決策樹(shù)算法借助于樹(shù)的分支結(jié)構(gòu)實(shí)現(xiàn)分類���。下圖是一個(gè)決策樹(shù)的示例,樹(shù)的內(nèi)部結(jié)點(diǎn)表示對(duì)某個(gè)屬性的判斷���,該結(jié)點(diǎn)的分支是對(duì)應(yīng)的判斷結(jié)果����;葉子結(jié)點(diǎn)代表一個(gè)類標(biāo)��。

上表是一個(gè)預(yù)測(cè)一個(gè)人是否會(huì)購(gòu)買購(gòu)買電腦的決策樹(shù)��,利用這棵樹(shù)����,我們可以對(duì)新記錄進(jìn)行分類,從根節(jié)點(diǎn)(年齡)開(kāi)始���,如果某個(gè)人的年齡為中年�,我們就直接判斷這個(gè)人會(huì)買電腦,如果是青少年�,則需要進(jìn)一步判斷是否是學(xué)生;如果是老年則需要進(jìn)一步判斷其信用等級(jí)����,直到葉子結(jié)點(diǎn)可以判定記錄的類別。
決策樹(shù)算法有一個(gè)好處����,那就是它可以產(chǎn)生人能直接理解的規(guī)則,這是貝葉斯�、神經(jīng)網(wǎng)絡(luò)等算法沒(méi)有的特性;決策樹(shù)的準(zhǔn)確率也比較高�����,而且不需要了解背景知識(shí)就可以進(jìn)行分類���,是一個(gè)非常有效的算法�。決策樹(shù)算法有很多變種�����,包括ID3、C4.5����、C5.0、CART等���,但其基礎(chǔ)都是類似的���。下面來(lái)看看決策樹(shù)算法的基本思想:
算法:GenerateDecisionTree(D,attributeList)根據(jù)訓(xùn)練數(shù)據(jù)記錄D生成一棵決策樹(shù).
輸入:數(shù)據(jù)記錄D,包含類標(biāo)的訓(xùn)練數(shù)據(jù)集;
屬性列表attributeList�,候選屬性集,用于在內(nèi)部結(jié)點(diǎn)中作判斷的屬性.
屬性選擇方法AttributeSelectionMethod()�,選擇最佳分類屬性的方法.
輸出:一棵決策樹(shù).
過(guò)程:
構(gòu)造一個(gè)節(jié)點(diǎn)N�;
如果數(shù)據(jù)記錄D中的所有記錄的類標(biāo)都相同(記為C類):
則將節(jié)點(diǎn)N作為葉子節(jié)點(diǎn)標(biāo)記為C,并返回結(jié)點(diǎn)N���;
如果屬性列表為空:
則將節(jié)點(diǎn)N作為葉子結(jié)點(diǎn)標(biāo)記為D中類標(biāo)最多的類��,并返回結(jié)點(diǎn)N���;
調(diào)用AttributeSelectionMethod(D,attributeList)選擇最佳的分裂準(zhǔn)則splitCriterion;
將節(jié)點(diǎn)N標(biāo)記為最佳分裂準(zhǔn)則splitCriterion;
如果分裂屬性取值是離散的,并且允許決策樹(shù)進(jìn)行多叉分裂:
從屬性列表中減去分裂屬性����,attributeLsit -= splitAttribute;
對(duì)分裂屬性的每一個(gè)取值j:
記D中滿足j的記錄集合為Dj;
如果Dj為空:
則新建一個(gè)葉子結(jié)點(diǎn)F�,標(biāo)記為D中類標(biāo)最多的類���,并且把結(jié)點(diǎn)F掛在N下;
否則:
遞歸調(diào)用GenerateDecisionTree(Dj,attributeList)得到子樹(shù)結(jié)點(diǎn)Nj�,將Nj掛在N下;
返回結(jié)點(diǎn)N;
