對業(yè)務(wù)和用戶的理解,是數(shù)據(jù)挖掘“皇冠上的明珠”
這篇文章不是數(shù)據(jù)挖掘教程,而是讓用研、產(chǎn)品��、運(yùn)營及其它相關(guān)崗位的同學(xué)了解:
數(shù)據(jù)挖掘的特點(diǎn);
數(shù)據(jù)挖掘可以做哪些事情��、有什么應(yīng)用價(jià)值����;
要發(fā)揮數(shù)據(jù)的價(jià)值��,你們應(yīng)該怎么與數(shù)據(jù)挖掘崗協(xié)作�����,你們不可替代的價(jià)值在哪里���。
文章有點(diǎn)長,良心出品����,實(shí)在沒時(shí)間看完全文的同學(xué)可以有選擇地看
數(shù)據(jù)挖掘(Data Mining),核心是從數(shù)據(jù)集合中自動抽取隱藏的有用信息(規(guī)則�����、概念�����、規(guī)律����、模式等),并運(yùn)用到實(shí)際業(yè)務(wù)中�����。自動抽取的過程可以類比成定性研究/數(shù)據(jù)分析中的洞察(insight)�����。兩者的區(qū)別在于數(shù)據(jù)挖掘更依賴機(jī)器和算法����,后者的洞察更依賴人腦。用更貼近生活的例子來說��,數(shù)據(jù)挖掘好比醫(yī)生診斷病人����,醫(yī)生收集病人的各種癥狀之后,通過一定分析���,得出疾病診斷��。但是���,醫(yī)生能根據(jù)醫(yī)學(xué)知識和經(jīng)驗(yàn)反推疾病原因,數(shù)據(jù)挖掘卻很難反推原因,即解決不了“為什么”的問題�。數(shù)據(jù)挖掘涉及統(tǒng)計(jì)學(xué)、人工智能���、機(jī)器學(xué)習(xí)���、高性能計(jì)算、數(shù)據(jù)可視化等等�,涉及的范疇很廣,其中還包括了一部分?jǐn)?shù)據(jù)基礎(chǔ)設(shè)施建設(shè)工作����,比如數(shù)據(jù)的整理、存儲����。這些不是本文的重點(diǎn),有個(gè)印象即可�����。作為茶余飯后跟妹子們聊天的素材也是極好的��。
主流觀點(diǎn)認(rèn)為����,數(shù)據(jù)挖掘與統(tǒng)計(jì)分析密不可分,是統(tǒng)計(jì)技術(shù)的延伸和發(fā)展�����;實(shí)踐中兩者經(jīng)常結(jié)合使用���,一般也不會刻意區(qū)分統(tǒng)計(jì)分析與數(shù)據(jù)挖掘�。想了解“延伸和發(fā)展”什么意思����?數(shù)據(jù)挖掘更注重應(yīng)用,用效果說話����,變量/特征間的關(guān)系不是重點(diǎn),可以是“黑箱”(注:統(tǒng)計(jì)學(xué)習(xí)慣叫變量���,數(shù)據(jù)挖掘習(xí)慣叫特征�����,后面均用特征來指代)����。舉個(gè)栗子,要讓更多的用戶變成付費(fèi)用戶����,傳統(tǒng)統(tǒng)計(jì)分析側(cè)重通過數(shù)據(jù)來了解哪些因素促成了付費(fèi),怎么促進(jìn)付費(fèi)�����;數(shù)據(jù)挖掘可以預(yù)測哪些用戶將會是付費(fèi)用戶����,然后能不能做點(diǎn)什么,讓他們在付費(fèi)的路上走得快一點(diǎn)��、遠(yuǎn)一點(diǎn)���、強(qiáng)一點(diǎn)����。再舉個(gè)栗子��,傳統(tǒng)統(tǒng)計(jì)分析面對圖像識別效果很差�����,數(shù)據(jù)挖掘中的一些新技術(shù)能將準(zhǔn)確率做到接近人眼的水平��。無論是數(shù)據(jù)挖掘還是傳統(tǒng)的統(tǒng)計(jì)分析���,在“目標(biāo)響應(yīng)概率”上達(dá)成了一致���。從宏觀層面來說,目標(biāo)響應(yīng)概率是特定用戶群體����,整體上的概率或可能性,如35%的用戶購買過XXX�����、喜歡某某明星的用戶占57%���。從微觀層面來說,目標(biāo)響應(yīng)概率是具體到單個(gè)用戶的概率�����,如通過邏輯回歸算法,搭建一個(gè)預(yù)測響應(yīng)模型����,預(yù)測每個(gè)用戶在某時(shí)段內(nèi)的流失概率���。