面向高維度的機(jī)器學(xué)習(xí)的計(jì)算框架-Angel
為支持超大維度機(jī)器學(xué)習(xí)模型運(yùn)算��,騰訊數(shù)據(jù)平臺部與香港科技大學(xué)合作開發(fā)了面向機(jī)器學(xué)習(xí)的分布式計(jì)算框架——Angel 1.0。
Angel是使用Java語言開發(fā)的專有機(jī)器學(xué)習(xí)計(jì)算系統(tǒng)�,用戶可以像用Spark, MapReduce一樣����,用它來完成機(jī)器學(xué)習(xí)的模型訓(xùn)練。Angel已經(jīng)支持了SGD��、ADMM優(yōu)化算法����,同時(shí)我們也提供了一些常用的機(jī)器學(xué)習(xí)模型;但是如果用戶有自定義需求��,也可以在我們提供的最優(yōu)化算法上層比較容易地封裝模型。
Angel應(yīng)用香港科技大學(xué)的Chukonu 作為網(wǎng)絡(luò)解決方案��, 在高維度機(jī)器學(xué)習(xí)的參數(shù)更新過程中�����,有針對性地給滯后的計(jì)算任務(wù)的參數(shù)傳遞提速�����,整體上縮短機(jī)器學(xué)習(xí)算法的運(yùn)算時(shí)間���。這一創(chuàng)新采用了香港科技大學(xué)陳凱教授及其研究小組開發(fā)的可感知上層應(yīng)用(Application-aware)的網(wǎng)絡(luò)優(yōu)化方案�,以及楊強(qiáng)教授領(lǐng)導(dǎo)的的大規(guī)模機(jī)器學(xué)習(xí)研究方案���。
另外�����,北京大學(xué)崔斌教授及其學(xué)生也共同參與了Angel項(xiàng)目的研發(fā)�����。
在實(shí)際的生產(chǎn)任務(wù)中�����,Angel在千萬級到億級的特征緯度條件下運(yùn)行SGD����,性能是成熟的開源系統(tǒng)Spark的數(shù)倍到數(shù)十倍不等。Angel已經(jīng)在騰訊視頻推薦�����、廣點(diǎn)通等精準(zhǔn)推薦業(yè)務(wù)上實(shí)際應(yīng)用����,目前我們正在擴(kuò)大在騰訊內(nèi)部的應(yīng)用范圍,目標(biāo)是支持騰訊等企業(yè)級大規(guī)模機(jī)器學(xué)習(xí)任務(wù)���。
整體架構(gòu)
Angel在整體架構(gòu)上參考了谷歌的DistBelief。DistBeilef最初是為深度學(xué)習(xí)而設(shè)計(jì)��,它使用了參數(shù)服務(wù)器���,以解決巨大模型在訓(xùn)練時(shí)的更新問題�����。參數(shù)服務(wù)器同樣可用于機(jī)器學(xué)習(xí)中非深度學(xué)習(xí)的模型��,如SGD����、ADMM、LBFGS的優(yōu)化算法在面臨在每輪迭代上億個(gè)參數(shù)更新的場景中��,需要參數(shù)分布式緩存來拓展性能�。Angel在運(yùn)算中支持BSP、SSP��、ASP三種計(jì)算模型�����,其中SSP是由卡耐基梅隆大學(xué)EricXing在Petuum項(xiàng)目中驗(yàn)證的計(jì)算模型���,能在機(jī)器學(xué)習(xí)的這種特定運(yùn)算場景下提升縮短收斂時(shí)間�����。系統(tǒng)有五個(gè)角色:
Master:負(fù)責(zé)資源申請和分配�,以及任務(wù)的管理��。
Task:負(fù)責(zé)任務(wù)的執(zhí)行,以線程的形式存在���。
Worker:獨(dú)立進(jìn)程運(yùn)行于Yarn的Container中���,是Task的執(zhí)行容器。
ParameterServer:隨著一個(gè)任務(wù)的啟動(dòng)而生成�����,任務(wù)結(jié)束而銷毀�,負(fù)責(zé)在該任務(wù)訓(xùn)練過程中的參數(shù)的更新和存儲。
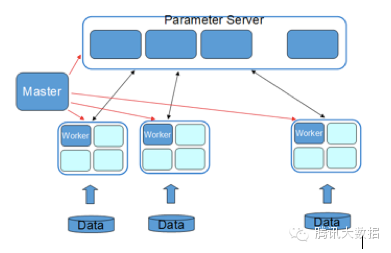
WorkerGroup為一個(gè)虛擬概念�,由若干個(gè)Worker組成,元數(shù)據(jù)由Master維護(hù)���。為模型并行拓展而考慮��,在一個(gè)WorkerGroup內(nèi)所有Worker運(yùn)行的訓(xùn)練數(shù)據(jù)都是一樣的�。雖然我們提供了一些通用模型���,但并不保證都滿足需求,而用戶自定義的模型實(shí)現(xiàn)可以實(shí)現(xiàn)我們的通用接口����,形式上等同于MapReduce或Spark�����。
