SPSS聚類分析經(jīng)典案例分享
這篇文章的案例過程涉及到spss層次聚類中的Q型聚類和R型聚類�,單因素方差分析,Means過程等��,是一個很不錯的多種分析方法聯(lián)合使用的 聚類分析案例��。
案例數(shù)據(jù)源:
有20種12盎司啤酒成分和價格的數(shù)據(jù)����,變量包括啤酒名稱���、熱量����、鈉含量、酒精含量��、價格�����。數(shù)據(jù)來自《SPSS for Windows 統(tǒng)計分析》data11-03�����。
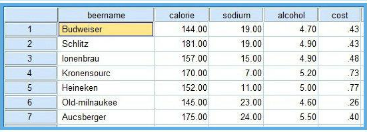
【一】問題一:選擇那些變量進行聚類��?——采用“R型聚類”
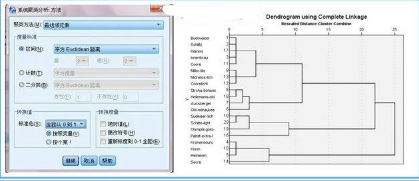
1����、如何篩選聚類變量?現(xiàn)在我們有4個變量用來對啤酒分類����,是否有必要將4個變量都納入作為分類變量呢?熱量����、鈉含量、酒精含量這3個指標是要通過化驗員的辛苦努力來測定�,而且還有花費不少成本,如果都納入分析的話���,豈不太麻煩太浪費�?所以�����,有必要對4個變量進行降維處理��,這里采用spss R型聚類(變量聚類)�,對4個變量進行降維處理。輸出“相似性矩陣”有助于我們理解降維的過程���。
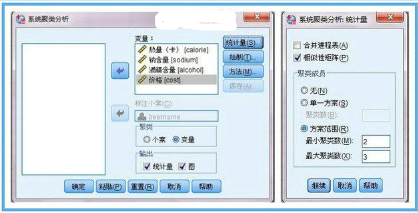
2���、4個分類變量量綱各自不同,這一次我們先確定用相似性來測度��,度量標準選用pearson系數(shù)��,聚類方法選最遠元素��,此時,涉及到相關����,4個變量可不用標準化處理,將來的相似性矩陣里的數(shù)字為相關系數(shù)����。若果有某兩個變量的相關系數(shù)接近1或-1,說明兩個變量可互相替代�。
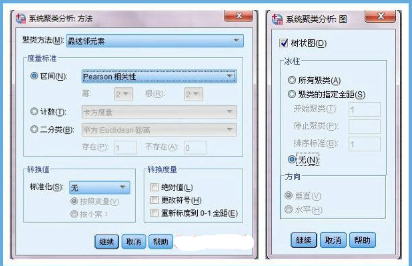
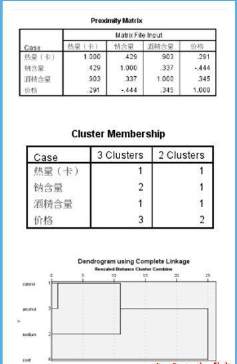
3、只輸出“樹狀圖”就可以了���,個人覺得冰柱圖很復雜����,看起來沒有樹狀圖清晰明了���。從proximity matrix表中可以看出熱量和酒精含量兩個變量相關系數(shù)0.903��,最大��,二者選其一即可����,沒有必要都作為聚類變量,導致成本增加����。至于熱量和酒精含量選擇哪一個作為典型指標來代替原來的兩個變量���,可以根據(jù)專業(yè)知識或測定的難易程度決定��。(與因子分析不同��,是完全踢掉其中一個變量以達到降維的目的�。)這里選用酒精含量���,至此����,確定出用于聚類的變量為:酒精含量��,鈉含量����,價格。
【二】問題二:20中啤酒能分為幾類���?——采用“Q型聚類”
1���、現(xiàn)在開始對20中啤酒進行聚類�����。開始不確定應該分為幾類���,暫時用一個3-5類范圍來試探。Q型聚類要求量綱相同���,所以我們需要對數(shù)據(jù)標準化�����,這一回用歐式距離平方進行測度����。
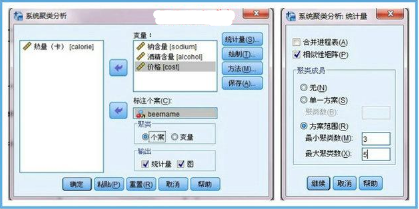
2�����、主要通過樹狀圖和冰柱圖來理解類別。最終是分為4類還是3類���,這是個復雜的過程�,需要專業(yè)知識和最初的目的來識別�。我這里試著確定分為4類。選擇“保存”�����,則在數(shù)據(jù)區(qū)域內會自動生成聚類結果����。
【三】問題三:用于聚類的變量對聚類過程��、結果又貢獻么�����,有用么��?——采用“單因素方差分析”
1����、聚類分析除了對類別的確定需討論外,還有一個比較關鍵的問題就是分類變量到底對聚類有沒有作用有沒有貢獻,如果有個別變量對分類沒有作用的話��,應該剔除�����。
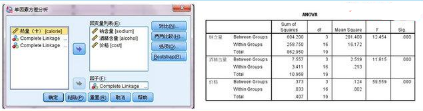
2��、這個過程一般用 單因素方差分析來判斷����。注意此時,因子變量選擇聚為4類的結果��,而將三個聚類變量作為因變量處理�����。方差分析結果顯示�,三個聚類變量sig值均極顯著,我們用于分類的3個變量對分類有作用����,可以使用,作為聚類變量是比較合理的����。
【四】問題四:聚類結果的解釋����?——采用”均值比較描述統(tǒng)計“
1�、聚類分析最后一步,也是最為困難的就是對分出的各類進行定義解釋�����,描述各類的特征�,即各類別特征描述。這需要專業(yè)知識作為基礎并結合分析目的才能得出���。
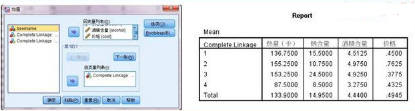
2、我們可以采用spss的means均值比較過程�,或者excel的透視表功能對各類的各個指標進行描述。其中�����,report報表用于描述聚類結果����。對各類指標的比較來初步定義類別,主要根據(jù)專業(yè)知識來判定。這里到此為止�。
CDA數(shù)據(jù)分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學習CDA考試教材,點擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫�,點擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330