機(jī)器學(xué)習(xí):用初等數(shù)學(xué)解讀邏輯回歸
大數(shù)據(jù)文摘愿意為讀者打造高質(zhì)量【機(jī)器學(xué)習(xí)】,措施如下
(1)群內(nèi)定期組織分享
(2)確保群內(nèi)分享者和學(xué)習(xí)者數(shù)量適合�,有分享能力者不限名額,學(xué)習(xí)者數(shù)量少于分享者��,按申請(qǐng)順序排序�。
點(diǎn)擊微信文章文末“閱讀原文”填表入群
為了降低理解難度,本文試圖用最基礎(chǔ)的初等數(shù)學(xué)來(lái)解讀邏輯回歸��,少用公式����,多用圖形來(lái)直觀解釋推導(dǎo)公式的現(xiàn)實(shí)意義�,希望使讀者能夠?qū)?a href='/map/luojihuigui/' style='color:#000;font-size:inherit;'>邏輯回歸有更直觀的理解�����。
“邏輯回歸問(wèn)題的通俗幾何描述
邏輯回歸處理的是分類(lèi)問(wèn)題�。我們可以用通俗的幾何語(yǔ)言重新表述它:
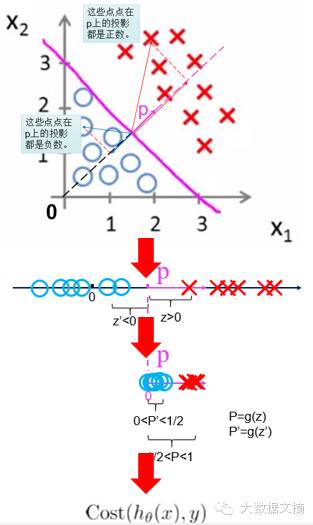
空間中有兩群點(diǎn),一群是圓點(diǎn)“〇”����,一群是叉點(diǎn)“X”。我們希望從空間中選出一個(gè)分離邊界����,將這兩群點(diǎn)分開(kāi)。
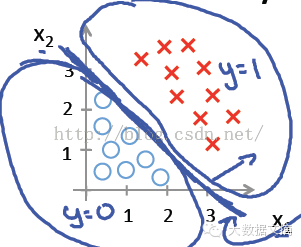
注:分離邊界的維數(shù)與空間的維數(shù)相關(guān)��。如果是二維平面�,分離邊界就是一條線(一維)。如果是三維空間����,分離邊界就是一個(gè)空間中的面(二維)。如果是一維直線�����,分離邊界就是直線上的某一點(diǎn)。不同維數(shù)的空間的理解下文將有專(zhuān)門(mén)的論述�。
為了簡(jiǎn)化處理和方便表述,我們做以下4個(gè)約定:
我們先考慮在二維平面下的情況�����。
而且���,我們假設(shè)這兩類(lèi)是線性可分的:即可以找到一條最佳的直線,將兩類(lèi)點(diǎn)分開(kāi)���。
用離散變量y表示點(diǎn)的類(lèi)別��,y只有兩個(gè)可能的取值����。y=1表示是叉點(diǎn)“X”�,y=0表示是是圓點(diǎn)“〇”。
點(diǎn)的橫縱坐標(biāo)用
表示�。
于是,現(xiàn)在的問(wèn)題就變成了:怎么依靠現(xiàn)有這些點(diǎn)的坐標(biāo)
和標(biāo)簽(y)��,找出分界線的方程。
“如何用解析幾何的知識(shí)找到邏輯回歸問(wèn)題的分界線���?
我們用逆推法的思路:
假設(shè)我們已經(jīng)找到了這一條線���,再尋找這條線的性質(zhì)是什么。根據(jù)這些性質(zhì)�����,再來(lái)反推這條線的方程�。
這條線有什么性質(zhì)呢?
首先�����,它能把兩類(lèi)點(diǎn)分開(kāi)來(lái)�����?!冒桑@是廢話�����。( ̄▽?zhuān)?”
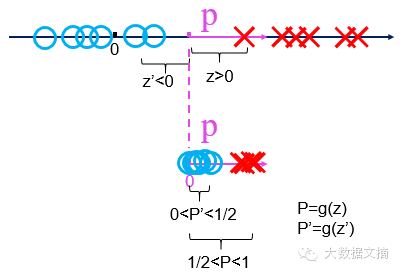
然后,兩類(lèi)點(diǎn)在這條線的法向量p上的投影的值的正負(fù)號(hào)不一樣�,一類(lèi)點(diǎn)的投影全是正數(shù),另一類(lèi)點(diǎn)的投影值全是負(fù)數(shù)�����!