1)用戶友好
1. 自動(dòng)化數(shù)據(jù)切分: Angel系統(tǒng)為用戶提供了自動(dòng)切分訓(xùn)練數(shù)據(jù)的功能�����,方便用戶進(jìn)行數(shù)據(jù)并行運(yùn)算:系統(tǒng)默認(rèn)兼容了Hadoop FS接口���,原始訓(xùn)練樣本存儲在支持Hadoop FS接口的分布式文件系統(tǒng)如HDFS、Tachyon���。
2. 豐富的數(shù)據(jù)管理:樣本數(shù)據(jù)存儲在分布式文件系統(tǒng)中�����,系統(tǒng)在計(jì)算前從文件系統(tǒng)讀取到計(jì)算進(jìn)程�����,放在緩存在內(nèi)存中以加速迭代運(yùn)算�����;如果內(nèi)存中緩存不下的數(shù)據(jù)則暫存到本地磁盤��,不需要向分布式文件系統(tǒng)再次發(fā)起通訊請求�����。
3. 豐富的線性代數(shù)及優(yōu)化算法庫: Angel更提供了高效的向量及矩陣運(yùn)算庫(稀疏/稠密)����,方便了用戶自由選擇數(shù)據(jù)、參數(shù)的表達(dá)形式���。在優(yōu)化算法方面�,Angel已實(shí)現(xiàn)了SGD����、ADMM;模型方面��,支持了Latent DirichletAllocation (LDA)�、MatrixFactorization (MF)、LogisticRegression (LR) ��、Support Vector Machine(SVM) 等�。
4. 可選擇的計(jì)算模型:綜述中我們提到了,Angel的參數(shù)服務(wù)器可以支持BSP�,SSP,ASP計(jì)算模型���。
5. 更細(xì)粒度的容錯(cuò):在系統(tǒng)中容錯(cuò)主要分為Master的容錯(cuò)�����,參數(shù)服務(wù)器的容災(zāi)���,Worker進(jìn)程內(nèi)的參數(shù)快照的緩存,RPC調(diào)用的容錯(cuò)���。
6. 友好的任務(wù)運(yùn)行及監(jiān)控: Angel也具有友好的任務(wù)運(yùn)行方式���,支持基于Yarn的任務(wù)運(yùn)行模式。同時(shí)����,Angel的Web App頁面也方便了用戶查看集群進(jìn)度。
2)參數(shù)服務(wù)器
在實(shí)際的生產(chǎn)環(huán)境中�����,可以直觀的感受到Spark的Driver單點(diǎn)更新參數(shù)和廣播的瓶頸,雖然可以通過線性拓展來減少計(jì)算時(shí)的耗時(shí)�����,但是帶來了收斂性下降的問題���,同時(shí)更嚴(yán)重的是在數(shù)據(jù)并行的運(yùn)算過程中�����,由于每個(gè)Executor都保持一個(gè)完整的參數(shù)快照���,線性拓展帶來了N x 參數(shù)快照的流量,而這個(gè)流量集中到了Driver一個(gè)節(jié)點(diǎn)上����!

從圖中看到,在機(jī)器學(xué)習(xí)任務(wù)中�����,Spark即使有更多的機(jī)器資源也無法利用�,機(jī)器只在特定較少的規(guī)模下才能發(fā)揮最佳性能�,但是這個(gè)最佳性能其實(shí)也并不理想����。
采用參數(shù)服務(wù)器方案��,我們與Spark做了如下比較:在有5000萬條訓(xùn)練樣本的數(shù)據(jù)集上���,采用SGD解的邏輯回歸模型�����,使用10個(gè)工作節(jié)點(diǎn)(Worker)��,針對不同維度的特征逐一進(jìn)行了每輪迭代時(shí)間和整體收斂時(shí)間的比較(這里Angel使用的是BSP模式)����。

通過數(shù)據(jù)可見���,模型越大Angel對比Spark的優(yōu)勢就越明顯����。
3)內(nèi)存優(yōu)化