算法的1�、2、3步驟都 很顯然��,第4步的最佳屬性選擇函數(shù)會(huì)在后面專門介紹���,現(xiàn)在只有知道它能找到一個(gè)準(zhǔn)則�����,使得根據(jù)判斷結(jié)點(diǎn)得到的子樹(shù)的類別盡可能的純�����,這里的純就是只含有一個(gè)類標(biāo)����;第5步根據(jù)分裂準(zhǔn)則設(shè)置結(jié)點(diǎn)N的測(cè)試表達(dá)式��。在第6步中,對(duì)應(yīng)構(gòu)建多叉決策樹(shù)時(shí)����,離散的屬性在結(jié)點(diǎn)N及其子樹(shù)中只用一次,用過(guò)之后就從可用屬性列表中刪掉�。比如前面的圖中,利用屬性選擇函數(shù)����,確定的最佳分裂屬性是年齡,年齡有三個(gè)取值��,每一個(gè)取值對(duì)應(yīng)一個(gè)分支�����,后面不會(huì)再用到年齡這個(gè)屬性����。算法的時(shí)間復(fù)雜度是O(k*|D|*log(|D|))���,k為屬性個(gè)數(shù)��,|D|為記錄集D的記錄數(shù)�����。
很顯然��,第4步的最佳屬性選擇函數(shù)會(huì)在后面專門介紹���,現(xiàn)在只有知道它能找到一個(gè)準(zhǔn)則�����,使得根據(jù)判斷結(jié)點(diǎn)得到的子樹(shù)的類別盡可能的純�����,這里的純就是只含有一個(gè)類標(biāo)����;第5步根據(jù)分裂準(zhǔn)則設(shè)置結(jié)點(diǎn)N的測(cè)試表達(dá)式��。在第6步中,對(duì)應(yīng)構(gòu)建多叉決策樹(shù)時(shí)����,離散的屬性在結(jié)點(diǎn)N及其子樹(shù)中只用一次,用過(guò)之后就從可用屬性列表中刪掉�。比如前面的圖中,利用屬性選擇函數(shù)����,確定的最佳分裂屬性是年齡,年齡有三個(gè)取值��,每一個(gè)取值對(duì)應(yīng)一個(gè)分支�����,后面不會(huì)再用到年齡這個(gè)屬性����。算法的時(shí)間復(fù)雜度是O(k*|D|*log(|D|))���,k為屬性個(gè)數(shù)��,|D|為記錄集D的記錄數(shù)�����。
三�����、屬性選擇方法
屬性選擇方法總是選擇最好的屬性最為分裂屬性�,即讓每個(gè)分支的記錄的類別盡可能純。它將所有屬性列表的屬性進(jìn)行按某個(gè)標(biāo)準(zhǔn)排序��,從而選出最好的屬性�����。屬性選擇方法很多�����,這里我介紹三個(gè)常用的方法:信息增益(Information gain)��、增益比率(gain ratio)�����、基尼指數(shù)(Gini index)��。
信息增益(Information gain)
信息增益基于香濃的信息論,它找出的屬性R具有這樣的特點(diǎn):以屬性R分裂前后的信息增益比其他屬性最大�����。這里信息的定義如下:
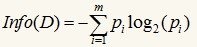
其中的m表示數(shù)據(jù)集D中類別C的個(gè)數(shù)�,Pi表示D中任意一個(gè)記錄屬于Ci的概率,計(jì)算時(shí)Pi=(D中屬于Ci類的集合的記錄個(gè)數(shù)/|D|)����。Info(D)表示將數(shù)據(jù)集D不同的類分開(kāi)需要的信息量。