首先�,這個(gè)性質(zhì)是非常好,可以用來(lái)區(qū)分點(diǎn)的不同的類(lèi)別�。
而且,我們對(duì)法向量進(jìn)行規(guī)范:只考慮延長(zhǎng)線通過(guò)原點(diǎn)的那個(gè)法向量p��。這樣的話�,只要求出法向量p���,就可以唯一確認(rèn)這條分界線��,這個(gè)分類(lèi)問(wèn)題就解決了���。
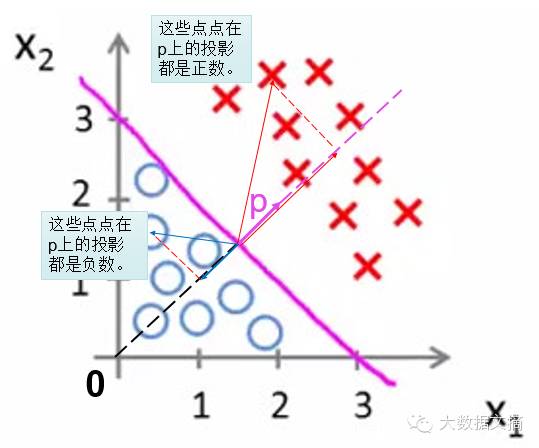

還有什么方法能將法向量p的性質(zhì)處理地更好呢?
因?yàn)橛?jì)算各個(gè)點(diǎn)到法向量p投影���,需要先知道p的起點(diǎn)的位置����,而起點(diǎn)的位置確定起來(lái)很麻煩,我們就干脆將法向量平移使其起點(diǎn)落在坐標(biāo)系的原點(diǎn)�,成為新向量p’。因此���,所有點(diǎn)到p’的投影也就變化了一個(gè)常量��。
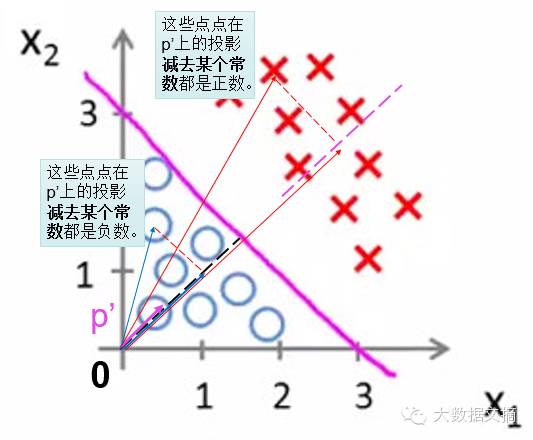

假設(shè)這個(gè)常量為
�,p’向量的橫縱坐標(biāo)為
�。空間中任何一個(gè)點(diǎn)
到p’的投影就是
��,再加上前面的常量值就是:
看到上面的式子有沒(méi)有感到很熟悉����?這不就是邏輯回歸函數(shù)
中括號(hào)里面的部分嗎?
令
就可以根據(jù)z的正負(fù)號(hào)來(lái)判斷點(diǎn)x的類(lèi)別了�。
“
從概率角度理解z的含義。
由以上步驟���,我們由點(diǎn)x的坐標(biāo)得到了一個(gè)新的特征z�����,那么:
z的現(xiàn)實(shí)意義是什么呢�?
