數(shù)據(jù)挖掘系列關(guān)聯(lián)規(guī)則挖掘基本概念與Aprior算法
關(guān)聯(lián)規(guī)則挖掘在電商���、零售�、大氣物理、生物醫(yī)學已經(jīng)有了廣泛的應用,本篇文章將介紹一些基本知識和Aprori算法����。
啤酒與尿布的故事已經(jīng)成為了關(guān)聯(lián)規(guī)則挖掘的經(jīng)典案例�,還有人專門出了一本書《啤酒與尿布》,雖然說這個故事是哈弗商學院杜撰出來的���,但確實能很好的解釋關(guān)聯(lián)規(guī)則挖掘的原理�。我們這里以一個超市購物籃迷你數(shù)據(jù)集來解釋關(guān)聯(lián)規(guī)則挖掘的基本概念:
|
TID
|
Items
|
|
T1
|
{牛奶,面包}
|
|
T2
|
{面包,尿布,啤酒,雞蛋}
|
|
T3
|
{牛奶,尿布,啤酒,可樂}
|
|
T4
|
{面包,牛奶,尿布,啤酒}
|
|
T5
|
{面包,牛奶,尿布,可樂}
|
表中的每一行代表一次購買清單(注意你購買十盒牛奶也只計一次���,即只記錄某個商品的出現(xiàn)與否)。數(shù)據(jù)記錄的所有項的集合稱為總項集����,上表中的總項集S={牛奶,面包,尿布,啤酒,雞蛋,可樂}。
一��、關(guān)聯(lián)規(guī)則��、自信度�、自持度的定義
關(guān)聯(lián)規(guī)則就是有關(guān)聯(lián)的規(guī)則,形式是這樣定義的:兩個不相交的非空集合X��、Y,如果有X-->Y�����,就說X-->Y是一條關(guān)聯(lián)規(guī)則�。舉個例子,在上面的表中���,我們發(fā)現(xiàn)購買啤酒就一定會購買尿布�,{啤酒}-->{尿布}就是一條關(guān)聯(lián)規(guī)則����。關(guān)聯(lián)規(guī)則的強度用支持度(support)和自信度(confidence)來描述,
支持度的定義:support(X-->Y) = |X交Y|/N=集合X與集合Y中的項在一條記錄中同時出現(xiàn)的次數(shù)/數(shù)據(jù)記錄的個數(shù)����。例如:support({啤酒}-->{尿布}) = 啤酒和尿布同時出現(xiàn)的次數(shù)/數(shù)據(jù)記錄數(shù) = 3/5=60%。
自信度的定義:confidence(X-->Y) = |X交Y|/|X| = 集合X與集合Y中的項在一條記錄中同時出現(xiàn)的次數(shù)/集合X出現(xiàn)的個數(shù) ��。例如:confidence({啤酒}-->{尿布}) = 啤酒和尿布同時出現(xiàn)的次數(shù)/啤酒出現(xiàn)的次數(shù)=3/3=100%;confidence({尿布}-->{啤酒}) = 啤酒和尿布同時出現(xiàn)的次數(shù)/尿布出現(xiàn)的次數(shù) = 3/4 = 75%���。
這里定義的支持度和自信度都是相對的支持度和自信度���,不是絕對支持度����,絕對支持度abs_support = 數(shù)據(jù)記錄數(shù)N*support��。
支持度和自信度越高���,說明規(guī)則越強�����,關(guān)聯(lián)規(guī)則挖掘就是挖掘出滿足一定強度的規(guī)則���。
二�����、關(guān)聯(lián)規(guī)則挖掘的定義與步驟
關(guān)聯(lián)規(guī)則挖掘的定義:給定一個交易數(shù)據(jù)集T����,找出其中所有支持度support >= min_support、自信度confidence >= min_confidence的關(guān)聯(lián)規(guī)則��。
