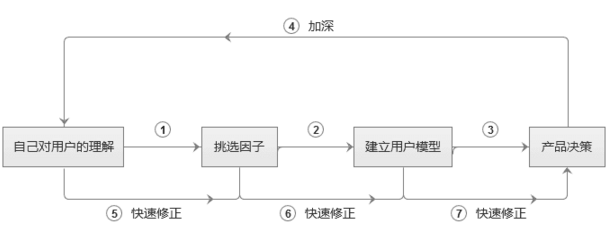
如何快速建立用戶模型��,輔助產(chǎn)品決策
用戶模型目前還沒有一個(gè)統(tǒng)一的定義�����,狹義地講:用戶模型是對網(wǎng)站目標(biāo)群體真實(shí)特征的勾勒���,是真實(shí)用戶的虛擬代表�。建立用戶模型的目的是:盡量減少主觀臆測����,走近用戶,理解他們真正需要什么���,從而知道如何更好的為不同類型用戶服務(wù)����。
交互設(shè)計(jì)之父Alan Cooper提出了兩種構(gòu)建用戶模型的方法:
傳統(tǒng)用戶模型:基于對用戶的訪談和觀察等研究結(jié)果建立�,嚴(yán)謹(jǐn)可靠但費(fèi)時(shí)。
臨時(shí)用戶模型:基于行業(yè)專家或市場調(diào)查數(shù)據(jù)對用戶的理解建立��,快速但容易有偏頗。
傳統(tǒng)的用戶研究方式�,選取的因子比較全面,涵蓋用戶基本屬性��、行為特征等�,要進(jìn)行用戶訪談、問卷等�,得到的調(diào)研結(jié)果雖然比較準(zhǔn)確,但花費(fèi)的時(shí)間往往比較長�����。對追求小步快跑的公司來說��,時(shí)間太寶貴了����,等花費(fèi)幾個(gè)月得出報(bào)告時(shí),可能就已經(jīng)錯(cuò)失良機(jī)了�。
所以,我們可以考慮建立臨時(shí)用戶模型����。根據(jù)自己對用戶的理解,挑選出最影響用戶和產(chǎn)品的幾個(gè)因子來做分析�����,快速建立用戶模型���,輔助產(chǎn)品決策�����。
快速建立用戶模型的方法:
本文以“人人都是產(chǎn)品經(jīng)理”為例來逐步說明如何快速建立用戶模型�。
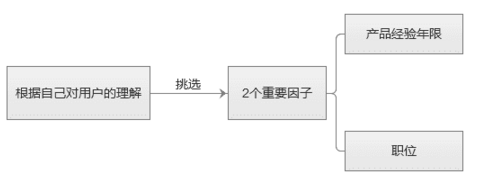
1. 挑選合適的因子�,劃分用戶群
因子:即建立用戶模型時(shí),用來劃分用戶群體的用戶屬性����,如年齡、性別����、收入、職業(yè)等�。
挑選合適的因子
本次用研目的:了解“人人都是產(chǎn)品經(jīng)理”非UGC用戶的閱讀偏好。選擇因子:
劃分用戶群
當(dāng)你選好因子后���,需要對用戶群進(jìn)行一個(gè)簡單的劃分����,這些用戶群是進(jìn)一步研究的基礎(chǔ)。
在“人人都是產(chǎn)品經(jīng)理”中��,以“產(chǎn)品經(jīng)驗(yàn)?zāi)晗蕖卑延脩魟澐譃?類:
劃分出來后����,看下結(jié)果是否符合自己的預(yù)期。如果不符合預(yù)期的話���,需要不斷地調(diào)整因子����,直至劃分出來的結(jié)果是自己預(yù)期的典型用戶�����。如果你不太了解典型用戶是哪些的話��,可以問問周圍的人�,大致確定下典型用戶的特征。
在這四類人群中��,每一類都是一個(gè)用戶群的代表���,通過自己對用戶群的了解或從身邊找一些典型的用戶���,然后對號(hào)入座�����,就可以明顯地看出這個(gè)用戶群是怎么樣的。
接下來�,需要對劃分的用戶群進(jìn)行逐個(gè)分析,加入一些相關(guān)的信息��、行為特征等��,比如:加入用戶的職位���、使用場景�����、目的等來豐富用戶畫像����,進(jìn)而搭建起用戶模型����。
2. 建立臨時(shí)用戶模型
第一類用戶群:想從事產(chǎn)品方面的工作�,實(shí)習(xí)或剛畢業(yè)的大學(xué)生���,從其他崗位轉(zhuǎn)到產(chǎn)品相關(guān)崗位的人�。這類人群���,逛社區(qū)的頻次很高���,哪里有好的內(nèi)容就去哪里,主要是閱讀類用戶��,不太自己創(chuàng)造內(nèi)容�����,對社區(qū)沒有形成強(qiáng)烈的忠誠度���。