首先,我們知道�,z可正可負(fù)可為零。而且����,z的變化范圍可以一直到正負(fù)無(wú)窮大。
z如果大于0����,則點(diǎn)x屬于y=1的類(lèi)別。而且z的值越大���,說(shuō)明它距離分界線的距離越大,更可能屬于y=1類(lèi)����。
那可否把z理解成點(diǎn)x屬于y=1類(lèi)的概率P(y=1|x) (下文簡(jiǎn)寫(xiě)成P)呢?顯然不夠理想�,因?yàn)楦怕实姆秶?到1的。
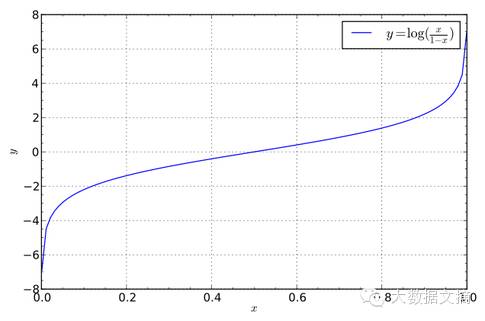
但是我們可以將概率P稍稍改造一下:令Q=P/(1-P)����,期望用Q作為z的現(xiàn)實(shí)意義��。我們發(fā)現(xiàn)��,當(dāng)P的在區(qū)間[0,1]變化時(shí)��,Q在[0,+∞)區(qū)間單調(diào)遞增��。函數(shù)圖像如下(以下圖像可以直接在度娘中搜“x/(1-x)”�,超快):
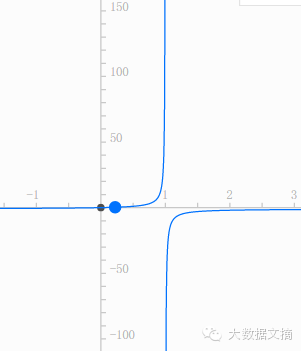
但是Q的變化率在[0,+∞)還不夠����,我們是希望能在(-∞,+∞)區(qū)間變化的。而且在P=1/2的時(shí)候剛好是0�����。這樣才有足夠的解釋力����。
注:因?yàn)镻=1/2說(shuō)明該點(diǎn)屬于兩個(gè)類(lèi)別的可能性相當(dāng),也就是說(shuō)這個(gè)點(diǎn)恰好在分界面上�,那它在法向量的投影自然就是0了。
而在P=1/2時(shí)���,Q=1�����,距離Q=0還有一段距離�。那怎么通過(guò)一個(gè)函數(shù)變換然它等于0呢?有一個(gè)天然的函數(shù)log����,剛好滿足這個(gè)要求。
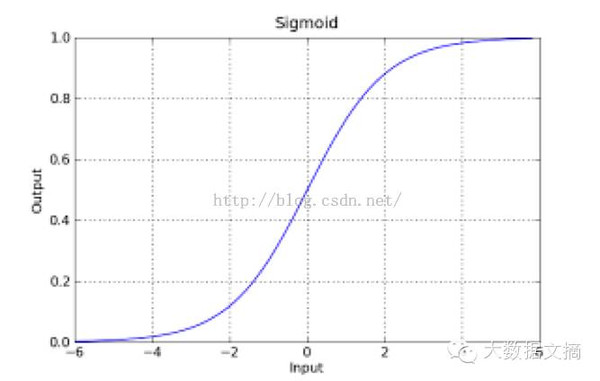
于是我們做變換R=log(Q)=log(P/(1-P))�,期望用R作為z的現(xiàn)實(shí)意義。畫(huà)出它的函數(shù)圖像如圖:
這個(gè)函數(shù)在區(qū)間[0,1]中可正可負(fù)可為零��,單調(diào)地在(-∞,+∞)變化�����,而且1/2剛好就是唯一的0值!基本完美滿足我們的要求���。
回到我們本章最初的問(wèn)題����,
“我們由點(diǎn)x的坐標(biāo)得到了一個(gè)新的特征z,那么z的具體意義是什么呢��?”
由此�����,我們就可以將z理解成x屬于y=1類(lèi)的概率P經(jīng)過(guò)某種變換后對(duì)應(yīng)的值���。也就是說(shuō)��,z= log(P/(1-P))���。反過(guò)來(lái)就是P=
。圖像如下:
這兩個(gè)函數(shù)log(P/(1-P)) ���、
看起來(lái)熟不熟悉���?
這就是傳說(shuō)中的logit函數(shù)和sigmoid函數(shù)!
