數(shù)據(jù)挖掘系列樸素貝葉斯分類(lèi)算法原理與實(shí)踐
隔了很久沒(méi)有寫(xiě)數(shù)據(jù)挖掘系列的文章了��,今天介紹一下樸素貝葉斯分類(lèi)算法�,講一下基本原理�,再以文本分類(lèi)實(shí)踐。
一個(gè)簡(jiǎn)單的例子
樸素貝葉斯算法是一個(gè)典型的統(tǒng)計(jì)學(xué)習(xí)方法���,主要理論基礎(chǔ)就是一個(gè)貝葉斯公式��,貝葉斯公式的基本定義如下:
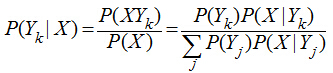
這個(gè)公式雖然看上去簡(jiǎn)單�,但它卻能總結(jié)歷史����,預(yù)知未來(lái)����。公式的右邊是總結(jié)歷史���,公式的左邊是預(yù)知未來(lái)����,如果把Y看出類(lèi)別�����,X看出特征�����,P(Yk|X)就是在已知特征X的情況下求Yk類(lèi)別的概率����,而對(duì)P(Yk|X)的計(jì)算又全部轉(zhuǎn)化到類(lèi)別Yk的特征分布上來(lái)����。
舉個(gè)例子����,大學(xué)的時(shí)候����,某男生經(jīng)常去圖書(shū)室晚自習(xí),發(fā)現(xiàn)他喜歡的那個(gè)女生也常去那個(gè)自習(xí)室�,心中竊喜,于是每天買(mǎi)點(diǎn)好吃點(diǎn)在那個(gè)自習(xí)室蹲點(diǎn)等她來(lái)��,可是人家女生不一定每天都來(lái)���,眼看天氣漸漸炎熱�,圖書(shū)館又不開(kāi)空調(diào)���,如果那個(gè)女生沒(méi)有去自修室��,該男生也就不去�,每次男生鼓足勇氣說(shuō):“嘿��,你明天還來(lái)不����?”,“啊��,不知道�����,看情況”�����。然后該男生每天就把她去自習(xí)室與否以及一些其他情況做一下記錄��,用Y表示該女生是否去自習(xí)室��,即Y={去�,不去}�����,X是跟去自修室有關(guān)聯(lián)的一系列條件�����,比如當(dāng)天上了哪門(mén)主課�,蹲點(diǎn)統(tǒng)計(jì)了一段時(shí)間后���,該男生打算今天不再蹲點(diǎn)�����,而是先預(yù)測(cè)一下她會(huì)不會(huì)去����,現(xiàn)在已經(jīng)知道了今天上了常微分方法這么主課,于是計(jì)算P(Y=去|常微分方程)與P(Y=不去|常微分方程)�,看哪個(gè)概率大,如果P(Y=去|常微分方程) >P(Y=不去|常微分方程)����,那這個(gè)男生不管多熱都屁顛屁顛去自習(xí)室了,否則不就去自習(xí)室受罪了��。P(Y=去|常微分方程)的計(jì)算可以轉(zhuǎn)為計(jì)算以前她去的情況下����,那天主課是常微分的概率P(常微分方程|Y=去),注意公式右邊的分母對(duì)每個(gè)類(lèi)別(去/不去)都是一樣的���,所以計(jì)算的時(shí)候忽略掉分母�����,這樣雖然得到的概率值已經(jīng)不再是0~1之間��,但是其大小還是能選擇類(lèi)別����。
后來(lái)他發(fā)現(xiàn)還有一些其他條件可以挖,比如當(dāng)天星期幾�、當(dāng)天的天氣,以及上一次與她在自修室的氣氛����,統(tǒng)計(jì)了一段時(shí)間后,該男子一計(jì)算��,發(fā)現(xiàn)不好算了�,因?yàn)榭偨Y(jié)歷史的公式:
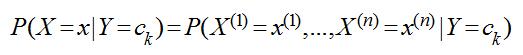
這里n=3,x(1)表示主課���,x(2)表示天氣�����,x(3)表示星期幾��,x(4)表示氣氛���,Y仍然是{去�,不去}��,現(xiàn)在主課有8門(mén)��,天氣有晴�、雨��、陰三種�����、氣氛有A+,A,B+,B,C五種����,那么總共需要估計(jì)的參數(shù)有8*3*7*5*2=1680個(gè),每天只能收集到一條數(shù)據(jù)��,那么等湊齊1680條數(shù)據(jù)大學(xué)都畢業(yè)了,男生打呼不妙�,于是做了一個(gè)獨(dú)立性假設(shè),假設(shè)這些影響她去自習(xí)室的原因是獨(dú)立互不相關(guān)的�,于是
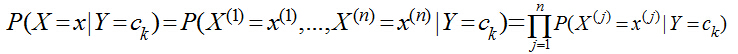
有了這個(gè)獨(dú)立假設(shè)后,需要估計(jì)的參數(shù)就變?yōu)椋?8+3+7+5)*2 = 46個(gè)了�����,而且每天收集的一條數(shù)據(jù)�,可以提供4個(gè)參數(shù),這樣該男生就預(yù)測(cè)越來(lái)越準(zhǔn)了��。
樸素貝葉斯分類(lèi)器