在運(yùn)算過程中為減少內(nèi)存消耗和提升單進(jìn)程內(nèi)運(yùn)算收斂性使用了異步無鎖的Hogwild! 模式����。同一個(gè)運(yùn)算進(jìn)程中的N個(gè)Task如果在運(yùn)算中都各自保持一個(gè)獨(dú)立的參數(shù)快照��,對參數(shù)的內(nèi)存開銷就N倍�����,模型維度越大時(shí)消耗越明顯�����!SGD的優(yōu)化算法中�����,實(shí)際場景中�����,訓(xùn)練數(shù)據(jù)絕大多數(shù)情況下是稀疏的�,因此參數(shù)更新沖突的概率就大大降低了�����,即便沖突了梯度也不完全是往差的方向發(fā)展����,畢竟都是朝著梯度下降的方向更新的�。我們使用了Hogwild!模式之后���,讓多個(gè)Task在一個(gè)進(jìn)程內(nèi)共享同一個(gè)參數(shù)快照�,減少內(nèi)存消耗并提升了收斂速度��。
4)網(wǎng)絡(luò)優(yōu)化
我們有兩個(gè)主要優(yōu)化點(diǎn):
1)進(jìn)程內(nèi)的Task運(yùn)算之后的參數(shù)更新合并之后平滑的推送到參數(shù)服務(wù)器更新���,這減少了Task所在機(jī)器的上行消耗,也減少了參數(shù)服務(wù)器的下行消耗�,同時(shí)減少在推送更新的過程中的峰值瓶頸次數(shù);
2)針對SSP進(jìn)行更深一步的網(wǎng)絡(luò)優(yōu)化:由于SSP是一種半同步的運(yùn)算協(xié)調(diào)機(jī)制�,在有限的窗口運(yùn)行訓(xùn)練,快的節(jié)點(diǎn)達(dá)到窗口邊緣時(shí)�,任務(wù)就必須停下來等待最慢的節(jié)點(diǎn)更新最新的參數(shù)。針對這一問題����,我們通過網(wǎng)絡(luò)流量的再分配來加速較慢的工作節(jié)點(diǎn)。我們給較慢的節(jié)點(diǎn)以更高的帶寬�;相應(yīng)的,快的工作節(jié)點(diǎn)就分得更少的帶寬�����。這樣一來,快的節(jié)點(diǎn)和慢的節(jié)點(diǎn)的迭代次數(shù)的差距就得以控制����,減少了窗口被突破(發(fā)生等待)的概率,也就是減少了工作節(jié)點(diǎn)由于SSP窗口而空閑等待時(shí)間��。
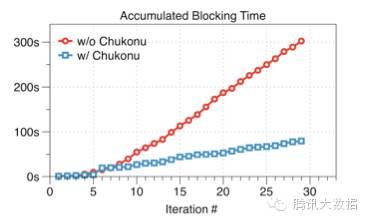
如下圖所示��,在1億維度���、迭代30輪的效果評測中����,可以看到Chukonu使得累積的空閑等待時(shí)間大幅度減少���,達(dá)3.79倍����。
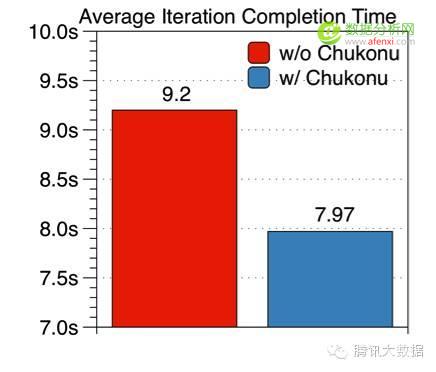
下圖展示的是優(yōu)化前后的執(zhí)行時(shí)間���,以5000萬維度的模型為例�,20個(gè)工作節(jié)點(diǎn)和10個(gè)參數(shù)服務(wù)器,Staleness=5��,執(zhí)行30輪迭代���??梢钥闯?,開啟Chukonu后平均每輪的完成時(shí)間只需7.97秒,相比于比原始的任務(wù)平均每輪9.2秒有了15%的提升���。
另外��,針對性加速慢的節(jié)點(diǎn)可以使慢的節(jié)點(diǎn)更大可能的獲得最新的參數(shù),因此對比原始的SSP計(jì)算模型�����,算法收斂性得到了提升����。下圖所示,同樣是針對五千萬維度的模型在SSP下的效果評測��,原生的Angel任務(wù)在30輪迭代后(276秒)loss達(dá)到了0.0697���,而開啟了Chukonu后�,在第19輪迭代(145秒)就已達(dá)到更低的loss。從這種特定場景來看有一個(gè)接近90%的收斂速度提升�。

后續(xù)計(jì)劃
未來,項(xiàng)目組將擴(kuò)大應(yīng)用的規(guī)模���,同時(shí)����,項(xiàng)目組已經(jīng)在繼續(xù)研發(fā)Angel的下一版本��,下一個(gè)版本會在模型并行方面做一些深入的優(yōu)化�。另外,項(xiàng)目組正在計(jì)劃把Angel進(jìn)行開源�,我們會在后續(xù)合適的時(shí)機(jī)進(jìn)行公開。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試�����,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情���;
? 想學(xué)習(xí)CDA考試教材��,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫�����,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量�����,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330