小小補(bǔ)充一下:
在概率理論中,Q=P/(1-P)的意義叫做賠率(odds)����。世界杯賭過(guò)球的同學(xué)都懂哈。賠率也叫發(fā)生比,是事件發(fā)生和不發(fā)生的概率比�����。
而z= log(P/(1-P))的意義就是對(duì)數(shù)賠率或者對(duì)數(shù)發(fā)生比(log-odds)�。
于是,我們不光得到了z的現(xiàn)實(shí)意義�,還得到了z映射到概率P的擬合方程:
有了概率P,我們順便就可以拿擬合方程P=
來(lái)判斷點(diǎn)x所屬的分類(lèi):
當(dāng)P>=1/2的時(shí)候�,就判斷點(diǎn)x屬于y=1的類(lèi)別;當(dāng)P<1/2�����,就判斷點(diǎn)x屬于y=0的類(lèi)別�。
“構(gòu)造代價(jià)函數(shù)求出參數(shù)的值
到目前為止我們就有兩個(gè)判斷某點(diǎn)所屬分類(lèi)的辦法,一個(gè)是判斷z是否大于0��,一個(gè)是判斷g(z)是否大于1/2�����。
然而這并沒(méi)有什么X用����,
以上的分析都是基于“假設(shè)我們已經(jīng)找到了這條線”的前提得到的,但是最關(guān)鍵的
三個(gè)參數(shù)仍未找到有效的辦法求出來(lái)�����。
還有沒(méi)有其他的性質(zhì)可供我們利用來(lái)求出參數(shù)
的值��?
我們漏了一個(gè)關(guān)鍵的性質(zhì):這些樣本點(diǎn)已經(jīng)被標(biāo)注了y=0或者y=1的類(lèi)別!
我們一方面可以基于z是否大于0或者g(z) 是否大于1/2來(lái)判斷一個(gè)點(diǎn)的類(lèi)別����,另一方又可以依據(jù)這些點(diǎn)已經(jīng)被標(biāo)注的類(lèi)別與我們預(yù)測(cè)的類(lèi)別的插值來(lái)評(píng)估我們預(yù)測(cè)的好壞。
這種衡量我們?cè)谀辰M參數(shù)下預(yù)估的結(jié)果和實(shí)際結(jié)果差距的函數(shù)�����,就是傳說(shuō)中的代價(jià)函數(shù)Cost Function����。
當(dāng)代價(jià)函數(shù)最小的時(shí)候,相應(yīng)的參數(shù)
就是我們希望的最優(yōu)解��。
由此可見(jiàn)��,設(shè)計(jì)一個(gè)好的代價(jià)函數(shù)����,將是我們處理好分類(lèi)問(wèn)題的關(guān)鍵。而且不同的代價(jià)函數(shù),可能會(huì)有不同的結(jié)果����。因此更需要我們將代價(jià)函數(shù)設(shè)計(jì)得解釋性強(qiáng),有現(xiàn)實(shí)針對(duì)性�。
為了衡量“預(yù)估結(jié)果和實(shí)際結(jié)果的差距”,我們首先要確定“預(yù)估結(jié)果”和“實(shí)際結(jié)果”是什么���。
“實(shí)際結(jié)果”好確定���,就是y=0還是y=1。