講了上面的小故事����,我們來(lái)樸素貝葉斯分類(lèi)器的表示形式:
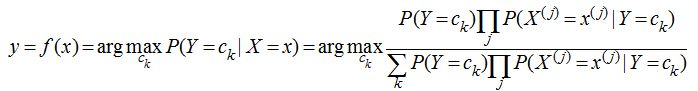
當(dāng)特征為為x時(shí),計(jì)算所有類(lèi)別的條件概率���,選取條件概率最大的類(lèi)別作為待分類(lèi)的類(lèi)別�����。由于上公式的分母對(duì)每個(gè)類(lèi)別都是一樣的�,因此計(jì)算時(shí)可以不考慮分母��,即
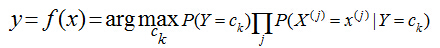
樸素貝葉斯的樸素體現(xiàn)在其對(duì)各個(gè)條件的獨(dú)立性假設(shè)上,加上獨(dú)立假設(shè)后�,大大減少了參數(shù)假設(shè)空間?���! ?/span>
在文本分類(lèi)上的應(yīng)用
文本分類(lèi)的應(yīng)用很多,比如垃圾郵件和垃圾短信的過(guò)濾就是一個(gè)2分類(lèi)問(wèn)題����,新聞分類(lèi)��、文本情感分析等都可以看成是文本分類(lèi)問(wèn)題����,分類(lèi)問(wèn)題由兩步組成:訓(xùn)練和預(yù)測(cè),要建立一個(gè)分類(lèi)模型�����,至少需要有一個(gè)訓(xùn)練數(shù)據(jù)集���。貝葉斯模型可以很自然地應(yīng)用到文本分類(lèi)上:現(xiàn)在有一篇文檔d(Document)���,判斷它屬于哪個(gè)類(lèi)別ck�,只需要計(jì)算文檔d屬于哪一個(gè)類(lèi)別的概率最大:
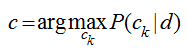
在分類(lèi)問(wèn)題中,我們并不是把所有的特征都用上�����,對(duì)一篇文檔d�����,我們只用其中的部分特征詞項(xiàng)<t1,t2,...,tnd>(nd表示d中的總詞條數(shù)目)�����,因?yàn)楹芏嘣~項(xiàng)對(duì)分類(lèi)是沒(méi)有價(jià)值的����,比如一些停用詞“的,是,在”在每個(gè)類(lèi)別中都會(huì)出現(xiàn)���,這個(gè)詞項(xiàng)還會(huì)模糊分類(lèi)的決策面���,關(guān)于特征詞的選取,我的這篇文章有介紹����。用特征詞項(xiàng)表示文檔后��,計(jì)算文檔d的類(lèi)別轉(zhuǎn)化為:
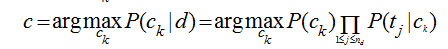
注意P(Ck|d)只是正比于后面那部分公式�,完整的計(jì)算還有一個(gè)分母���,但我們前面討論了����,對(duì)每個(gè)類(lèi)別而已分母都是一樣的�����,于是在我們只需要計(jì)算分子就能夠進(jìn)行分類(lèi)了����。實(shí)際的計(jì)算過(guò)程中���,多個(gè)概率值P(tj|ck)的連乘很容易下溢出為0���,因此轉(zhuǎn)化為對(duì)數(shù)計(jì)算,連乘就變成了累加:
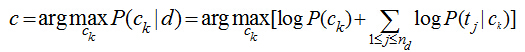
我們只需要從訓(xùn)練數(shù)據(jù)集中�,計(jì)算每一個(gè)類(lèi)別的出現(xiàn)概率P(ck)和每一個(gè)類(lèi)別中各個(gè)特征詞項(xiàng)的概率P(tj|ck),而這些概率值的計(jì)算都采用最大似然估計(jì)���,說(shuō)到底就是統(tǒng)計(jì)每個(gè)詞在各個(gè)類(lèi)別中出現(xiàn)的次數(shù)和各個(gè)類(lèi)別的文檔的數(shù)目:
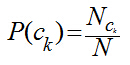
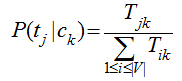
其中��,Nck表示訓(xùn)練集中ck類(lèi)文檔的數(shù)目��,N訓(xùn)練集中文檔總數(shù)���;Tjk表示詞項(xiàng)tj在類(lèi)別ck中出現(xiàn)的次數(shù)�,V是所有類(lèi)別的詞項(xiàng)集合���。這里對(duì)詞的位置作了獨(dú)立性假設(shè)�,即兩個(gè)詞只要它們出現(xiàn)的次數(shù)一樣����,那不管它們?cè)谖臋n的出現(xiàn)位置,它們大概率值P(tj|ck)都是一樣�����,這個(gè)位置獨(dú)立性假設(shè)與現(xiàn)實(shí)很不相符����,比如“放馬屁”跟“馬放屁”表述的是不同的內(nèi)容,但實(shí)踐發(fā)現(xiàn)�,位置獨(dú)立性假設(shè)得到的模型準(zhǔn)確率并不低�����,因?yàn)榇蠖鄶?shù)文本分類(lèi)都是靠詞的差異來(lái)區(qū)分��,而不是詞的位置��,如果考慮詞的位置���,那么問(wèn)題將表達(dá)相當(dāng)復(fù)雜,以至于我們無(wú)從下手�。
