R與并行計(jì)算
本文首先介紹了并行計(jì)算的基本概念,然后簡要闡述了R和并行計(jì)算的關(guān)系�����。之后作者從R語言用戶的使用角度討論了隱式和顯示兩種并行計(jì)算模式���,并給出了相應(yīng)的案例�。隱式并行計(jì)算模式不僅提供了簡單清晰的使用方法���,而且很好的隱藏了并行計(jì)算的實(shí)現(xiàn)細(xì)節(jié)����。因此用戶可以專注于問題本身���。顯示并行計(jì)算模式則更加靈活多樣�����,用戶可以按照自己的實(shí)際問題來選擇數(shù)據(jù)分解��,內(nèi)存管理和計(jì)算任務(wù)分配的方式�����。最后�,作者探討了現(xiàn)階段R并行化的挑戰(zhàn)以及未來的發(fā)展。
R與并行計(jì)算
統(tǒng)計(jì)之都的小伙伴們對R�,SAS,SPSS�����, MATLAB之類的統(tǒng)計(jì)軟件的使用定是輕車熟路了�����,但是對并行計(jì)算(又名高性能計(jì)算����,分布式計(jì)算)等概念可能多少會(huì)感到有點(diǎn)陌生���。應(yīng)太云兄之邀�,在此給大家介紹一些關(guān)于并行計(jì)算的基本概念以及在R中的使用��。
什么是并行計(jì)算��?
并行計(jì)算,準(zhǔn)確地說應(yīng)該包括高性能計(jì)算機(jī)和并行軟件兩個(gè)方面����。在很長一段時(shí)間里,中國的高性能計(jì)算機(jī)處于世界領(lǐng)先水平��。在最近一期的世界TOP500超級(jí)計(jì)算機(jī)排名中�,中國的神威太湖之光列居榜首。 但是高性能計(jì)算機(jī)的應(yīng)用領(lǐng)域卻比較有限�,主要集中在軍事,航天航空等國防軍工以及科研領(lǐng)域���。對于多數(shù)個(gè)人��,中小型企業(yè)來說高性能計(jì)算機(jī)還是陽春白雪����。
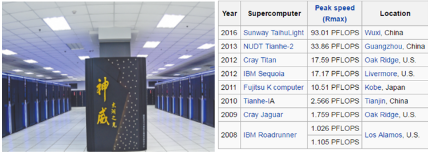
不過�����,近年來隨著個(gè)人PC機(jī)�,廉價(jià)機(jī)群,以及各種加速卡(NVIDIA GPU, Intel Xeon Phi, FPGA)的快速發(fā)展��,現(xiàn)在個(gè)人電腦已經(jīng)完全可以和過去的高性能計(jì)算機(jī)相媲美了。相比于計(jì)算機(jī)硬件的迅速發(fā)展��,并行軟件的發(fā)展多少有些滯后����,試想你現(xiàn)在使用的哪些軟件是支持并行化運(yùn)算的呢?

軟件的并行化需要更多的研發(fā)支持���,以及對大量串行算法和現(xiàn)有軟件的并行化��,這部分工作被稱之為代碼現(xiàn)代化(code modernization)��。聽起來相當(dāng)高大上的工作�����,然而在實(shí)際中大量的錯(cuò)誤修正(BUGFIX)��,底層數(shù)據(jù)結(jié)構(gòu)重寫���,軟件框架的更改�,以及代碼并行化之后帶來的運(yùn)行不確定性和跨平臺(tái)等問題極大地增加了軟件的開發(fā)維護(hù)成本和運(yùn)行風(fēng)險(xiǎn),這也使得這項(xiàng)工作在實(shí)際中并沒有想象中的那么吸引人���。
R為什么需要并行計(jì)算����?