“預(yù)估結(jié)果”有兩個(gè)備選方案�����,經(jīng)過(guò)上面的分析�����,我們可以采用z或者g(z)�����。但是顯然g(z)更好�,因?yàn)間(z)的意義是概率P���,剛好在[0,1]范圍之間,與實(shí)際結(jié)果{0��,1}很相近��,而z的意思是邏輯發(fā)生比�,范圍是整個(gè)實(shí)數(shù)域(-∞,+∞)��,不太好與y={0��,1}進(jìn)行比較�。
接下來(lái)是衡量?jī)蓚€(gè)結(jié)果的“差距”。
我們首先想到的是y-hθ(x)����。
但這是當(dāng)y=1的時(shí)候比較好。如果y=0�����,則y- hθ(x)= - hθ(x)是負(fù)數(shù)����,不太好比較�����,則采用其絕對(duì)值hθ(x)即可����。綜合表示如下:
但這個(gè)函數(shù)有個(gè)問(wèn)題:求導(dǎo)不太方便��,進(jìn)而用梯度下降法就不太方便��。
因?yàn)樘荻认陆捣ǔ龅某醯葦?shù)學(xué)的范圍���,這里就暫且略去不解釋了���。
于是對(duì)上面的代價(jià)函數(shù)進(jìn)行了簡(jiǎn)單的處理,使之便于求導(dǎo)����。結(jié)果如下:

代價(jià)函數(shù)確定了,接下來(lái)的問(wèn)題就是機(jī)械計(jì)算的工作了��。常見(jiàn)的方法是用梯度下降法�。于是,我們的平面線形可分的問(wèn)題就可以說(shuō)是解決了�����。
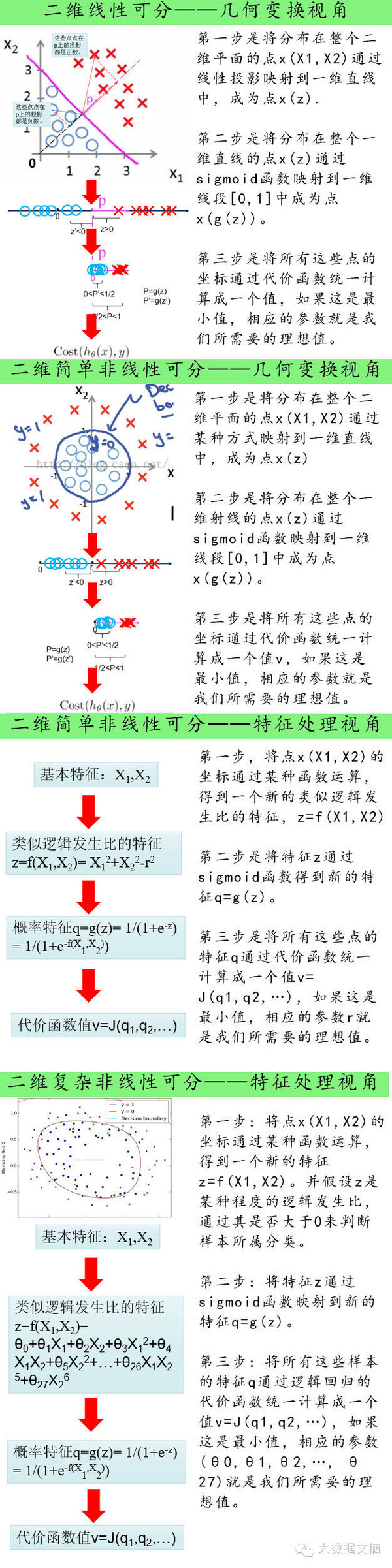
“從幾何變換的角度重新梳理我們剛才的推理過(guò)程。
回顧我們的推理過(guò)程�,我們其實(shí)是在不斷地將點(diǎn)
進(jìn)行幾何坐標(biāo)變換的過(guò)程。
第一步是將分布在整個(gè)二維平面的點(diǎn)
通過(guò)線性投影映射到一維直線中���,成為點(diǎn)x(z)
第二步是將分布在整個(gè)一維直線的點(diǎn)x(z)通過(guò)sigmoid函數(shù)映射到一維線段[0,1]中成為點(diǎn)x(g(z))。
第三步是將所有這些點(diǎn)的坐標(biāo)通過(guò)代價(jià)函數(shù)統(tǒng)一計(jì)算成一個(gè)值���,如果這是最小值�����,相應(yīng)的參數(shù)就是我們所需要的理想值�。
“對(duì)于簡(jiǎn)單的非線性可分的問(wèn)題��。
由以上分析可知����。比較關(guān)鍵的是第一步,我們之所以能夠這樣映射是因?yàn)榧僭O(shè)我們點(diǎn)集是線性可分的���。但是如果分離邊界是一個(gè)圓呢���?考慮以下情況���。
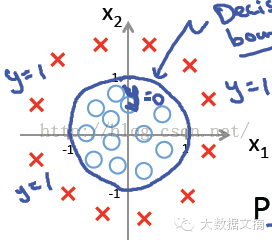
我們?nèi)杂媚嫱品ǖ乃悸罚?/span>
通過(guò)觀察可知,分離邊界如果是一個(gè)圓比較合理����。
假設(shè)我們已經(jīng)找到了這個(gè)圓,再尋找這個(gè)圓的性質(zhì)是什么���。根據(jù)這些性質(zhì)�,再來(lái)反推這個(gè)圓的方程���。
我們可以依據(jù)這個(gè)性質(zhì):
圓內(nèi)的點(diǎn)到圓心的距離小于半徑��,圓外的點(diǎn)到圓心的距離大于半徑
假設(shè)圓的半徑為r���,空間中任何一個(gè)點(diǎn)
到原點(diǎn)的距離為