有一個簡單而粗魯?shù)姆椒梢哉页鏊枰囊?guī)則��,那就是窮舉項集的所有組合,并測試每個組合是否滿足條件��,一個元素個數(shù)為n的項集的組合個數(shù)為2^n-1(除去空集)���,所需要的時間復雜度明顯為O(2^N)�����,對于普通的超市��,其商品的項集數(shù)也在1萬以上�����,用指數(shù)時間復雜度的算法不能在可接受的時間內(nèi)解決問題���。怎樣快速挖出滿足條件的關(guān)聯(lián)規(guī)則是關(guān)聯(lián)挖掘的需要解決的主要問題。
仔細想一下�,我們會發(fā)現(xiàn)對于{啤酒-->尿布},{尿布-->啤酒}這兩個規(guī)則的支持度實際上只需要計算{尿布��,啤酒}的支持度���,即它們交集的支持度����。于是我們把關(guān)聯(lián)規(guī)則挖掘分兩步進行:
1)生成頻繁項集
這一階段找出所有滿足最小支持度的項集,找出的這些項集稱為頻繁項集��。
2)生成規(guī)則
在上一步產(chǎn)生的頻繁項集的基礎(chǔ)上生成滿足最小自信度的規(guī)則�,產(chǎn)生的規(guī)則稱為強規(guī)則。
關(guān)聯(lián)規(guī)則挖掘所花費的時間主要是在生成頻繁項集上����,因為找出的頻繁項集往往不會很多,利用頻繁項集生成規(guī)則也就不會花太多的時間��,而生成頻繁項集需要測試很多的備選項集�,如果不加優(yōu)化,所需的時間是O(2^N)�����。
三���、Apriori定律
為了減少頻繁項集的生成時間,我們應該盡早的消除一些完全不可能是頻繁項集的集合�,Apriori的兩條定律就是干這事的。
Apriori定律1):如果一個集合是頻繁項集���,則它的所有子集都是頻繁項集�。舉例:假設(shè)一個集合{A,B}是頻繁項集,即A�、B同時出現(xiàn)在一條記錄的次數(shù)大于等于最小支持度min_support,則它的子集{A},{B}出現(xiàn)次數(shù)必定大于等于min_support��,即它的子集都是頻繁項集�。
Apriori定律2):如果一個集合不是頻繁項集,則它的所有超集都不是頻繁項集�����。舉例:假設(shè)集合{A}不是頻繁項集�����,即A出現(xiàn)的次數(shù)小于min_support��,則它的任何超集如{A,B}出現(xiàn)的次數(shù)必定小于min_support�,因此其超集必定也不是頻繁項集。
利用這兩條定律���,我們拋掉很多的候選項集��,Apriori算法就是利用這兩個定理來實現(xiàn)快速挖掘頻繁項集的����。
四、Apriori算法
Apriori是由a priori合并而來的�����,它的意思是后面的是在前面的基礎(chǔ)上推出來的��,即先驗推導�,怎么個先驗法,其實就是二級頻繁項集是在一級頻繁項集的基礎(chǔ)上產(chǎn)生的���,三級頻繁項集是在二級頻繁項集的基礎(chǔ)上產(chǎn)生的�����,以此類推�����。
Apriori算法屬于候選消除算法��,是一個生成候選集、消除不滿足條件的候選集、并不斷循環(huán)直到不再產(chǎn)生候選集的過程��。
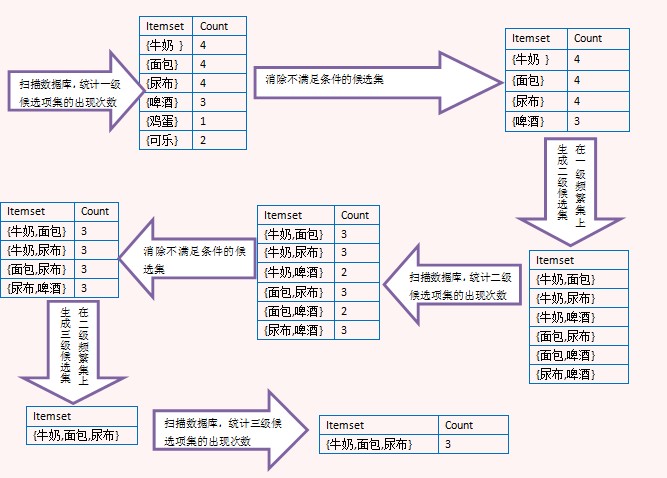
上面的圖演示了Apriori算法的過程���,注意看由二級頻繁項集生成三級候選項集時���,沒有{牛奶,面包,啤酒},那是因為{面包,啤酒}不是二級頻繁項集�����,這里利用了Apriori定理�����。最后生成三級頻繁項集后����,沒有更高一級的候選項集,因此整個算法結(jié)束���,{牛奶,面包,尿布}是最大頻繁子集�。
算法的思想知道了��,這里也就不上偽代碼了,我認為理解了算法的思想后����,子集去構(gòu)思實現(xiàn)才能理解更深刻,這里貼一下我的關(guān)鍵代碼:

如果想看完整的代碼��,可以查看我的github�����,數(shù)據(jù)集的格式跟本文所述的略有不通�,但不影響對算法的理解。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材�,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330