)
-
n<-length(iris1[,1])
-
samp<-sample(1:n,n/5)
-
traind<-iris1[-samp,c(1,2)]
-
train1<-iris1[-samp,3]
-
testd<-iris1[samp,c(1,2)]
-
test1<-iris1[samp,3]
-
-
set.seed(1)
-
ntrainnum<-120
-
nsampdim<-2
-
-
net.nin<-2
-
net.nhidden<-3
-
net.nout<-1
-
w<-2*matrix(runif(net.nhidden*net.nin)-0.5,net.nhidden,net.nin)
-
b<-2*(runif(net.nhidden)-0.5)
-
net.w1<-cbind(w,b)
-
W<-2*matrix(runif(net.nhidden*net.nout)-0.5,net.nout,net.nhidden)
-
B<-2*(runif(net.nout)-0.5)
-
net.w2<-cbind(W,B)
-
-
traind_s<-traind
-
traind_s[,1]<-traind[,1]-mean(traind[,1])
-
traind_s[,2]<-traind[,2]-mean(traind[,2])
-
traind_s[,1]<-traind_s[,1]/sd(traind_s[,1])
-
traind_s[,2]<-traind_s[,2]/sd(traind_s[,2])
-
-
sampinex<-rbind(t(traind_s),rep(1,ntrainnum))
-
expectedout<-train1
-
-
eps<-0.01
-
a<-0.3
-
mc<-0.8
-
maxiter<-2000
-
iter<-0
-
-
errrec<-rep(0,maxiter)
-
outrec<-matrix(rep(0,ntrainnum*maxiter),ntrainnum,maxiter)
-
-
sigmoid<-function(x){
-
y<-1/(1 exp(-x))
-
return(y)
-
}
-
-
for(i in 1:maxiter){
-
hid_input<-net.w1%*%sampinex;
-
hid_out<-sigmoid(hid_input);
-
out_input1<-rbind(hid_out,rep(1,ntrainnum));
-
out_input2<-net.w2%*%out_input1;
-
out_out<-sigmoid(out_input2);
-
outrec[,i]<-t(out_out);
-
err<-expectedout-out_out;
-
sse<-sum(err^2);
-
errrec[i]<-sse;
-
iter<-iter 1;
-
if(sse<=eps)
-
break
-
-
Delta<-err*sigmoid(out_out)*(1-sigmoid(out_out))
-
delta<-(matrix(net.w2[,1:(length(net.w2[1,])-1)]))%*%Delta*sigmoid(hid_out)*(1-sigmoid(hid_out));
-
-
dWex<-Delta%*%t(out_input1)
-
dwex<-delta%*%t(sampinex)
-
-
if(i==1){
-
net.w2<-net.w2 a*dWex;
-
net.w1<-net.w1 a*dwex;
-
}
-
else{
-
net.w2<-net.w2 (1-mc)*a*dWex mc*dWexold;
-
net.w1<-net.w1 (1-mc)*a*dwex mc*dwexold;
-
}
-
-
dWexold<-dWex;
-
dwexold<-dwex;
-
}
-
-
-
testd_s<-testd
-
testd_s[,1]<-testd[,1]-mean(testd[,1])
-
testd_s[,2]<-testd[,2]-mean(testd[,2])
-
testd_s[,1]<-testd_s[,1]/sd(testd_s[,1])
-
testd_s[,2]<-testd_s[,2]/sd(testd_s[,2])
-
-
inex<-rbind(t(testd_s),rep(1,150-ntrainnum))
-
hid_input<-net.w1%*%inex
-
hid_out<-sigmoid(hid_input)
-
out_input1<-rbind(hid_out,rep(1,150-ntrainnum))
-
out_input2<-net.w2%*%out_input1
-
out_out<-sigmoid(out_input2)
-
out_out1<-out_out
-
-
out_out1[out_out<0.5]<-0
-
out_out1[out_out>=0.5]<-1
-
-