。
令
����,就可以根據(jù)z的正負(fù)號(hào)來(lái)判斷點(diǎn)x的類(lèi)別了
然后令
,就可以繼續(xù)依靠我們之前的邏輯回歸的方法來(lái)處理和解釋問(wèn)題了�����。
從幾何變換的角度重新梳理我們剛才的推理過(guò)程。
第一步是將分布在整個(gè)二維平面的點(diǎn)
通過(guò)某種方式映射到一維直線中���,成為點(diǎn)x(z)
第二步是將分布在整個(gè)一維射線的點(diǎn)x(z)通過(guò)sigmoid函數(shù)映射到一維線段[0,1]中成為點(diǎn)x(g(z))�����。
第三步是將所有這些點(diǎn)的坐標(biāo)通過(guò)代價(jià)函數(shù)統(tǒng)一計(jì)算成一個(gè)值v��,如果這是最小值,相應(yīng)的參數(shù)就是我們所需要的理想值����。
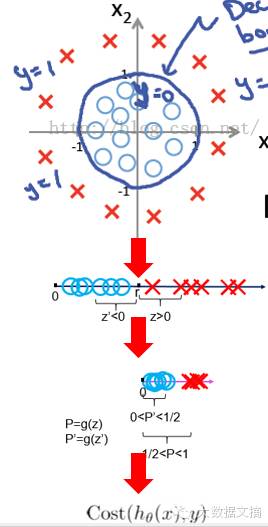
“從特征處理的角度重新梳理我們剛才的分析過(guò)程
其實(shí),做數(shù)據(jù)挖掘的過(guò)程����,也可以理解成做特征處理的過(guò)程。我們典型的數(shù)據(jù)挖掘算法�����,也就是將一些成熟的特征處理過(guò)程給固定化的結(jié)果��。
對(duì)于邏輯回歸所處理的分類(lèi)問(wèn)題,我們已有的特征是這些點(diǎn)的坐標(biāo)
���,我們的目標(biāo)就是判斷這些點(diǎn)所屬的分類(lèi)y=0還是y=1���。那么最理想的想法就是希望對(duì)坐標(biāo)
進(jìn)行某種函數(shù)運(yùn)算,得到一個(gè)(或者一些)新的特征z��,基于這個(gè)特征z是否大于0來(lái)判斷該樣本所屬的分類(lèi)����。
對(duì)我們上一節(jié)非線性可分問(wèn)題的推理過(guò)程進(jìn)行進(jìn)一步抽象��,我們的思路其實(shí)是:
第一步����,將點(diǎn)
的坐標(biāo)通過(guò)某種函數(shù)運(yùn)算,得到一個(gè)新的類(lèi)似邏輯發(fā)生比的特征��,
第二步是將特征z通過(guò)sigmoid函數(shù)得到新的特征
���。
第三步是將所有這些點(diǎn)的特征q通過(guò)代價(jià)函數(shù)統(tǒng)一計(jì)算成一個(gè)值
�,如果這是最小值,相應(yīng)的參數(shù)(r)就是我們所需要的理想值��。
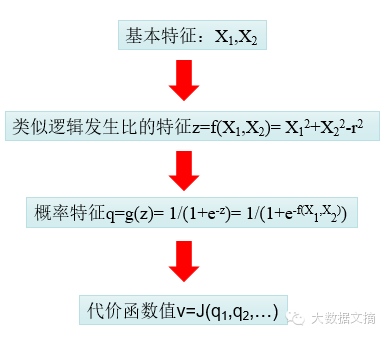
“對(duì)于復(fù)雜的非線性可分的問(wèn)題
由以上分析可知����。比較關(guān)鍵的是第一步,如何設(shè)計(jì)轉(zhuǎn)換函數(shù)
����。我們現(xiàn)在開(kāi)始考慮分離邊界是一個(gè)極端不規(guī)則的曲線的情況。
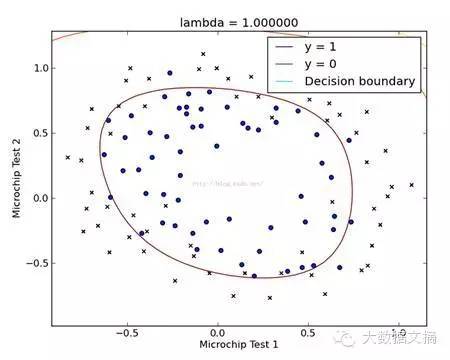
我們?nèi)杂媚嫱品ǖ乃悸罚?/span>
通過(guò)觀察等先驗(yàn)的知識(shí)(或者完全不觀察亂猜)�,我們可以假設(shè)分離邊界是某種6次曲線(這個(gè)曲線方程可以提前假設(shè)得非常復(fù)雜����,對(duì)應(yīng)著各種不同的情況)��。
