小白學(xué)數(shù)據(jù)分析之關(guān)聯(lián)分析算法篇Apriori
早些時候?qū)戇^關(guān)于購物籃分析的文章����,其中提到了C5.0和Apriori算法�,沒有仔細(xì)說說這算法的含義,昨天寫了一下關(guān)聯(lián)分析的理論部分�����,今天說說關(guān)聯(lián)分析算法之一的Apriori算法�����,很多時候大家都說����,數(shù)據(jù)分析師更多的是會用就可以了,不必糾結(jié)于那些長篇累牘的理論�����,其實(shí)我覺得還是有點(diǎn)必要的,你未必要去設(shè)計(jì)算法��,但是如果你掌握和熟知一個算法����,這對于你如何駕馭和使用這個算法是很有幫助的,此外每個算法都有使用的局限性����,比如空間和時間復(fù)雜度,使用條件約束�����。最典型的就是我們難道一份原始數(shù)據(jù)���,然后經(jīng)過數(shù)據(jù)處理要進(jìn)行算法模擬分析,但是此時你會出現(xiàn)一個問題����,我需要處理哪些數(shù)據(jù),如何處理�����?而這就需要你對你所使用的算法必須熟悉,比如能夠操作的數(shù)據(jù)格式���,類型�。比如GRI算法要求使用的數(shù)據(jù)必須是事實(shí)表的方式存儲�����,這樣的算法特點(diǎn)必須建立在對于算法的了解把握層次上�。
Apriori算法
其名字是因?yàn)樗惴ɑ谙闰?yàn)知識(prior knowledge).根據(jù)前一次找到的頻繁項(xiàng)來生成本次的頻繁項(xiàng)。Apriori是關(guān)聯(lián)分析中核心的算法�。
Apriori算法的特點(diǎn)
只能處理分類變量,無法處理數(shù)值型變量�;
數(shù)據(jù)存儲可以是交易數(shù)據(jù)格式(事務(wù)表),或者是事實(shí)表方式(表格數(shù)據(jù))����;
算法核心在于提升關(guān)聯(lián)規(guī)則產(chǎn)生的效率而設(shè)計(jì)的。
Apriori的思想
正如我們之前所提到的��,我們希望置信度和支持度要滿足我們的閾值范圍才算是有效的規(guī)則����,實(shí)際過程中我們往往會面臨大量的數(shù)據(jù)�,如果只是簡單的搜索�,會出現(xiàn)很多的規(guī)則,相當(dāng)大的一部分是無效的規(guī)則��,效率很低���,那么Apriori就是通過產(chǎn)生頻繁項(xiàng)集�,然后再依據(jù)頻繁項(xiàng)集產(chǎn)生規(guī)則����,進(jìn)而提升效率。
以上所說的代表了Apriori算法的兩個步驟:產(chǎn)生頻繁項(xiàng)集和依據(jù)頻繁項(xiàng)集產(chǎn)生規(guī)則����。
那么什么是頻繁項(xiàng)集?
頻繁項(xiàng)集就是對包含項(xiàng)目A的項(xiàng)目集C���,其支持度大于等于指定的支持度���,則C(A)為頻繁項(xiàng)集�����,包含一個項(xiàng)目的頻繁項(xiàng)集稱為頻繁1-項(xiàng)集,即L1�。
為什么確定頻繁項(xiàng)集?
剛才說了��,必須支持度大于我們指定的支持度��,這也就是說能夠確定后面生成的規(guī)則是在普遍代表性上的項(xiàng)目集生成的��,因?yàn)橹С侄缺旧淼母叩途痛砹宋覀冴P(guān)聯(lián)分析結(jié)果是否具有普遍性����。
怎么尋找頻繁項(xiàng)集?