rate<-sum(out_out1==test1)/length(test1)
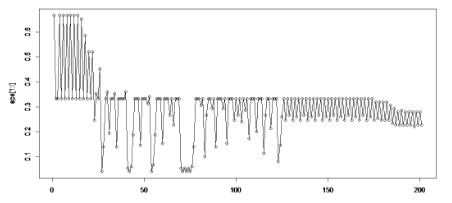
分類正確率為:0.9333333,是一個不錯的學習器����。這里需要注意的是動量因子mc的選取����,mc不能過小�,否則容易陷入局部最小而出不去,在本例中�����,如果mc=0.5��,分類正確率僅為:0.5333333���,學習效果很不理想����。
四�、R中的神經(jīng)網(wǎng)絡函數(shù)
單層的前向神經(jīng)網(wǎng)絡模型在包nnet中的nnet函數(shù),其調(diào)用格式為:
nnet(formula,data, weights, size, Wts, linout = F, entropy = F,
softmax = F, skip = F, rang = 0.7,decay = 0, maxit = 100,
trace = T)
參數(shù)說明:
size, 隱層結(jié)點數(shù)��;
decay, 表明權值是遞減的(可以防止過擬合)����;
linout, 線性輸出單元開關;
skip,是否允許跳過隱層�����;
maxit, 最大迭代次數(shù)�����;
Hess, 是否輸出Hessian值
適用于神經(jīng)網(wǎng)絡的方法有predict,print和summary等��,nnetHess函數(shù)用來計算在考慮了權重參數(shù)下的Hessian矩陣�����,并且檢驗是否是局部最小。
我們使用nnet函數(shù)分析Vehicle數(shù)據(jù)��。隨機選擇半數(shù)觀測作為訓練集���,剩下的作為測試集��,構(gòu)建只有包含3個節(jié)點的一個隱藏層的神經(jīng)網(wǎng)絡���。輸入如下程序:
[plain]view plaincopyprint?
-
library(nnet); #安裝nnet軟件包
-
library(mlbench); #安裝mlbench軟件包
-
data(Vehicle); #調(diào)入數(shù)據(jù)
-
n=length(Vehicle[,1]); #樣本量
-
set.seed(1); #設隨機數(shù)種子
-
samp=sample(1:n,n/2); #隨機選擇半數(shù)觀測作為訓練集
-
b=class.ind(Vehicle$Class); #生成類別的示性函數(shù)
-
test.cl=function(true,pred){true<-max.col(true);cres=max.col(pred);table(true,cres)};
-
a=nnet(Vehicle[samp,-19],b[samp,],size=3,rang=0.1,decay=5e-4,maxit=200); #利用訓練集中前18個變量作為輸入變量,隱藏層有3個節(jié)點,初始隨機權值在[-0.1,0.1]�,權值是逐漸衰減的。
-
test.cl(b[samp,],predict(a,Vehicle[samp,-19]))#給出訓練集分類結(jié)果
-
test.cl(b[-samp,],predict(a,Vehicle[-samp,-19]));#給出測試集分類結(jié)果
-
#構(gòu)建隱藏層包含15個節(jié)點的網(wǎng)絡����。接著上面的語句輸入如下程序:
-
a=nnet(Vehicle[samp,-19],b[samp,],size=15,rang=0.1,decay=5e-4,maxit=10000);
-
test.cl(b[samp,],predict(a,Vehicle[samp,-19]));
-
test.cl(b[-samp,],predict(a,Vehicle[-samp,-19]));
再看手寫數(shù)字案例
最后,我們回到最開始的那個手寫數(shù)字的案例����,我們試著利用支持向量機重做這個案例。(這個案例的描述與數(shù)據(jù)參見《R語言與機器學習學習筆記(分類算法)(1)》)
由于nnet包對輸入的維數(shù)有一定限制(我也不知道為什么���,可能在權值計算的時候出現(xiàn)了一些bug�����,反正將支持向量機那一節(jié)的代碼平行的移過來是會報錯的)��。我們這里采用手寫數(shù)字識別技術中常用的辦法處理這個案例:計算數(shù)字的特征�。選擇數(shù)字特征的辦法有許多種����,你隨便百度一篇論文都有敘述����。我們這里采用結(jié)構(gòu)特征與統(tǒng)計特征結(jié)合的辦法計算圖像的特征���。

我們這里采用的統(tǒng)計特征與上圖有一點的不同(結(jié)構(gòu)特征一致)����,我們是將圖片分為16塊(4*4),統(tǒng)計每個小方塊中點的個數(shù)�����,這樣我們就有25維的特征向量了����。為了保證結(jié)果的可比性�����,我們也報告支持向量機的分類結(jié)果。
運行下列代碼:
[plain]view plaincopyprint?
