你應(yīng)該了解的數(shù)據(jù)分析入門知識(shí)
我特別不喜歡裝的產(chǎn)品經(jīng)理��,看文章也一樣不喜歡華而不實(shí)的�。所以督促自己寫文章時(shí)�,把懂的、經(jīng)歷過的能細(xì)就寫的盡量詳細(xì)�����;不懂的就去學(xué)�,然后把整理的筆記分享出來,數(shù)據(jù)分析方面我涉入不多�,內(nèi)容由于缺少實(shí)戰(zhàn)經(jīng)驗(yàn)��,會(huì)比較基礎(chǔ)和理論,希望同樣對(duì)你有幫助�����。
1��、明確分析的目標(biāo)
做數(shù)據(jù)分析����,必須要有一個(gè)明確的目的,知道自己為什么要做數(shù)據(jù)分析��,想要達(dá)到什么效果�����。比如:為了評(píng)估產(chǎn)品改版后的效果比之前有所提升���;或通過數(shù)據(jù)分析,找到產(chǎn)品迭代的方向等�。
明確了數(shù)據(jù)分析的目的,接下來需要確定應(yīng)該收集的數(shù)據(jù)都有哪些�。
2����、收集數(shù)據(jù)的方法
說到收集數(shù)據(jù)�,首先要做好數(shù)據(jù)埋點(diǎn)。
所謂“埋點(diǎn)”��,個(gè)人理解就是在正常的功能邏輯中添加統(tǒng)計(jì)代碼����,將自己需要的數(shù)據(jù)統(tǒng)計(jì)出來。
目前主流的數(shù)據(jù)埋點(diǎn)方式有兩種:
第一種:自己研發(fā)�。開發(fā)時(shí)加入統(tǒng)計(jì)代碼,并搭建自己的數(shù)據(jù)查詢系統(tǒng)�。
第二種:利用第三方統(tǒng)計(jì)工具。
常見的第三方統(tǒng)計(jì)工具有:
網(wǎng)站分析工具
Alexa����、中國網(wǎng)站排名、網(wǎng)絡(luò)媒體排名(iwebchoice)�、Google Analytics、百度統(tǒng)計(jì)
移動(dòng)應(yīng)用分析工具
Flurry�、Google Analytics、友盟�、TalkingData、Crashlytics
不同產(chǎn)品���,不同目的���,需要的支持?jǐn)?shù)據(jù)不同��,確定好數(shù)據(jù)指標(biāo)后���,選擇適合自己公司的方式來收集相應(yīng)數(shù)據(jù)。
3. 產(chǎn)品的基本數(shù)據(jù)指標(biāo)
新增:新用戶增加的數(shù)量和速度�。如:日新增、月新增等���。
活躍:有多少人正在使用產(chǎn)品�。如日活躍(DAU)��、月活躍(MAU)等����。用戶的活躍數(shù)越多��,越有可能為產(chǎn)品帶來價(jià)值��。
留存率:用戶會(huì)在多長時(shí)間內(nèi)使用產(chǎn)品�����。如:次日留存率、周留存率等����。
傳播:平均每位老用戶會(huì)帶來幾位新用戶。
流失率:一段時(shí)間內(nèi)流失的用戶�����,占這段時(shí)間內(nèi)活躍用戶數(shù)的比例�。
4. 常見的數(shù)據(jù)分析法和模型
這里主要科普下漏斗分析法和AARRR分析模型。
漏斗分析法
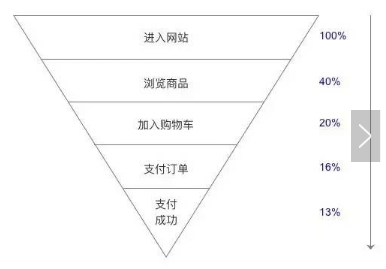
用來分析從潛在用戶到最終用戶這個(gè)過程中用戶數(shù)量的變化趨勢��,從而尋找到最佳的優(yōu)化空間�����,這個(gè)方法被普遍用于產(chǎn)品各個(gè)關(guān)鍵流程的分析中��。
比如���,這個(gè)例子是分析從用戶進(jìn)入網(wǎng)站到最終購買商品的變化趨勢��。
從用戶進(jìn)入網(wǎng)站到瀏覽商品頁面���,轉(zhuǎn)化率是40%���;瀏覽商品到加入購物車轉(zhuǎn)化率是20%等,那要找出哪個(gè)環(huán)節(jié)的轉(zhuǎn)化率最低�����,我們需要有對(duì)比數(shù)據(jù)�。