然后需要注意的一個(gè)問(wèn)題是ti可能沒(méi)有出現(xiàn)在ck類(lèi)別的訓(xùn)練集,卻出現(xiàn)在ck類(lèi)別的測(cè)試集合中����,這樣因?yàn)門(mén)ik為0,導(dǎo)致連乘概率值都為0�,其他特征詞出現(xiàn)得再多����,該文檔也不會(huì)被分到ck類(lèi)別,而且在對(duì)數(shù)累加的情況下��,0值導(dǎo)致計(jì)算錯(cuò)誤���,處理這種問(wèn)題的方法是采樣加1平滑���,即認(rèn)為每個(gè)詞在各個(gè)類(lèi)別中都至少出現(xiàn)過(guò)一次���,即
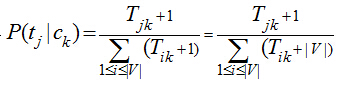
下面這個(gè)例子來(lái)自于參考文獻(xiàn)1��,假設(shè)有如下的訓(xùn)練集合測(cè)試集:

現(xiàn)在要計(jì)算docID為5的測(cè)試文檔是否屬于China類(lèi)別���,首先計(jì)算個(gè)各類(lèi)的概率��,P(c=China)=3/4,P(c!=China)=1/4�����,然后計(jì)算各個(gè)類(lèi)中詞項(xiàng)的概率:
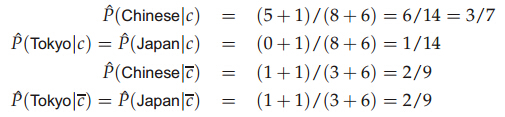
注意分母(8+6)中8表示China類(lèi)的詞項(xiàng)出現(xiàn)的總次數(shù)是8�,+6表示平滑����,6是總詞項(xiàng)的個(gè)數(shù),然后計(jì)算測(cè)試文檔屬于各個(gè)類(lèi)別的概率:
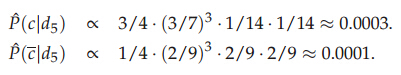
可以看出該測(cè)試文檔應(yīng)該屬于CHina類(lèi)別��。
文本分類(lèi)實(shí)踐
我找了搜狗的搜狐新聞數(shù)據(jù)的歷史簡(jiǎn)潔版�,總共包括汽車(chē)�����、財(cái)經(jīng)�、it、健康等9類(lèi)新聞�����,一共16289條新聞���,搜狗給的數(shù)據(jù)是每一篇新聞?dòng)靡粋€(gè)txt文件保存���,我預(yù)處理了一下����,把所有的新聞文檔保存在一個(gè)文本文件中���,每一行是一篇新聞,同時(shí)保留新聞的id����,id的首字母表示類(lèi)標(biāo)����,預(yù)處理并分詞后的示例如下:

我用6289條新聞作為訓(xùn)練集,剩余1萬(wàn)條用于測(cè)試�,采用互信息進(jìn)行文本特征的提取,總共提取的特征詞是700個(gè)左右���。
分類(lèi)的結(jié)果如下:
8343100000.8343
總共10000條新聞,分類(lèi)正確的8343條��,正確率0.8343���,這里主要是演示貝葉斯的分類(lèi)過(guò)程,只考慮了正確率也沒(méi)有考慮其他評(píng)價(jià)指標(biāo)��,也沒(méi)有進(jìn)行優(yōu)化���。貝葉斯分類(lèi)的效率高����,訓(xùn)練時(shí)�����,只需要掃描一遍訓(xùn)練集,記錄每個(gè)詞出現(xiàn)的次數(shù)���,以及各類(lèi)文檔出現(xiàn)的次數(shù)����,測(cè)試時(shí)也只需要掃描一次測(cè)試集,從運(yùn)行效率這個(gè)角度而言���,樸素貝葉斯的效率是最高的�����,而準(zhǔn)確率也能達(dá)到一個(gè)理想的效果�����。
我的實(shí)現(xiàn)代碼如下:
1 #!encoding=utf-8
2 import random
3 import sys
4 import math
5 import collections
6 import sys
7 def shuffle():
8 '''將原來(lái)的文本打亂順序����,用于得到訓(xùn)練集和測(cè)試集'''
9 datas = [line.strip() for line in sys.stdin]
10 random.shuffle(datas)
11 for line in datas:
12 print line
13
14
15 lables = ['A','B','C','D','E','F','G','H','I']
16 def lable2id(lable):
17 for i in xrange(len(lables)):
18 if lable == lables[i]:
19 return i
20 raise Exception('Error lable %s' % (lable))