這里不再講述�����,直接說一個例子大家就都明白了�。例子來源于Fast Algorithms for Mining Association Rules
Apriori尋找頻繁項(xiàng)集的過程是一個不斷迭代的過程,每次都是兩個步驟�,產(chǎn)生候選集Ck(可能成為頻繁項(xiàng)集的項(xiàng)目組合);基于候選集Ck計(jì)算支持度��,確定Lk��。
Apriori的尋找策略就是從包含少量的項(xiàng)目開始逐漸向多個項(xiàng)目的項(xiàng)目集搜索���。
數(shù)據(jù)如下:
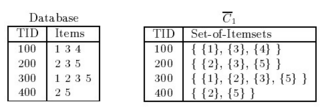
我們看到�����,數(shù)據(jù)庫存儲的數(shù)據(jù)格式�����,會員100購買了 1 3 4三種商品�,那么對應(yīng)的集合形式如右邊的圖所示。那么基于候選集C1���,我們得到頻繁項(xiàng)集L1���,如下圖所示,在此表格中{4}的支持度為1�,而我們設(shè)定的支持度為2。支持度大于或者等于指定的支持度的最小閾值就成為L1了�����,這里{4}沒有成為L1的一員��。因此�,我們認(rèn)定包含4的其他項(xiàng)集都不可能是頻繁項(xiàng)集,后續(xù)就不再對其進(jìn)行判斷了�。
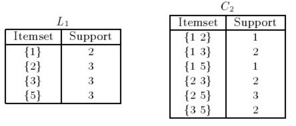
此時我們看到L1是符合最低支持度的標(biāo)準(zhǔn)的,那么下一次迭代我們依據(jù)L1產(chǎn)生C2(4就不再被考慮了)���,此時的候選集如右圖所示C2(依據(jù)L1*L1的組合方式)確立���。C2的每個集合得到的支持度對應(yīng)在我們原始數(shù)據(jù)組合的計(jì)數(shù),如下圖左所示��。

此時���,第二次迭代發(fā)現(xiàn)了{(lán)1 2} {1 5}的支持度只有1�,低于閾值��,故而舍棄���,那么在隨后的迭代中�,如果出現(xiàn){1 2} {1 5}的組合形式將不被考慮���。
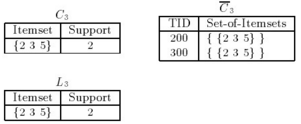
如上圖��,由L2得到候選集C3���,那么這次迭代中的{1 2 3} { 1 3 5}哪去了��?如剛才所言����,{1 2} {1 5}的組合形式將不被考慮���,因?yàn)檫@兩個項(xiàng)集不可能成為頻繁項(xiàng)集L3���,此時L4不能構(gòu)成候選集L4,即停止�。
如果用一句化解釋上述的過程,就是不斷通過Lk的自身連接���,形成候選集��,然后在進(jìn)行剪枝��,除掉無用的部分���。
根據(jù)頻繁項(xiàng)集產(chǎn)生簡單關(guān)聯(lián)規(guī)則
Apriori的關(guān)聯(lián)規(guī)則是在頻繁項(xiàng)集基礎(chǔ)上產(chǎn)生的,進(jìn)而這可以保證這些規(guī)則的支持度達(dá)到指定的水平,具有普遍性和令人信服的水平��。
以上就是Apriori的算法基本原理���,留了兩個例子��,可以加深理解。
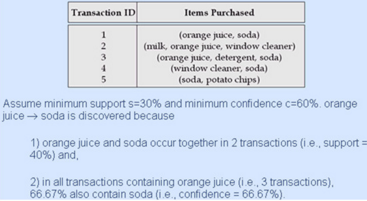
例子1:
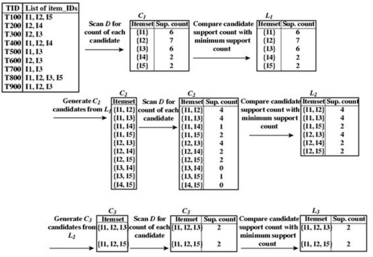
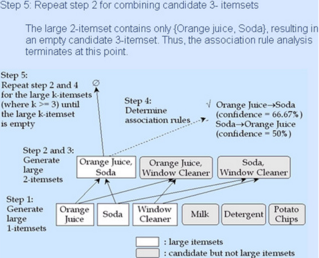
例子2:


CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試�,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材����,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫�,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量�����,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情�����;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330