比如第一個(gè),進(jìn)入網(wǎng)站到瀏覽商品���,如果同行業(yè)水平的轉(zhuǎn)化率是45%�����,而我們只有40%�,那說明這個(gè)過程�����,沒有達(dá)到行業(yè)平均水平��,我們就需要分析具體原因在哪里�,再有針對(duì)性的去優(yōu)化和改善。
當(dāng)然�,上面這是我們設(shè)計(jì)的一種理想化的漏斗模型,數(shù)據(jù)有可能是經(jīng)過匯總后得出的��。而真實(shí)的用戶行為往往可能并不是按照這個(gè)簡單流程來的���。此時(shí)需要分析用戶為什么要經(jīng)過那么復(fù)雜的路徑來達(dá)到最終目的����,思考這中間有沒有可以優(yōu)化的空間����。
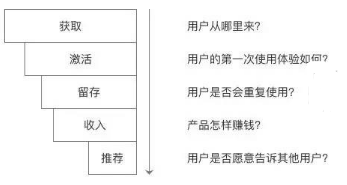
AARRR模型
這個(gè)是所有的產(chǎn)品經(jīng)理都必須要掌握的一個(gè)數(shù)據(jù)分析模型。
AARRR(Acquisition���、Activation�����、Retention�����、Revenue��、Refer)是硅谷的一個(gè)風(fēng)險(xiǎn)投資人戴維 · 麥克魯爾在2008年時(shí)創(chuàng)建的��,分別是指獲取��、激活�����、留存���、收入和推薦��。
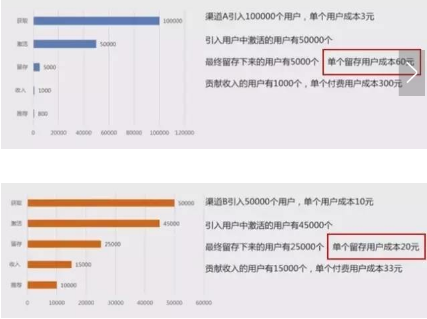
舉個(gè)例子��,用AARRR模型來衡量一個(gè)渠道的好壞�。
如果單從數(shù)據(jù)表面來看��,A渠道會(huì)更劃算�,但實(shí)際這種結(jié)論是有問題的,用AARRR模型具體分析如下:
渠道A的單個(gè)留存用戶成本是60元����,單個(gè)付費(fèi)用戶成本是300元����;而渠道B的單個(gè)留存用戶成本是20元��,單個(gè)付費(fèi)用戶成本是33元���,這樣對(duì)比下來,明顯B渠道的優(yōu)勢遠(yuǎn)遠(yuǎn)大于A渠道��。
交叉分析法
通常是把縱向?qū)Ρ群蜋M向?qū)Ρ染C合起來����,對(duì)數(shù)據(jù)進(jìn)行多角度的結(jié)合分析����。
舉個(gè)例子:
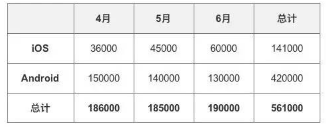
a. 交叉分析角度:客戶端+時(shí)間
從這個(gè)數(shù)據(jù)中,可以看出iOS端每個(gè)月的用戶數(shù)在增加����,而Android端在降低,總體數(shù)據(jù)沒有增長的主要原因在于Android端數(shù)據(jù)下降所導(dǎo)致的�����。
那接下來要分析下為什么Android端二季度新增用戶數(shù)據(jù)在下降呢?一般這個(gè)時(shí)候�����,會(huì)加入渠道維度����。
b. 交叉分析角度:客戶端+時(shí)間+渠道
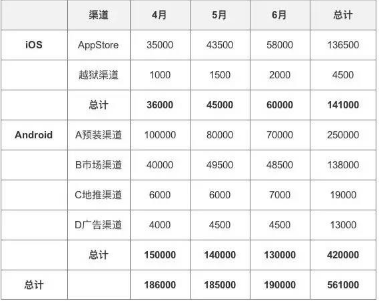
從這個(gè)數(shù)據(jù)中可以看出����,Android端A預(yù)裝渠道占比比較高,而且呈現(xiàn)下降趨勢��,其他渠道的變化并不明顯���。
因此可以得出結(jié)論:Android端在二季度新增用戶降低主要是由于A預(yù)裝渠道降低所導(dǎo)致的�。
所以說��,交叉分析的主要作用��,是從多個(gè)角度細(xì)分?jǐn)?shù)據(jù)����,從中發(fā)現(xiàn)數(shù)據(jù)變化的具體原因。
5. 如何驗(yàn)證產(chǎn)品新功能的效果
驗(yàn)證產(chǎn)品新功能的效果需要同時(shí)從這幾方面入手:
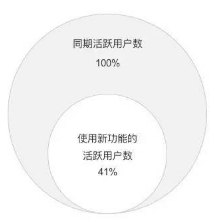
a. 新功能是否受歡迎����?