-
setwd("D:/R/data/digits/trainingDigits")
-
names<-list.files("D:/R/data/digits/trainingDigits")
-
data<-paste("train",1:1934,sep="")
-
for(i in 1:length(names))
-
assign(data[i],as.matrix(read.fwf(names[i],widths=rep(1,32))))
-
library(nnet)
-
label<-factor(rep(0:9,c(189,198,195,199,186,187,195,201,180,204)))
-
-
feature<-matrix(rep(0,length(names)*25),length(names),25)
-
for(i in 1:length(names)){
-
feature[i,1]<-sum(get(data[i])[,16])
-
feature[i,2]<-sum(get(data[i])[,8])
-
feature[i,3]<-sum(get(data[i])[,24])
-
feature[i,4]<-sum(get(data[i])[16,])
-
feature[i,5]<-sum(get(data[i])[11,])
-
feature[i,6]<-sum(get(data[i])[21,])
-
feature[i,7]<-sum(diag(get(data[i])))
-
feature[i,8]<-sum(diag(get(data[i])[,32:1]))
-
feature[i,9]<-sum((get(data[i])[17:32,17:32]))
-
feature[i,10]<-sum((get(data[i])[1:8,1:8]))
-
feature[i,11]<-sum((get(data[i])[9:16,1:8]))
-
feature[i,12]<-sum((get(data[i])[17:24,1:8]))
-
feature[i,13]<-sum((get(data[i])[25:32,1:8]))
-
feature[i,14]<-sum((get(data[i])[1:8,9:16]))
-
feature[i,15]<-sum((get(data[i])[9:16,9:16]))
-
feature[i,16]<-sum((get(data[i])[17:24,9:16]))
-
feature[i,17]<-sum((get(data[i])[25:32,9:16]))
-
feature[i,18]<-sum((get(data[i])[1:8,17:24]))
-
feature[i,19]<-sum((get(data[i])[9:16,17:24]))
-
feature[i,20]<-sum((get(data[i])[17:24,17:24]))
-
feature[i,21]<-sum((get(data[i])[25:32,17:24]))
-
feature[i,22]<-sum((get(data[i])[1:8,25:32]))
-
feature[i,23]<-sum((get(data[i])[9:16,25:32]))
-
feature[i,24]<-sum((get(data[i])[17:24,25:32]))
-
feature[i,25]<-sum((get(data[i])[25:32,25:32]))
-
}
-
data1 <- data.frame(feature,label)
-
m1<-nnet(label~.,data=data1,size=25,maxit = 2000,decay = 5e-6, rang = 0.1)
-
pred<-predict(m1,data1,type="class")
-
table(pred,label)
-
sum(diag(table(pred,label)))/length(names)
-
-
library("e1071")
-
m <- svm(feature,label,cross=10,type="C-classification")
-
m
-
summary(m)
-
pred<-fitted(m)
-
table(pred,label)
-
-
setwd("D:/R/data/digits/testDigits")
-
name<-list.files("D:/R/data/digits/testDigits")
-
data1<-paste("train",1:1934,sep="")
-
for(i in 1:length(name))
-
assign(data1[i],as.matrix(read.fwf(name[i],widths=rep(1,32))))
-
-
feature<-matrix(rep(0,length(name)*25),length(name),25)
-
for(i in 1:length(name)){
-
feature[i,1]<-sum(get(data1[i])[,16])
-
feature[i,2]<-sum(get(data1[i])[,8])
-
feature[i,3]<-sum(get(data1[i])[,24])
-
feature[i,4]<-sum(get(data1[i])[16,])
-
feature[i,5]<-sum(get(data1[i])[11,])
-
feature[i,6]<-sum(get(data1[i])[21,])
-
feature[i,7]<-sum(diag(get(data1[i])))
-