21
22 def docdict():
23 return [0]*len(lables)
24
25 def mutalInfo(N,Nij,Ni_,N_j):
26 #print N,Nij,Ni_,N_j
27 return Nij * 1.0 / N * math.log(N * (Nij+1)*1.0/(Ni_*N_j))/ math.log(2)
28
29 def countForMI():
30 '''基于統(tǒng)計(jì)每個(gè)詞在每個(gè)類(lèi)別出現(xiàn)的次數(shù),以及每類(lèi)的文檔數(shù)'''
31 docCount = [0] * len(lables)#每個(gè)類(lèi)的詞數(shù)目
32 wordCount = collections.defaultdict(docdict)
33 for line in sys.stdin:
34 lable,text = line.strip().split(' ',1)
35 index = lable2id(lable[0])
36 words = text.split(' ')
37 for word in words:
38 wordCount[word][index] += 1
39 docCount[index] += 1
40
41 miDict = collections.defaultdict(docdict)#互信息值
42 N = sum(docCount)
43 for k,vs in wordCount.items():
44 for i in xrange(len(vs)):
45 N11 = vs[i]
46 N10 = sum(vs) - N11
47 N01 = docCount[i] - N11
48 N00 = N - N11 - N10 - N01
49 mi = mutalInfo(N,N11,N10+N11,N01+N11) + mutalInfo(N,N10,N10+N11,N00+N10)+ mutalInfo(N,N01,N01+N11,N01+N00)+ mutalInfo(N,N00,N00+N10,N00+N01)
50 miDict[k][i] = mi
51 fWords = set()
52 for i in xrange(len(docCount)):
53 keyf = lambda x:x[1][i]
54 sortedDict = sorted(miDict.items(),key=keyf,reverse=True)
55 for j in xrange(100):
56 fWords.add(sortedDict[j][0])
57 print docCount#打印各個(gè)類(lèi)的文檔數(shù)目
58 for fword in fWords:
59 print fword
60
61
62 def loadFeatureWord():
63 '''導(dǎo)入特征詞'''
64 f = open('feature.txt')
65 docCounts = eval(f.readline())
66 features = set()
67 for line in f:
68 features.add(line.strip())
69 f.close()
70 return docCounts,features
71
72 def trainBayes():
73 '''訓(xùn)練貝葉斯模型���,實(shí)際上計(jì)算每個(gè)類(lèi)中特征詞的出現(xiàn)次數(shù)'''
74 docCounts,features = loadFeatureWord()
75 wordCount = collections.defaultdict(docdict)
76 tCount = [0]*len(docCounts)#每類(lèi)文檔特征詞出現(xiàn)的次數(shù)
77 for line in sys.stdin:
78 lable,text = line.strip().split(' ',1)
79 index = lable2id(lable[0])
80 words = text.split(' ')
81 for word in words:
82 if word in features:
83 tCount[index] += 1
84 wordCount[word][index] += 1
85 for k,v in wordCount.items():
86 scores = [(v[i]+1) * 1.0 / (tCount[i]+len(wordCount)) for i in xrange(len(v))]#加1平滑
87 print '%s\t%s' % (k,scores)
88