衡量指標(biāo):活躍比例�。即:使用新功能的活躍用戶數(shù)/同期活躍用戶數(shù)����。
使用人數(shù)的多少還會(huì)受該功能外的很多因素影響,千萬不可只憑這一指標(biāo)判斷功能好壞���,一定要結(jié)合下面的其他方面綜合評(píng)估�。
b. 用戶是否會(huì)重復(fù)使用�����?
衡量指標(biāo):重復(fù)使用比例�。即:第N天回訪的繼續(xù)使用新功能的用戶數(shù)/第一天使用新功能的用戶數(shù)����。
c. 對(duì)流程轉(zhuǎn)化率的優(yōu)化效果如何����?
衡量指標(biāo):轉(zhuǎn)化率和完成率����。轉(zhuǎn)化率即:走到下一步的用戶數(shù)/上一步的用戶數(shù)。完成率即:完成該功能的用戶數(shù)/走第一步的用戶數(shù)�����。
這個(gè)過程中�����,轉(zhuǎn)化率和完成率可以使用(上)篇中提到的漏斗分析法進(jìn)行分析。
d. 對(duì)留存的影響?
衡量指標(biāo):留存率����。用戶在初始時(shí)間后第N天的回訪比例�����,即:N日留存率��。常用指標(biāo)有:次日留存率����、7日留存率、21日留存率��、30日留存率等���。
e. 用戶怎樣使用新功能�?
真實(shí)用戶行為軌跡往往比我們設(shè)想的使用路徑要復(fù)雜的多���,如果使用的數(shù)據(jù)監(jiān)測平臺(tái)可以看到相關(guān)數(shù)據(jù)���,能引起我們的反思���,為什么他們會(huì)這么走��,有沒有更簡便的流程�,以幫助我們作出優(yōu)化決策�。
6. 如何發(fā)現(xiàn)產(chǎn)品改進(jìn)的關(guān)鍵點(diǎn)
產(chǎn)品改進(jìn)的關(guān)鍵點(diǎn),是藏在用戶的行為中��。
想要找到這些關(guān)鍵點(diǎn)�,除了通過用戶調(diào)研�����、訪談等切實(shí)的洞察用戶外�,在產(chǎn)品中設(shè)置相關(guān)數(shù)據(jù)埋點(diǎn)記錄用戶的行為����,觀察其行為軌跡,不能完全替代洞察用戶的行為�����,不過也可以有助于決策產(chǎn)品改進(jìn)點(diǎn)����。
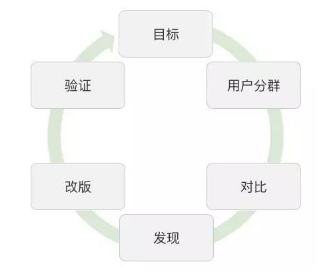
操作步驟:
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情����;
? 想學(xué)習(xí)CDA考試教材,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫��,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量��,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情�;














 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營許可證編號(hào):京B2-20210330