如果了解信息論����,就會(huì)知道上面的信息Info實(shí)際上就是信息論中的熵Entropy,熵表示的是不確定度的度量��,如果某個(gè)數(shù)據(jù)集的類別的不確定程度越高�,則其熵就越大。比如我們將一個(gè)立方體A拋向空中�,記落地時(shí)著地的面為f1,f1的取值為{1,2,3,4,5,6}����,f1的熵entropy(f1)=-(1/6*log(1/6)+…+1/6*log(1/6))=-1*log(1/6)=2.58���;現(xiàn)在我們把立方體A換為正四面體B�,記落地時(shí)著地的面為f2,f2的取值為{1,2,3,4}�����,f2的熵entropy(1)=-(1/4*log(1/4)+1/4*log(1/4)+1/4*log(1/4)+1/4*log(1/4)) =-log(1/4)=2����;如果我們?cè)贀Q成一個(gè)球C,記落地時(shí)著地的面為f3���,顯然不管怎么扔著地都是同一個(gè)面�,即f3的取值為{1}��,故其熵entropy(f3)=-1*log(1)=0���?���?梢钥吹矫鏀?shù)越多���,熵值也越大����,而當(dāng)只有一個(gè)面的球時(shí),熵值為0���,此時(shí)表示不確定程度為0���,也就是著地時(shí)向下的面是確定的。
有了上面關(guān)于熵的簡(jiǎn)單理解����,我們接著講信息增益。假設(shè)我們選擇屬性R作為分裂屬性�,數(shù)據(jù)集D中,R有k個(gè)不同的取值{V1,V2,…,Vk}��,于是可將D根據(jù)R的值分成k組{D1,D2,…,Dk}����,按R進(jìn)行分裂后,將數(shù)據(jù)集D不同的類分開(kāi)還需要的信息量為:

信息增益的定義為分裂前后�����,兩個(gè)信息量只差:

信息增益Gain(R)表示屬性R給分類帶來(lái)的信息量,我們尋找Gain最大的屬性��,就能使分類盡可能的純��,即最可能的把不同的類分開(kāi)����。不過(guò)我們發(fā)現(xiàn)對(duì)所以的屬性Info(D)都是一樣的���,所以求最大的Gain可以轉(zhuǎn)化為求最新的InfoR(D)��。這里引入Info(D)只是為了說(shuō)明背后的原理����,方便理解����,實(shí)現(xiàn)時(shí)我們不需要計(jì)算Info(D)。舉一個(gè)例子���,數(shù)據(jù)集D如下:
|
記錄ID
|
年齡
|
輸入層次
|
學(xué)生
|
信用等級(jí)
|
是否購(gòu)買電腦
|
|
1
|
青少年
|
高
|
否
|
一般
|
否
|
|
2
|
青少年
|
高
|
否
|
良好
|
否
|
|
3
|
中年
|
高
|
否
|
一般
|
是
|
|
4
|
老年
|
中
|
否
|
一般
|
是
|
|
5
|
老年
|
低
|
是
|
一般
|
是
|
|
6
|
老年
|
低
|
是
|
良好
|
否
|
|
7
|
中年
|
低
|
是
|
良好
|
是
|
|
8
|
青少年
|
中
|
否
|
一般
|
否
|
|
9
|
青少年
|
低
|
是
|
一般
|
是
|
|
10
|
老年
|
中
|
是
|
一般
|
是
|
|
11
|
青少年
|
中
|
是
|
良好
|
是
|
|
12
|
中年
|
中
|
否
|
良好
|
是
|
|
13
|
中年
|
高
|
是
|
一般
|
是
|
|
14
|
老年
|
中
|
否
|
良好
|
否
|
這個(gè)數(shù)據(jù)集是根據(jù)一個(gè)人的年齡���、收入、是否學(xué)生以及信用等級(jí)來(lái)確定他是否會(huì)購(gòu)買電腦,即最后一列“是否購(gòu)買電腦”是類標(biāo)?���,F(xiàn)在我們用信息增益選出最最佳的分類屬性,計(jì)算按年齡分裂后的信息量:
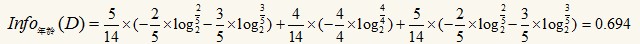
整個(gè)式子由三項(xiàng)累加而成�����,第一項(xiàng)為青少年���,14條記錄中有5條為青少年�,其中2(占2/5)條購(gòu)買電腦�,3(占3/5)條不購(gòu)買電腦。第二項(xiàng)為中年��,第三項(xiàng)為老年���。類似的�,有:
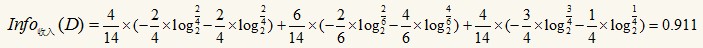
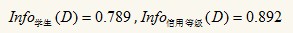