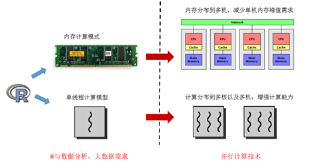
那么言歸正傳,讓我們回到R本身����。R作為當(dāng)前最流行的統(tǒng)計(jì)軟件之一,具有非常多的優(yōu)點(diǎn)���,比如豐富的統(tǒng)計(jì)模型與數(shù)據(jù)處理工具����,以及強(qiáng)大的可視化能力�����。但隨著數(shù)據(jù)量的日漸增大�,R的內(nèi)存使用方式和計(jì)算模式限制了R處理大規(guī)模數(shù)據(jù)的能力。從內(nèi)存角度來看�,R采用的是內(nèi)存計(jì)算模式(In-Memory),被處理的數(shù)據(jù)需要預(yù)取到主存(RAM)中���。其優(yōu)點(diǎn)是計(jì)算效率高�、速度快,但缺點(diǎn)是這樣一來能處理的問題規(guī)模就非常有限(小于RAM的大?����。?����。另一方面����,R的核心(R core)是一個(gè)單線程的程序。因此��,在現(xiàn)代的多核處理器上��,R無法有效地利用所有的計(jì)算內(nèi)核��。腦補(bǔ)一下�����,如果把R跑到具有260個(gè)計(jì)算核心的太湖之光CPU上��,單線程的R程序最多只能利用到1/260的計(jì)算能力�,而浪費(fèi)了其他259/260的計(jì)算核心。
怎么破���?并行計(jì)算��!
并行計(jì)算技術(shù)正是為了在實(shí)際應(yīng)用中解決單機(jī)內(nèi)存容量和單核計(jì)算能力無法滿足計(jì)算需求的問題而提出的����。因此�,并行計(jì)算技術(shù)將非常有力地?cái)U(kuò)充R的使用范圍和場景。最新版本的R已經(jīng)將parallel包設(shè)為了默認(rèn)安裝包�。可見R核心開發(fā)組也對并行計(jì)算非常重視了�。
R用戶:如何使用并行計(jì)算?
從用戶的使用方式來劃分����,R中的并行計(jì)算模式大致可以分為隱式和顯示兩種。下面我將用具體實(shí)例給大家做一個(gè)簡單介紹��。
隱式并行計(jì)算
隱式計(jì)算對用戶隱藏了大部分細(xì)節(jié)����,用戶不需要知道具體數(shù)據(jù)分配方式 ,算法的實(shí)現(xiàn)或者底層的硬件資源分配。系統(tǒng)會(huì)根據(jù)當(dāng)前的硬件資源來自動(dòng)啟動(dòng)計(jì)算核心����。顯然,這種模式對于大多數(shù)用戶來說是最喜聞樂見的����。我們可以在完全不改變原有計(jì)算模式以及代碼的情況下獲得更高的性能。常見的隱式并行方式包括:
1��、 使用并行計(jì)算庫�,如OpenBLAS,Intel MKL�,NVIDIA cuBLAS
這類并行庫通常是由硬件制造商提供并基于對應(yīng)的硬件進(jìn)行了深度優(yōu)化,其性能遠(yuǎn)超R自帶的BLAS庫�����,所以建議在編譯R的時(shí)候選擇一個(gè)高性能庫或者在運(yùn)行時(shí)通過LD_PRELOAD來指定加載庫�。具體的編譯和加載方法可以參見這篇博客的附錄部分【1】。在下面左圖中的矩陣計(jì)算比較實(shí)驗(yàn)中�����,并行庫在16核的CPU上輕松超過R原有庫百倍之多���。在右圖中�,我們可以看到GPU的數(shù)學(xué)庫對常見的一些分析算法也有相當(dāng)顯著的提速。

2���、使用R中的多線程函數(shù)
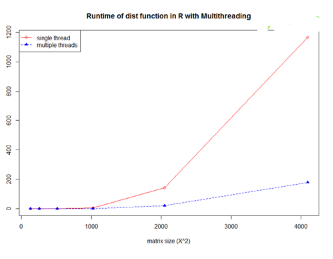
OpenMP是一種基于共享內(nèi)存的多線程庫,主要用于單節(jié)點(diǎn)上應(yīng)用程序加速��。最新的R在編譯時(shí)就已經(jīng)打開了OpenMP選項(xiàng)�����,這意味著一些計(jì)算可以在多線程的模式下運(yùn)行�����。比如R中的dist函數(shù)就 是一個(gè)多線程實(shí)現(xiàn)的函數(shù)����,通過設(shè)置線程數(shù)目來使用當(dāng)前機(jī)器上的多個(gè)計(jì)算核心,下面我們用一個(gè)簡單的例子來感受下并行計(jì)算的效率�����, GitHub上有完整代碼【2】��, 此代碼需在Linux系統(tǒng)下運(yùn)行。
#comparison of single thread and multiple threads run
for(i in 6:11) {
ORDER <- 2^i