第一步:將點(diǎn)
的坐標(biāo)通過(guò)某種函數(shù)運(yùn)算���,得到一個(gè)新的特征
����。并假設(shè)z是某種程度的邏輯發(fā)生比����,通過(guò)其是否大于0來(lái)判斷樣本所屬分類(lèi)�����。
第二步:將特征z通過(guò)sigmoid函數(shù)映射到新的特征
第三步:將所有這些樣本的特征q通過(guò)邏輯回歸的代價(jià)函數(shù)統(tǒng)一計(jì)算成一個(gè)值
�,如果這是最小值,相應(yīng)的參數(shù)
就是我們所需要的理想值���。相應(yīng)的,分離邊界其實(shí)就是方程
=0��,也就是邏輯發(fā)生比為0的情況嘛�����。
“多維邏輯回歸的問(wèn)題
以上考慮的問(wèn)題都是基于在二維平面內(nèi)進(jìn)行分類(lèi)的情況����。其實(shí),對(duì)于高維度情況的分類(lèi)也類(lèi)似����。
高維空間的樣本���,其區(qū)別也只是特征坐標(biāo)更多,比如四維空間的點(diǎn)x的坐標(biāo)為
��。但直接運(yùn)用上文特征處理的視角來(lái)分析�,不過(guò)是對(duì)坐標(biāo)
進(jìn)行參數(shù)更多的函數(shù)運(yùn)算得到新的特征
。并假設(shè)z是某種程度的邏輯發(fā)生比����,通過(guò)其是否大于0來(lái)判斷樣本所屬分類(lèi)。
而且����,如果是高維線性可分的情況,則可以有更近直觀的理解�。
如果是三維空間,分離邊界就是一個(gè)空間中的一個(gè)二維平面�����。兩類(lèi)點(diǎn)在這個(gè)二維平面的法向量p上的投影的值的正負(fù)號(hào)不一樣����,一類(lèi)點(diǎn)的投影全是正數(shù),另一類(lèi)點(diǎn)的投影值全是負(fù)數(shù)�。
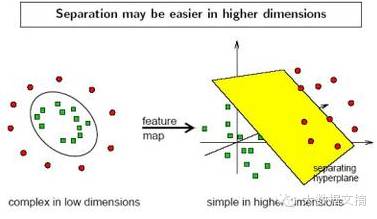
如果是高維空間,分離邊界就是這個(gè)空間中的一個(gè)超平面����。兩類(lèi)點(diǎn)在這個(gè)超平面的法向量p上的投影的值的正負(fù)號(hào)不一樣,一類(lèi)點(diǎn)的投影全是正數(shù)����,另一類(lèi)點(diǎn)的投影值全是負(fù)數(shù)。
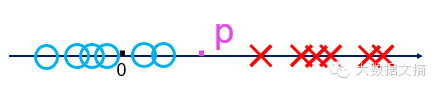
特殊的���,如果是一維直線空間����,分離邊界就是直線上的某一點(diǎn)p��。一類(lèi)點(diǎn)在點(diǎn)p的正方向上�,另一類(lèi)點(diǎn)在點(diǎn)p的負(fù)方向上。這些點(diǎn)在直線上的坐標(biāo)可以天然理解成類(lèi)似邏輯發(fā)生比的情況���?�?梢?jiàn)一維直線空間的分類(lèi)問(wèn)題是其他所有高維空間投影到法向量后的結(jié)果����,是所有邏輯回歸問(wèn)題的基礎(chǔ)。
“多分類(lèi)邏輯回歸的問(wèn)題
以上考慮的問(wèn)題都是二分類(lèi)的問(wèn)題�,基本就是做判斷題。但是對(duì)于多分類(lèi)的問(wèn)題���,也就是做選擇題���,怎么用邏輯回歸處理呢?