可以得出Info年齡(D)最小�����,即以年齡分裂后����,分得的結(jié)果中類標(biāo)最純�,此時(shí)已年齡作為根結(jié)點(diǎn)的測(cè)試屬性����,根據(jù)青少年�、中年、老年分為三個(gè)分支:
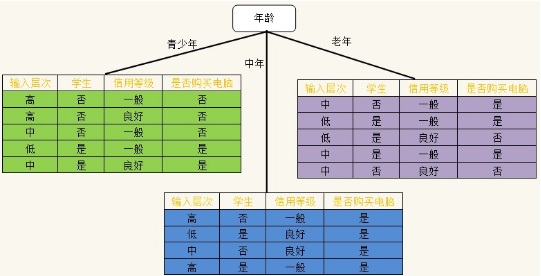
注意����,年齡這個(gè)屬性用過(guò)后,之后的操作就不需要年齡了���,即把年齡從attributeList中刪掉��。往后就按照同樣的方法����,構(gòu)建D1,D2,D3對(duì)應(yīng)的決策子樹(shù)���。ID3算法使用的就是基于信息增益的選擇屬性方法����。
增益比率(gain ratio)
信息增益選擇方法有一個(gè)很大的缺陷,它總是會(huì)傾向于選擇屬性值多的屬性�,如果我們?cè)谏厦娴臄?shù)據(jù)記錄中加一個(gè)姓名屬性,假設(shè)14條記錄中的每個(gè)人姓名不同�����,那么信息增益就會(huì)選擇姓名作為最佳屬性����,因?yàn)榘葱彰至押螅總€(gè)組只包含一條記錄�����,而每個(gè)記錄只屬于一類(要么購(gòu)買電腦要么不購(gòu)買)���,因此純度最高����,以姓名作為測(cè)試分裂的結(jié)點(diǎn)下面有14個(gè)分支��。但是這樣的分類沒(méi)有意義���,它每一任何泛化能力��。增益比率對(duì)此進(jìn)行了改進(jìn)�����,它引入一個(gè)分裂信息:
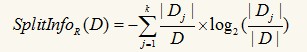
增益比率定義為信息增益與分裂信息的比率:
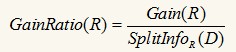
我們找GainRatio最大的屬性作為最佳分裂屬性��。如果一個(gè)屬性的取值很多����,那么SplitInfoR(D)會(huì)大���,從而使GainRatio(R)變小��。不過(guò)增益比率也有缺點(diǎn)�����,SplitInfo(D)可能取0��,此時(shí)沒(méi)有計(jì)算意義�;且當(dāng)SplitInfo(D)趨向于0時(shí)�,GainRatio(R)的值變得不可信,改進(jìn)的措施就是在分母加一個(gè)平滑����,這里加一個(gè)所有分裂信息的平均值:
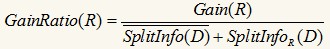
基尼指數(shù)(Gini index)
基尼指數(shù)是另外一種數(shù)據(jù)的不純度的度量方法�����,其定義如下:

其中的m仍然表示數(shù)據(jù)集D中類別C的個(gè)數(shù)��,Pi表示D中任意一個(gè)記錄屬于Ci的概率����,計(jì)算時(shí)Pi=(D中屬于Ci類的集合的記錄個(gè)數(shù)/|D|)����。如果所有的記錄都屬于同一個(gè)類中,則P1=1���,Gini(D)=0�����,此時(shí)不純度最低��。在CART(Classification and Regression Tree)算法中利用基尼指數(shù)構(gòu)造二叉決策樹(shù)�,對(duì)每個(gè)屬性都會(huì)枚舉其屬性的非空真子集��,以屬性R分裂后的基尼系數(shù)為:

D1為D的一個(gè)非空真子集,D2為D1在D的補(bǔ)集���,即D1+D2=D�����,對(duì)于屬性R來(lái)說(shuō)���,有多個(gè)真子集,即GiniR(D)有多個(gè)值�,但我們選取最小的那么值作為R的基尼指數(shù)。最后:
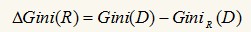
我們轉(zhuǎn)Gini(R)增量最大的屬性作為最佳分裂屬性����。











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330