m <- matrix(rnorm(ORDER*ORDER),ORDER,ORDER);
.Internal(setMaxNumMathThreads(1)); .Internal(setNumMathThreads(1)); res <- system.time(d <- dist(m))
print(res)
.Internal(setMaxNumMathThreads(20)); .Internal(setNumMathThreads(20)); res <- system.time(d <- dist(m))
print(res)
}
3���、使用并行化包
在R高性能計(jì)算列表【3】中已經(jīng)列出了一些現(xiàn)有的并行化包和工具�。用戶使用這些并行化包可以像使用其他所有R包一樣快捷方便��,始終專注于所處理的問題本身���,而不必考慮太多關(guān)于并行化實(shí)現(xiàn)以及性能提升的問題����。我們以H2O.ai【4】為例���。 H2O后端使用Java實(shí)現(xiàn)多線程以及多機(jī)計(jì)算�����,前端的R接口簡單清晰�����,用戶只需要在加載包之后初始化H2O的線程數(shù)即可��,后續(xù)的計(jì)算����, 如GBM,GLM, DeepLearning算法�����,將會(huì)自動(dòng)被分配到多個(gè)線程以及多個(gè)CPU上�����。詳細(xì)函數(shù)可參見H2O文檔
【5】。
R is connected to the H2O cluster:
H2O cluster uptime: 1 hours 53 minutes
H2O cluster version: 3.8.3.3
H2O cluster name: H2O_started_from_R_patricz_ywj416
H2O cluster total nodes: 1
H2O cluster total memory: 1.55 GB
H2O cluster total cores: 4
H2O cluster allowed cores: 4
H2O cluster healthy: TRUE
H2O Connection ip: localhost
H2O Connection port: 54321
H2O Connection proxy: NA
R Version: R version 3.3.0 (2016-05-03)
顯示并行計(jì)算
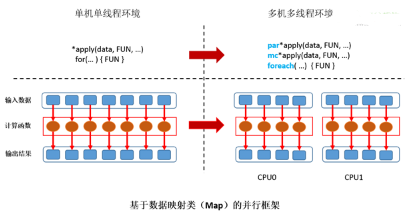
顯式計(jì)算則要求用戶能夠自己處理算例中數(shù)據(jù)劃分,任務(wù)分配��,計(jì)算以及最后的結(jié)果收集�����。因此���,顯式計(jì)算模式對用戶的要求更高�,用戶不僅需要理解自己的算法�,還需要對并行計(jì)算和硬件有一定的理解。值得慶幸的是�����,現(xiàn)有R中的并行計(jì)算框架,如parallel (snow,multicores)�,Rmpi和foreach等采用的是映射式并行模型(Mapping),使用方法簡單清晰�����,極大地簡化了編程復(fù)雜度��。R用戶只需要將現(xiàn)有程序轉(zhuǎn)化為*apply或者for的循環(huán)形式之后���,通過簡單的API替換來實(shí)現(xiàn)并行計(jì)算��。對于更為復(fù)雜的計(jì)算模式�,用戶可以通過重復(fù)映射收集(Map-Reduce)的過程來構(gòu)造���。
下面我們用一元二次方程求解問題來介紹如何利用*apply和foreach做并行化計(jì)算���,完整的代碼(ExplicitParallel.R)【6】可以在GitHuB上下載。首先����,我們給出一個(gè)非向量化的一元二次方程求解函數(shù)�����,其中包括了對幾種特殊情況的處理��,如二次項(xiàng)系數(shù)為零��,二次項(xiàng)以及一次項(xiàng)系數(shù)都為零或者開根號(hào)數(shù)為負(fù)��。我們隨機(jī)生成了3個(gè)大向量分別保存了方程的二次項(xiàng),一次項(xiàng)和常數(shù)項(xiàng)系數(shù)�。
# Not vectorized function
solve.quad.eq <- function(a, b, c) {
# Not validate eqution: a and b are almost ZERO
if(abs(a) < 1e-8 && abs(b) < 1e-8) return(c(NA, NA) )