第二類用戶群:從事產(chǎn)品相關(guān)工作1-3年的人�,對產(chǎn)品���、交互�����、運(yùn)營等方面有一定的了解�����,正處于成長期���,需要學(xué)習(xí)大量的知識(shí)打牢基礎(chǔ),拓展視野����,部分人群已經(jīng)對有些社區(qū)形成了一定的忠誠度,主要精力會(huì)集中在某一個(gè)或幾個(gè)社區(qū)上���,不會(huì)漫無目標(biāo)的亂逛了���。
第三類用戶群:部分已經(jīng)開始帶個(gè)小團(tuán)隊(duì)做項(xiàng)目,比普通產(chǎn)品經(jīng)理位高一級(jí)��,BAT等大公司除外����。這時(shí)的目標(biāo)�����,主要是向著更高層次的權(quán)力中心邁進(jìn)�,在PM社區(qū)內(nèi)�����,開始嘗試分享經(jīng)驗(yàn)���,指導(dǎo)他人����,為大家答疑解惑�����,主動(dòng)創(chuàng)造內(nèi)容����,不太以閱讀為主。
第四類用戶群:產(chǎn)品相關(guān)工作干了5年以上����,多數(shù)已經(jīng)是產(chǎn)品總監(jiān)或創(chuàng)業(yè)公司的CEO等�,逛社區(qū)主要是為了自我營銷�����、公司品牌營銷�、招人,提升在圈內(nèi)的影響力等�����,比如各領(lǐng)域大V��,基本不是閱讀用戶�。
通過上面的分析���,我們會(huì)發(fā)現(xiàn)���,第三和第四類用戶,基本已經(jīng)對社區(qū)形成了一定的忠誠度�,主動(dòng)創(chuàng)造內(nèi)容,吸引粉絲用戶�,往往已經(jīng)是“人人都是產(chǎn)品經(jīng)理”的一些意見領(lǐng)袖。
劃分出這些用戶群之后�,我們要看看�,哪些可能是未來的增量市場��,是需要重點(diǎn)去抓的人群����。“人人都是產(chǎn)品經(jīng)理”的專欄作家已經(jīng)非常多了���,文章內(nèi)容上已能足夠支撐��,那就需要把重點(diǎn)放在想要從事產(chǎn)品工作和剛從事產(chǎn)品工作不久的第一和第二類人群上�����,這兩類人群�����,數(shù)量比較龐大����,對PM社區(qū)的忠誠度還不夠高�,比較容易去爭取。
本次用研目的,主要也是為了了解“人人都是產(chǎn)品經(jīng)理”非UGC用戶的閱讀偏好�,接下來,我們需要對這兩類人群進(jìn)行用戶訪談�����,驗(yàn)證用戶模型的可行性����。
3. 用戶訪談驗(yàn)證
由于臨時(shí)用戶模型,更多的是基于自己對用戶的理解建立的����,雖然快速但卻容易形成偏差。所以����,我們需要通過用戶訪談來簡單驗(yàn)證下。
用戶訪談:是一種定性的研究方法��,用于定位問題����,挖掘問題背后的用戶需求�����。通常有兩種目的:發(fā)現(xiàn)真實(shí)問題、尋找正確方案��。
用戶訪談的步驟:
簡單來說���,用戶訪談就是要:從淺入深��,由表及里��。
用戶訪談的方法:
1)破冰�����。像聊天一樣����,生活化的提問���,從簡單問題開始鋪墊����,建立訪談氛圍��。
2)開放式地提問。比如:你覺得這個(gè)功能有哪些地方吸引你���?而不是封閉式的問用戶�����,你喜歡這個(gè)功能嗎��?