數(shù)據(jù)挖掘的一般做法是把樣本劃分為訓(xùn)練集(Training Set)、驗(yàn)證集(Validation Set)��、測試集(Testing Set)�����,在具體實(shí)踐中,有時(shí)候僅劃分為訓(xùn)練集和驗(yàn)證集;用另外時(shí)間窗口的新數(shù)據(jù)來進(jìn)行測試����。通常所說的建模�,是用一部分?jǐn)?shù)據(jù)(通常是60%-70%)來訓(xùn)練模型�����,再用另一部分?jǐn)?shù)據(jù)驗(yàn)證效果�。
(一)傳統(tǒng)的統(tǒng)計(jì)分析�����,基礎(chǔ)是概率論�,需要對數(shù)據(jù)分布做假設(shè)�����,數(shù)據(jù)分布符合要求才能使用某種統(tǒng)計(jì)方法
對變量間的關(guān)系也要做假設(shè)��,確定用某概率函數(shù)來描述變量間的關(guān)系�����,還要檢驗(yàn)參數(shù)的顯著性���。數(shù)據(jù)挖掘中算法會自動尋找變量間的關(guān)系,對于海量雜亂的數(shù)據(jù),數(shù)據(jù)挖掘有優(yōu)勢。簡而言之,統(tǒng)計(jì)分析對數(shù)據(jù)分布有要求,數(shù)據(jù)挖掘對數(shù)據(jù)質(zhì)量非常寬容?����,F(xiàn)在流行“大數(shù)據(jù)”�����,大數(shù)據(jù)的特點(diǎn)是數(shù)據(jù)海量但非結(jié)構(gòu)化(大量的雜亂的稀疏數(shù)據(jù),一眼看過去密密麻麻都是0),自然數(shù)據(jù)挖掘有優(yōu)勢�����。用數(shù)據(jù)挖掘技術(shù)對稀疏數(shù)據(jù)進(jìn)行初步處理后���,還經(jīng)常會用統(tǒng)計(jì)分析來做深度處理�,所以說兩者密不可分���。
(二)數(shù)據(jù)挖掘在預(yù)測時(shí)重點(diǎn)關(guān)注預(yù)測結(jié)果���,變量間的關(guān)系可以是“黑箱”
這雖然能解決問題,但不利于解釋業(yè)務(wù)�,有些情況下必須選用“退而求其次”的方法,把黑箱里面的情況搞清楚�����。比如為防范信用卡盜刷而建的風(fēng)控模型��,會用決策樹做����,便于向用戶/騙子解釋因?yàn)槭裁辞闆r被攔截��。大家不要低估騙子的心理素質(zhì)�,如果說不出個(gè)所以然����,嘿嘿��,你跟騙子耗不起這個(gè)糾纏的時(shí)間。所以,實(shí)際業(yè)務(wù)中����,沒有最牛的算法�����,只有最適合的算法。
(三)傳統(tǒng)做統(tǒng)計(jì)分析時(shí)�����,分析人員會先做假設(shè)和判斷���,再通過數(shù)據(jù)驗(yàn)證假設(shè)是否成立
人腦在建立假設(shè)時(shí)起了不可替代的作用����。而算法自動尋找數(shù)據(jù)規(guī)律時(shí),可能會過擬合��,造成模型不穩(wěn)定�����,后續(xù)的應(yīng)用效果比較差����。下面用三張圖來說明過擬合(圖片來自網(wǎng)絡(luò)學(xué)習(xí)資料):
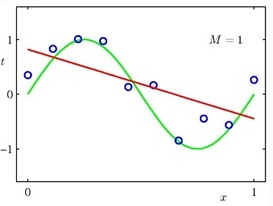
圖1,藍(lán)色空心小點(diǎn)代表真實(shí)的數(shù)據(jù)點(diǎn)��,綠線代表我們想去擬合的真實(shí)曲線�,當(dāng)我們用一維曲線(直線)去擬合時(shí),得到紅線����,從圖上就能直觀看出擬合效果不好。
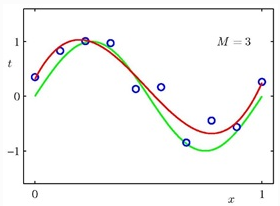
圖2���,用三維曲線去擬合時(shí)�,得到的效果不錯(cuò)�����,紅線穿過了大多數(shù)藍(lán)點(diǎn)����。
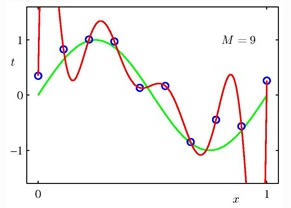