feature[i,8]<-sum(diag(get(data1[i])[,32:1]))
-
feature[i,9]<-sum((get(data1[i])[17:32,17:32]))
-
feature[i,10]<-sum((get(data1[i])[1:8,1:8]))
-
feature[i,11]<-sum((get(data1[i])[9:16,1:8]))
-
feature[i,12]<-sum((get(data1[i])[17:24,1:8]))
-
feature[i,13]<-sum((get(data1[i])[25:32,1:8]))
-
feature[i,14]<-sum((get(data1[i])[1:8,9:16]))
-
feature[i,15]<-sum((get(data1[i])[9:16,9:16]))
-
feature[i,16]<-sum((get(data1[i])[17:24,9:16]))
-
feature[i,17]<-sum((get(data1[i])[25:32,9:16]))
-
feature[i,18]<-sum((get(data1[i])[1:8,17:24]))
-
feature[i,19]<-sum((get(data1[i])[9:16,17:24]))
-
feature[i,20]<-sum((get(data1[i])[17:24,17:24]))
-
feature[i,21]<-sum((get(data1[i])[25:32,17:24]))
-
feature[i,22]<-sum((get(data1[i])[1:8,25:32]))
-
feature[i,23]<-sum((get(data1[i])[9:16,25:32]))
-
feature[i,24]<-sum((get(data1[i])[17:24,25:32]))
-
feature[i,25]<-sum((get(data1[i])[25:32,25:32]))
-
}
-
labeltest<-factor(rep(0:9,c(87,97,92,85,114,108,87,96,91,89)))
-
data2<-data.frame(feature,labeltest)
-
pred1<-predict(m1,data2,type="class")
-
table(pred1,labeltest)
-
sum(diag(table(pred1,labeltest)))/length(name)
-
-
pred<-predict(m,feature)
-
table(pred,labeltest)
-
sum(diag(table(pred,labeltest)))/length(name)
經(jīng)整理���,我們有如下輸出結(jié)果:
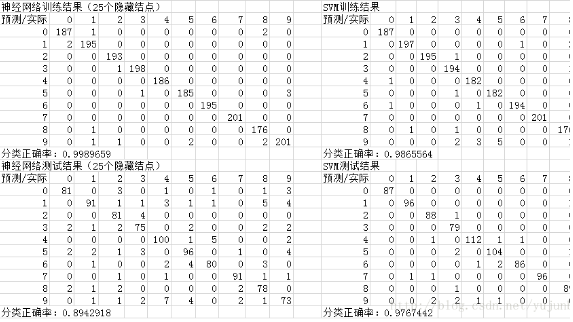
可以看到���,神經(jīng)網(wǎng)絡與支持向量機還是有一定的可比性,但支持向量機的結(jié)果還是要優(yōu)于神經(jīng)網(wǎng)絡的。
這里我們神經(jīng)網(wǎng)絡取25個節(jié)點(隱藏層)似乎出現(xiàn)了過擬合的現(xiàn)象(雖然還不算過于嚴重)我們應該減少節(jié)點個數(shù)得到更佳的預測結(jié)果�����。
關于節(jié)點的選擇是個經(jīng)驗活����,我們沒有一定的規(guī)則。可以多試幾次�����,結(jié)合訓練集正確率與測試集正確率綜合研判���,但是構(gòu)造神經(jīng)網(wǎng)絡的代價是高昂的�,所以有一個不太壞的結(jié)果也就可以停止了。(其他參數(shù)的選擇同樣如此���,但是不如size那么重要)
特征的選取對于識別問題來說相當?shù)闹匾苍S主成分在選擇特征時作用會比我們這樣的選擇更好����,但是代價也更高�����,還有我們應該如何選擇主成分����,怎么選擇(選擇哪張圖的主成分)都是需要考慮的�����。
五����、神經(jīng)網(wǎng)絡還是支持向量機
從上面的敘述可以看出,神經(jīng)網(wǎng)絡與我們前面說的支持向量機有不少相似的地方����,那么我們應該選擇誰呢?下面是兩種方法的一個簡明對比:
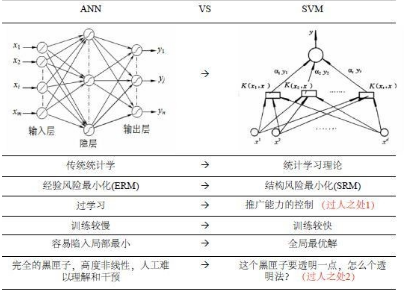
– SVM的理論基礎比NN更堅實����,更像一門嚴謹?shù)摹翱茖W”(三要素:問題的表示、問題的解決�、證明)
– SVM ——嚴格的數(shù)學推理
–ANN ——強烈依賴于工程技巧
–推廣能力取決于“經(jīng)驗風險值”和“置信范圍值”,ANN不能控制兩者中的任何一個�����。
–ANN設計者用高超的工程技巧彌補了數(shù)學上的缺陷——設計特殊的結(jié)構(gòu)�,利用啟發(fā)式算法,有時能得到出人意料的好結(jié)果���。
正如費曼指出的那樣“我們必須從一開始就澄清一個觀點���,就是如果某事不是科學,它并不一定不好��。比如說��,愛情就不是科學���。因此��,如果我們說某事不是科學����,并不是說它有什么不對���,而只是說它不是科學����?���!迸cSVM相比,ANN不像一門科學,更像一門工程技巧���,但并不意味著它就一定就不好���。
CDA數(shù)據(jù)分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學習CDA考試教材,點擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量,點擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330