3)關(guān)注用戶過去和現(xiàn)在的真實(shí)感受�����。以及用戶的非語言信息�,包括肢體語言���,語音語調(diào)等�。
4)一次只問一個(gè)問題�。用戶回答后,嘗試連貫地追問�,并重復(fù)確認(rèn)自己是否理解用戶的回答。
用戶訪談的注意要點(diǎn):
1)不要問過于開放���、過于模糊的問題。比如:你覺得人人都是產(chǎn)品經(jīng)理網(wǎng)站怎么樣?模糊的問題可能得到的是用戶模糊的回答�,比如:很好啊。
2)避免帶有傾向性的提問��。比如:你喜歡這個(gè)功能嗎�����?多多少少會(huì)對用戶的回答產(chǎn)生暗示或影響��。
3)傾聽��,不要隨意打斷用戶�����。在被訪者遠(yuǎn)離問題時(shí)����,需要巧妙打斷,引回話題��。打斷較常用的一種方式是:重復(fù)一次被訪者的回答�,表示認(rèn)同,然后再重新提問����。
4)關(guān)注用戶遇到的問題�,而不是用戶的解決方案���。很多時(shí)候�����,用戶在給出答案時(shí)會(huì)直接說你這個(gè)功能應(yīng)該怎么做����,我們需要關(guān)注的是用戶在使用這個(gè)功能中遇到的一些問題��,以及造成這些問題的原因��,而不是用戶說怎么做就怎么做����。
舉個(gè)例子。
了解“人人都是產(chǎn)品經(jīng)理”前兩類用戶的閱讀偏好時(shí)��,問題設(shè)計(jì)(僅供參考):
1)開場白�����,了解用戶的基本信息,比如年齡�、職位等�。
2)您一般會(huì)在什么場景下閱讀“人人都是產(chǎn)品經(jīng)理”上的文章?(了解用戶使用場景)
3)您重點(diǎn)關(guān)注哪些方面的內(nèi)容��?(了解用戶閱讀偏好)
4)您為什么逛“人人都是產(chǎn)品經(jīng)理”呢��?(探尋用戶的目的)
5)您覺得哪些功能做的不太好�?(了解產(chǎn)品可改進(jìn)的方向)
6)您覺得還有哪些功能需要加進(jìn)來?(了解用戶對產(chǎn)品的未來期待)
7)為什么需要加入這些功能呢�����?(探尋需求背后的動(dòng)機(jī))
…
為了保護(hù)被訪者的個(gè)人隱私�����,這里就不貼出他們的具體答案了��。
4. 修正用戶模型���,輔助產(chǎn)品決策
通過和7位用戶的具體訪談���,基本驗(yàn)證上面的用戶模型偏離性不是很大�。
本次用研的分析結(jié)論如下�。
1)無經(jīng)驗(yàn)產(chǎn)品新人,主要閱讀偏好為:
熱點(diǎn)分析����、競品分析、需求分析�、原型設(shè)計(jì)、產(chǎn)品設(shè)計(jì)���。
對前輩的工作經(jīng)歷和經(jīng)驗(yàn)分享的了解�����。
知曉一些該行業(yè)的名人�,希望融入圈子��。
希望了解如何學(xué)習(xí)產(chǎn)品知識(shí)的方法�����。
如何應(yīng)聘產(chǎn)品崗位或順利轉(zhuǎn)崗�。
2)從事產(chǎn)品相關(guān)工作1-3年的人,主要閱讀偏好為:
用戶研究、數(shù)據(jù)分析���、產(chǎn)品策劃�����、產(chǎn)品運(yùn)營、心理學(xué)等�。
跟自己目前工作內(nèi)容有關(guān)的知識(shí)。
洞察用戶心理:
在這兩個(gè)階段���,用戶更多表現(xiàn)出來的是求知欲���、從眾心理、懶人心理和尋求歸屬感���。
要了解一個(gè)新領(lǐng)域����,需要迫切學(xué)習(xí)到這方面的知識(shí)����,有著極強(qiáng)的求知欲望;關(guān)注該領(lǐng)域的大咖����,翻閱他們的文章以及了解大咖們都在關(guān)注什么���,從眾心理明顯;想要盡快融入圈子���,證明用戶在尋找歸屬感�;關(guān)注自己感興趣的內(nèi)容���,其實(shí)用戶是想可以高效找到自己需要的內(nèi)容�。
當(dāng)用戶為在職產(chǎn)品人后�����,就需要關(guān)注一些深入點(diǎn)的知識(shí)�,擴(kuò)展知識(shí)面和知識(shí)深度,目標(biāo)感更強(qiáng)���,對信息的篩選要求會(huì)更高���,并已經(jīng)建立了一定的個(gè)人圈子,更想結(jié)交更高層次的產(chǎn)品人。
表現(xiàn)出來的需求是:
希望可以快速獲取對自己有價(jià)值的內(nèi)容�;
可以關(guān)注自己喜歡的大咖專欄;
有良好的社區(qū)氛圍����;
結(jié)交更多志同道合的人一起交流學(xué)習(xí)等。
可滿足需求的功能:
測試閱讀口味����、個(gè)性化定制,分類���、搜索,熱門文章排行榜�����,關(guān)注功能��,問答版塊等�。
5. 總結(jié)
重申一次快速建立用戶模型的步驟:
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情����;
? 想學(xué)習(xí)CDA考試教材,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫���,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量���,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情�;


















 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營許可證編號(hào):京B2-20210330