# Not quad equation
if(abs(a) < 1e-8 && abs(b) > 1e-8) return(c(-c/b, NA))
# No Solution
if(b*b - 4*a*c < 0) return(c(NA,NA))
# Return solutions
x.delta <- sqrt(b*b - 4*a*c)
x1 <- (-b + x.delta)/(2*a)
x2 <- (-b - x.delta)/(2*a)
return(c(x1, x2))
}
# Generate data
len <- 1e6
a <- runif(len, -10, 10)
a[sample(len, 100,replace=TRUE)] <- 0
b <- runif(len, -10, 10)
c <- runif(len, -10, 10)
apply實(shí)現(xiàn)方式: 首先我們來看串行代碼����,下面的代碼利用lapply函數(shù)將方程求解函數(shù)solve.quad.eq映射到每一組輸入數(shù)據(jù)上,返回值保存到列表里��。
# serial code
system.time(
res1.s <- lapply(1:len, FUN = function(x) { solve.quad.eq(a[x], b[x], c[x])})
)
接下來�����,我們利用parallel包里的mcLapply (multicores)來并行化lapply中的計(jì)算����。從API的接口來看�����,除了額外指定所需計(jì)算核心之外���,mcLapply的使用方式和原有的lapply一致,這對用戶來說額外的開發(fā)成本很低�����。mcLapply函數(shù)利用Linux下fork機(jī)制來創(chuàng)建多個(gè)當(dāng)前R進(jìn)程的副本并將輸入索引分配到多個(gè)進(jìn)程上�����,之后每個(gè)進(jìn)程根據(jù)自己的索引進(jìn)行計(jì)算���,最后將其結(jié)果收集合并���。在該例中我們指定了2個(gè)工作進(jìn)程,一個(gè)進(jìn)程計(jì)算1:(len/2), 另一個(gè)計(jì)算(len/2+1):len的數(shù)據(jù)�,最后當(dāng)mcLapply返回時(shí)將兩部分結(jié)果合并到res1.p中。但是�����,由于multicores在底層使用了Linux進(jìn)程創(chuàng)建機(jī)制,所以這個(gè)版本只能在Linux下執(zhí)行�。
# parallel
library(parallel)
# multicores on Linux
system.time(
res1.p <- mclapply(1:len, FUN = function(x) { solve.quad.eq(a[x], b[x], c[x])}, mc.cores = 2)
)
對于非Linux用戶來說,我們可以使用parallel包里的parLapply函數(shù)來實(shí)現(xiàn)并行化����。parLapply函數(shù)支持Windows,Linux���,Mac等不同的平臺(tái)�����,可移植性更好��,但是使用稍微復(fù)雜一點(diǎn)����。在使用parLapply函數(shù)之前���,我們首先需要建立一個(gè)計(jì)算組(cluster)。計(jì)算組是一個(gè)軟件層次的概念��,它指我們需要?jiǎng)?chuàng)建多少個(gè)R工作進(jìn)程(parallel包會(huì)創(chuàng)建新的R工作進(jìn)程��,而非multicores里R父進(jìn)程的副本)來進(jìn)行計(jì)算,理論上計(jì)算組的大小并不受硬件環(huán)境的影響��。比如說我們可以創(chuàng)建一個(gè)大小為1000的計(jì)算組���,即有1000個(gè)R工作進(jìn)程��。 但在實(shí)際使用中���,我們通常會(huì)使用和硬件計(jì)算資源相同數(shù)目的計(jì)算組,即每個(gè)R工作進(jìn)程可以被單獨(dú)映射到一個(gè)計(jì)算內(nèi)核�。如果計(jì)算群組的數(shù)目多于現(xiàn)有硬件資源,那么多個(gè)R工作進(jìn)程將會(huì)共享現(xiàn)有的硬件資源�。如下例我們先用detectCores確定當(dāng)前電腦中的內(nèi)核數(shù)目。