圖3,用九維曲線去擬合時(shí)�����,哇塞��,完美����!紅線穿過了每一個(gè)藍(lán)點(diǎn)。但是這樣的模型已經(jīng)嚴(yán)重偏離了綠線, 對新數(shù)據(jù)的預(yù)測效果會很差�����。此時(shí)紅線就是過擬合了�。所以,不能光追求數(shù)據(jù)挖掘時(shí)的一些客觀指標(biāo)��,能解決實(shí)際問題的模型才是好模型。
效能���,更高效地解決問題��,目前提高數(shù)據(jù)挖掘效能有兩條不同的路����。
(一)從算法里挖潛能
學(xué)術(shù)界尋找更強(qiáng)的算法���,工業(yè)界玩弱算法疊加���。傳統(tǒng)的算法改進(jìn)路線是人工生成特征,但效果有限(會伴生“高維”����、“稀疏”等問題,計(jì)算困難)��,特別是圖像識別��、自然語言處理等問題��,人工來做特征工程非常困難;學(xué)術(shù)界發(fā)展出更強(qiáng)的新算法���,解決特定類別問題。工業(yè)界多用取巧的方式���,不斷嘗試算法疊加�,發(fā)現(xiàn)效果更好的解決方法���。舉個(gè)栗子:GBDT(由多棵決策樹組成的迭代決策樹)+ X(LR�����、FM����、……)��,疊加后投票(賦予權(quán)重)���。同時(shí)�����,工業(yè)界還要考慮計(jì)算資源問題�����,怎樣的算法“算得快”也很重要��。
(二)通過特征選擇提高效能
特征太少威脅模型的穩(wěn)定性�,特征太多也影響模型穩(wěn)定性且增加復(fù)雜度,用白話來說就是特征數(shù)量沒控制好�,會造成建模成本高、模型應(yīng)用效果差����。控制特征數(shù)量涉及到特征的選擇��,特征選擇源于洞察����,依賴人腦,尤其在無監(jiān)督學(xué)習(xí)的情況下����,更需要人腦對業(yè)務(wù)的理解和判斷作為基礎(chǔ)。(注�,無監(jiān)督學(xué)習(xí)的一個(gè)例子是用戶聚類��,得到的用戶類別沒有客觀指標(biāo)可驗(yàn)證����。)
(一)目標(biāo)用戶的預(yù)測(響應(yīng)��、分類)
如預(yù)測用戶在某個(gè)時(shí)間段內(nèi)流失概率的流失預(yù)警模型�����,用第N月的行為數(shù)據(jù)����,預(yù)測用戶在第N+1月和第N+2月的流失情況���。通過預(yù)測得到即將流失的用戶名單后����,針對其中的高價(jià)值用戶����,運(yùn)營有時(shí)間窗口來采取措施進(jìn)行挽留。同理還可以建付費(fèi)預(yù)測模型���、續(xù)費(fèi)預(yù)測模型�、運(yùn)營活動響應(yīng)模型。這些模型的本質(zhì)是預(yù)測單個(gè)用戶的響應(yīng)概率(Probability)��。
(二)用戶分層精度
介于上述針對單個(gè)用戶的精細(xì)化操作與針對全體用戶的粗放操作之間�����,是一種折衷過渡模型�。與預(yù)測單個(gè)用戶的情況相比,分層模型不需要大量資源投入���,但它比粗放操作精細(xì)��,提高了業(yè)務(wù)效率���。用戶運(yùn)營分層模型、用戶分層進(jìn)化圖����、向不同群體提供不同說辭和服務(wù),均是業(yè)務(wù)應(yīng)用場景�。用戶聚類、群體用戶畫像也算“用戶分層”�����,這種分層,僅僅是不同類別的區(qū)分�����,類之間沒有遞進(jìn)關(guān)系��。
(三)用戶路徑分析能給產(chǎn)品經(jīng)理�、用戶體驗(yàn)人員、運(yùn)營這三大類崗位的同學(xué)帶來價(jià)值
如通過分析用戶訪問路徑來優(yōu)化網(wǎng)頁設(shè)計(jì)�����、進(jìn)行改版��;提煉出特定用戶群體的主流路徑����;預(yù)測用戶可能訪問的下一個(gè)頁面等��。漏斗模型是很常見的“特殊”用戶路徑分析模型�,依賴分析思路和業(yè)務(wù)驅(qū)動。如支付轉(zhuǎn)化率分析�����,每個(gè)節(jié)點(diǎn)均對應(yīng)不同的業(yè)務(wù)涵義。
(四)交叉銷售與個(gè)性化推薦