其基本思路也是二分類(lèi)���,做判斷題��。
比如你要做一個(gè)三選一的問(wèn)題�,有ABC三個(gè)選項(xiàng)��。首先找到A與BUC(”U”是并集符號(hào))的分離邊界����。然后再找B與AUC的分離邊界,C與AUB的分離邊界��。
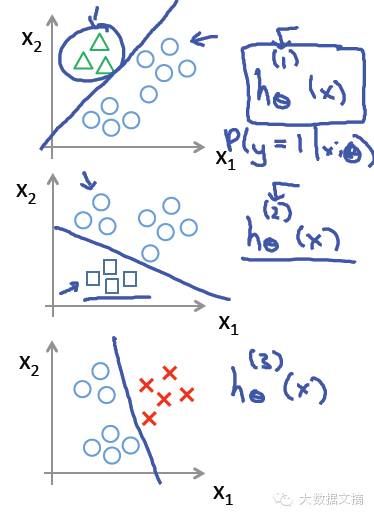
這樣就能分別得到屬于A�、B、C三類(lèi)的概率��,綜合比較���,就能得出概率最大的那一類(lèi)了���。
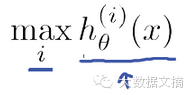
“總結(jié)
本文的分析思路——逆推法
畫(huà)圖,觀察數(shù)據(jù)����,看出(猜出)規(guī)律,假設(shè)規(guī)律存在��,用數(shù)學(xué)表達(dá)該規(guī)律�,求出相應(yīng)數(shù)學(xué)表達(dá)式。
該思路比較典型����,是數(shù)據(jù)挖掘過(guò)程中的常見(jiàn)思路。
兩個(gè)視角:幾何變換的視角與特征處理的視角�。
小結(jié):
幾何變換的視角:高維空間映射到一維空間 → 一維空間映射到[0,1]區(qū)間 → [0,1]區(qū)間映射到具體的值,求最優(yōu)化解
特征處理的視角:特征運(yùn)算函數(shù)求特征單值z(mì) → sigmoid函數(shù)求概率 → 代價(jià)函數(shù)求代價(jià)評(píng)估值����,求最優(yōu)化解
首先要說(shuō)明的是�,在邏輯回歸的問(wèn)題中�����,這兩個(gè)視角是并行的�����,而不是包含關(guān)系���。它們是同一個(gè)數(shù)學(xué)過(guò)程的兩個(gè)方面�。
比如���,我們后來(lái)處理復(fù)雜的非線性可分問(wèn)題的時(shí)候�,看似只用的是特征處理的思路���。其實(shí)�,對(duì)于復(fù)雜的非線性分離邊界����,也可以映射到高維空間進(jìn)行線性可分的處理。在SVM中,有時(shí)候某些核函數(shù)所做的映射與之非常類(lèi)似����。這將在我們接下來(lái)的SVM系列文章中有更加詳細(xì)的說(shuō)明。
在具體的分析過(guò)程中�,運(yùn)用哪種視角都可以��,各有優(yōu)點(diǎn)��。
比如����,作者個(gè)人比較傾向幾何變換的視角來(lái)理解,這方便記憶整個(gè)邏輯回歸的核心過(guò)程��,畫(huà)幾張圖就夠了�����。相應(yīng)的信息都濃縮在圖像里面���,異常清晰�����。
于此同時(shí)���,特征處理的視角方便你思考你手上掌握的特征是什么����,怎么處理這些特征����。這其實(shí)的數(shù)據(jù)挖掘的核心視角。因?yàn)殡S著理論知識(shí)和工作經(jīng)驗(yàn)的積累�����,越到后面越會(huì)發(fā)現(xiàn)��,當(dāng)我們已經(jīng)拿到無(wú)偏差���、傾向性的數(shù)據(jù)集����,并且做過(guò)數(shù)據(jù)清洗之后���,特征處理的過(guò)程是整個(gè)數(shù)據(jù)挖掘的核心過(guò)程:怎么收集這些特征��,怎么識(shí)別這些特征����,挑選哪些特征,舍去哪些特征���,如何評(píng)估不同的特征……這些過(guò)程都是對(duì)你算法結(jié)果有決定性影響的極其精妙的精妙部分��。這是一個(gè)龐大的特征工程����,里面的內(nèi)容非常龐大��,我們將在后續(xù)的系列文章中專(zhuān)門(mén)討論����。
總的來(lái)說(shuō)��,幾何變換視角更加直觀具體�����,特征處理視角更加抽象宏觀����,在實(shí)際分析過(guò)程中�,掌握著兩種視角的內(nèi)在關(guān)系和轉(zhuǎn)換規(guī)律�,綜合分析,將使得你對(duì)整個(gè)數(shù)據(jù)挖掘過(guò)程有更加豐富和深刻的認(rèn)識(shí)�����。
為了將這兩種視角更集中地加以對(duì)比�,我們專(zhuān)門(mén)制作了下面的圖表,方便讀者查閱�����。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試���,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情�����;
? 想學(xué)習(xí)CDA考試教材����,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫(kù)�����,點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情�;
? 想了解CDA考試含金量�����,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330