值得注意的是detectCores的默認(rèn)返回?cái)?shù)目是超線程數(shù)目而非真正物理內(nèi)核的數(shù)目�����。例如在我的筆記本電腦上有2個(gè)物理核心�����,而每個(gè)物理核心可以模擬兩個(gè)超線程����,所以detectCores()的返回值是4���。 對于很多計(jì)算密集型任務(wù)來說,超線程對性能沒有太大的幫助���,所以使用logical=FALSE參數(shù)來獲得實(shí)際物理內(nèi)核的數(shù)目并創(chuàng)建一個(gè)相同數(shù)目的計(jì)算組����。由于計(jì)算組中的進(jìn)程是全新的R進(jìn)程����,所以在父進(jìn)程中的數(shù)據(jù)和函數(shù)對子進(jìn)程來說并不可見。因此��,我們需要利用clusterExport把計(jì)算所需的數(shù)據(jù)和函數(shù)廣播給計(jì)算組里的所有進(jìn)程���。最后parLapply將計(jì)算平均分配給計(jì)算組里的所有R進(jìn)程�����,然后收集合并結(jié)果。
#Cluster on Windows
cores <- detectCores(logical = FALSE)
cl <- makeCluster(cores)
clusterExport(cl, c('solve.quad.eq', 'a', 'b', 'c'))
system.time(
res1.p <- parLapply(cl, 1:len, function(x) { solve.quad.eq(a[x], b[x], c[x]) })
)
stopCluster(cl)
for實(shí)現(xiàn)方式: for循環(huán)的計(jì)算和*apply形式基本類似�。在如下的串行實(shí)現(xiàn)中,我們提前創(chuàng)建了矩陣用來保存計(jì)算結(jié)果,for循環(huán)內(nèi)部只需要逐一賦值即可���。
# serial code
res2.s <- matrix(0, nrow=len, ncol = 2)
system.time(
for(i in 1:len) {
res2.s[i,] <- solve.quad.eq(a[i], b[i], c[i])
}
)
對于for循環(huán)的并行化���,我們可以使用foreach包里的%dopar% 操作將計(jì)算分配到多個(gè)計(jì)算核心。foreach包提供了一個(gè)軟件層的數(shù)據(jù)映射方法�����,但不包括計(jì)算組的建立�����。因此����,我們需要doParallel或者doMC包來創(chuàng)建計(jì)算組。計(jì)算組的創(chuàng)建和之前基本一樣�����,當(dāng)計(jì)算組建立之后���,我們需要使用registerDoParallel來設(shè)定foreach后端的計(jì)算方式�����。這里我們從數(shù)據(jù)分配方式入手�,我們希望給每個(gè)R工作進(jìn)程分配一段連續(xù)的計(jì)算任務(wù),即將1:len的數(shù)據(jù)均勻分配給每個(gè)R工作進(jìn)程��。假設(shè)我們有兩個(gè)工作進(jìn)程�����,那么進(jìn)程1處理1到len/2的數(shù)據(jù)��,進(jìn)程2處理len/2+1到len的數(shù)據(jù)��。所以在下面的程序中��,我們將向量均勻分配到了計(jì)算組���,每個(gè)進(jìn)程計(jì)算chunk.size大小的聯(lián)系任務(wù)�����。并且在進(jìn)程內(nèi)創(chuàng)建了矩陣來保存結(jié)果��,最終foreach函數(shù)根據(jù).combine指的的rbind函數(shù)將結(jié)果合并����。
# foreach
library(foreach)
library(doParallel)
# Real physical cores in the computer
cores <- detectCores(logical=F)
cl <- makeCluster(cores)
registerDoParallel(cl, cores=cores)
# split data by ourselves
chunk.size <- len/cores
system.time(
res2.p <- foreach(i=1:cores, .combine='rbind') %dopar%
{ # local data for results