89 def loadModel():
90 '''導(dǎo)入貝葉斯模型'''
91 f = open('model.txt')
92 scores = {}
93 for line in f:
94 word,counts = line.strip().rsplit('\t',1)
95 scores[word] = eval(counts)
96 f.close()
97 return scores
98
99 def predict():
100 '''預(yù)測(cè)文檔的類(lèi)標(biāo)��,標(biāo)準(zhǔn)輸入每一行為一個(gè)文檔'''
101 docCounts,features = loadFeatureWord()
102 docscores = [math.log(count * 1.0 /sum(docCounts)) for count in docCounts]
103 scores = loadModel()
104 rCount = 0
105 docCount = 0
106 for line in sys.stdin:
107 lable,text = line.strip().split(' ',1)
108 index = lable2id(lable[0])
109 words = text.split(' ')
110 preValues = list(docscores)
111 for word in words:
112 if word in features:
113 for i in xrange(len(preValues)):
114 preValues[i]+=math.log(scores[word][i])
115 m = max(preValues)
116 pIndex = preValues.index(m)
117 if pIndex == index:
118 rCount += 1
119 print lable,lables[pIndex],text
120 docCount += 1
121 print rCount,docCount,rCount * 1.0 / docCount
122
123
124 if __name__=="__main__":
125 #shuffle()
126 #countForMI()
127 #trainBayes()
128 predict()
代碼里面��,計(jì)算特征詞與訓(xùn)練模型�、測(cè)試是分開(kāi)的��,需要修改main方法����,比如計(jì)算特征詞:
$cat train.txt | python bayes.py > feature.txt
訓(xùn)練模型:
$cat train.txt | python bayes.py > model.txt
預(yù)測(cè)模型:
$cat test.txt | python bayes.py > predict.out
總結(jié)
本文介紹了樸素貝葉斯分類(lèi)方法,還以文本分類(lèi)為例��,給出了一個(gè)具體應(yīng)用的例子�����,樸素貝葉斯的樸素體現(xiàn)在條件變量之間的獨(dú)立性假設(shè)���,應(yīng)用到文本分類(lèi)上��,作了兩個(gè)假設(shè)����,一是各個(gè)特征詞對(duì)分類(lèi)的影響是獨(dú)立的,另一個(gè)是詞項(xiàng)在文檔中的順序是無(wú)關(guān)緊要的��。樸素貝葉斯的獨(dú)立性假設(shè)在實(shí)際中并不成立����,但在分類(lèi)效上依然不錯(cuò)����,加上獨(dú)立性假設(shè)后,對(duì)與屬于類(lèi)ck的謀篇文檔d�����,其p(ck|d)往往會(huì)估計(jì)過(guò)高����,即本來(lái)預(yù)期p(ck|d)=0.55,而樸素貝葉斯卻計(jì)算得到p(ck|d)=0.99���,但這并不影響分類(lèi)結(jié)果�����,這是樸素貝葉斯分類(lèi)器在文本分類(lèi)上效果優(yōu)于預(yù)期的原因�����。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試�,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材����,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫(kù)����,點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情;
? 想了解CDA考試含金量��,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330