用戶來了之后�,我們總是希望能挖掘用戶潛在需求,一次性將更多的商品或服務(wù)賣給他/她���,尤其是依賴流量的產(chǎn)品�����,流量獲取成本高的話�����,用戶挖掘非常重要���。通過用戶行為數(shù)據(jù)挖掘,找出有明顯關(guān)聯(lián)的商品組合�,“打包”銷售,或進(jìn)行個(gè)性化推薦����,均能促進(jìn)業(yè)務(wù)目標(biāo)。目前���,Amazon(亞馬遜)35%的購買來自推薦�����,LinkedIn(領(lǐng)英)50%的關(guān)聯(lián)是通過推薦匹配��,時(shí)尚網(wǎng)站“Stitch Fix 100%的購買都是由推薦產(chǎn)生”���。數(shù)據(jù)挖潛對產(chǎn)品會越來越重要��。當(dāng)然�,數(shù)據(jù)不是萬能的�,個(gè)性化推薦的前、后環(huán)節(jié)均基于對業(yè)務(wù)和用戶的理解����。
(五)信息質(zhì)量優(yōu)化
信息質(zhì)量模型的特點(diǎn)是:最初評價(jià)目標(biāo)對象“質(zhì)量好壞”時(shí),依賴專家和用戶調(diào)研的結(jié)果綜合進(jìn)行評定���。之后將評定緯度和評定結(jié)果交給機(jī)器�����,最終形成可用的模型���。如商品介紹頁質(zhì)量優(yōu)化、網(wǎng)絡(luò)店鋪質(zhì)量優(yōu)化���、論壇發(fā)帖質(zhì)量優(yōu)化等�����。
(六)文本挖掘想象一下詞云
這就是文本挖掘的一種形式�����。另外文本挖掘還能分析情感����、判斷用戶特征、做網(wǎng)絡(luò)輿情監(jiān)控����、做傳播分析等���。當(dāng)你需要一些信息來輔助決策的時(shí)候���,想想能否從文本里面挖掘出有價(jià)值的內(nèi)容��。
6.重點(diǎn)來了
前面說了那么多,最終回到本文的核心觀點(diǎn),因受現(xiàn)實(shí)條件制約(數(shù)據(jù)質(zhì)量�、資源投入)��,數(shù)據(jù)挖掘非常依賴對業(yè)務(wù)的理解和把控���。對業(yè)務(wù)和用戶的理解用于指導(dǎo)建模����,對業(yè)務(wù)的把控則是產(chǎn)品想要打造的品牌/體驗(yàn),是產(chǎn)品想把用戶過去的方向�,也是商業(yè)邏輯問題。
理論上通過A/B測試可以完全由數(shù)據(jù)驅(qū)動來追逐指標(biāo)�����,這是“短期利益”�����,但現(xiàn)實(shí)中我們還關(guān)心產(chǎn)品的“長期利益”���,在短期和長期之間尋找一個(gè)平衡點(diǎn)���。對業(yè)務(wù)/用戶的理解和把握,來自產(chǎn)品經(jīng)理�����、來自用戶研究���、來自運(yùn)營���、也可能來自其它崗位�����。所以����,這些崗位的同學(xué)必須知道怎么跟數(shù)據(jù)挖掘崗協(xié)作�����,怎么推動模型落地并有良好的應(yīng)用����。部分用研同學(xué)因?yàn)樽詭?a href='/map/tongjifenxi/' style='color:#000;font-size:inherit;'>統(tǒng)計(jì)分析技能,已能搭建比較理想的模型���;產(chǎn)品和運(yùn)營(也包括用研)�����,應(yīng)該做好數(shù)據(jù)挖掘前后兩端的工作���,這事跟你們不是沒有關(guān)系。數(shù)據(jù)輔助決策這件事會越來越滲透到產(chǎn)品開發(fā)和商業(yè)流程中�;開發(fā)���、產(chǎn)品����、市場、商務(wù)等崗位會越來越有“數(shù)據(jù)感”����,能進(jìn)行自助分析。最終��,數(shù)據(jù)是為商業(yè)邏輯服務(wù)的����。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情���;
? 想學(xué)習(xí)CDA考試教材��,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫����,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330