res <- matrix(0, nrow=chunk.size, ncol=2)
for(x in ((i-1)*chunk.size+1):(i*chunk.size)) {
res[x - (i-1)*chunk.size,] <- solve.quad.eq(a[x], b[x], c[x])
}
# return local results
res
}
)
stopImplicitCluster()
stopCluster(cl)
最后���,我們在Linux平臺(tái)下使用4個(gè)線程進(jìn)行測試����,以上幾個(gè)版本的并行實(shí)現(xiàn)均可達(dá)到3倍以上的加速比�����。
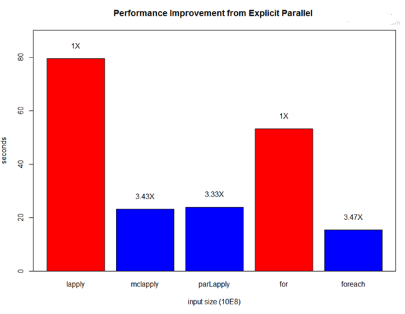
R并行化的挑戰(zhàn)與展望
挑戰(zhàn):
在實(shí)際中�,并行計(jì)算的問題并沒有這么簡單。要并行化R以及整個(gè)生態(tài)環(huán)境的挑戰(zhàn)仍然巨大��。
1���、R是一個(gè)分散的�����,非商業(yè)化的軟件
R并不是由一個(gè)緊湊的組織或者公司開發(fā)的�����,其大部分包是由用戶自己開發(fā)的��。這就意味著很難在軟件架構(gòu)和設(shè)計(jì)上來統(tǒng)一調(diào)整和部署��。一些商業(yè)軟件�,比如Matlab,它的管理維護(hù)開發(fā)就很統(tǒng)一����,架構(gòu)的調(diào)整和局部重構(gòu)相對要容易一些。通過幾個(gè)版本的迭代�����,軟件整體并行化的程度就要高很多��。
2�����、R的底層設(shè)計(jì)仍是單線程����,上層應(yīng)用包依賴性很強(qiáng)
R最初是以單線程模式來設(shè)計(jì)的,意味著許多基礎(chǔ)數(shù)據(jù)結(jié)構(gòu)并不是線程安全的�。所以�,在上層并行算法實(shí)現(xiàn)時(shí)��,很多數(shù)據(jù)結(jié)構(gòu)需要重寫或者調(diào)整���,這也將破壞R本來的一些設(shè)計(jì)模式。另一方面�����,在R中���,包的依賴性很強(qiáng)�,我們假設(shè)使用B包�����,B包調(diào)用了A包���。如果B包首先實(shí)現(xiàn)了多線程���,但是在一段時(shí)間之后A包也做了并行化。那么這時(shí)候就很有可能出現(xiàn)混合并行的情況����,程序就非常有可能出現(xiàn)各種奇怪的錯(cuò)誤(BUG)���,性能也會(huì)大幅度降低。
展望:
未來 R并行化的主要模式是什么樣的��?以下純屬虛構(gòu)��,如果有雷同完全是巧合��。
1���、R將會(huì)更多的依賴于商業(yè)化以及研究機(jī)構(gòu)提供的高性能組件
比如H2O�����,MXNet���,Intel DAAL,這些包都很大程度的利用了并行性帶來的效率提升�,而且有相關(guān)人員長期更新和調(diào)優(yōu)。從本質(zhì)上來說��,軟件的發(fā)展是離不開人力和資金的投入的。
隨著云計(jì)算的興起,數(shù)據(jù)分析即服務(wù)(DAAS:Data Analyst as a Services)以及機(jī)器學(xué)習(xí)即服務(wù)(MLAS: machine learning as a services)的浪潮將會(huì)到來�。 各大服務(wù)商從底層的硬件部署,數(shù)據(jù)庫優(yōu)化到上次的算法優(yōu)化都提供了相應(yīng)的并行化措施�����,比如微軟近期推出了一系列R在云上的產(chǎn)品����,更多信息請參見這篇文章�。因此,未來更多的并行化工作將會(huì)對用戶透明�����,R用戶看到的還是原來的R�����,然而真正的計(jì)算已經(jīng)分布到云端了�����。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情�����;
? 想學(xué)習(xí)CDA考試教材����,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫�,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量��,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營許可證編號(hào):京B2-20210330