8個(gè)經(jīng)過(guò)證實(shí)的方法:提高機(jī)器學(xué)習(xí)模型的準(zhǔn)確率
提升一個(gè)模型的表現(xiàn)有時(shí)很困難��。如果你們?cè)?jīng)糾結(jié)于相似的問(wèn)題��,那我相信你們中很多人會(huì)同意我的看法��。你會(huì)嘗試所有曾學(xué)習(xí)過(guò)的策略和算法���,但模型正確率并沒(méi)有改善���。你會(huì)覺(jué)得無(wú)助和困頓,這是90%的數(shù)據(jù)科學(xué)家開始放棄的時(shí)候����。
不過(guò)�����,這才是考驗(yàn)真本領(lǐng)的時(shí)候!這也是普通的數(shù)據(jù)科學(xué)家跟大師級(jí)數(shù)據(jù)科學(xué)家的差距所在����。你是否曾經(jīng)夢(mèng)想過(guò)成為大師級(jí)的數(shù)據(jù)科學(xué)家呢?
如果是的話����,你需要這 8 個(gè)經(jīng)過(guò)證實(shí)的方法來(lái)重構(gòu)你的模型。建立預(yù)測(cè)模型的方法不止一種��。這里沒(méi)有金科玉律���。但是���,如果你遵循我的方法(見下文),(在提供的數(shù)據(jù)足以用來(lái)做預(yù)測(cè)的前提下)你的模型會(huì)擁有較高的準(zhǔn)確率�����。
我從實(shí)踐中學(xué)習(xí)了到這些方法。相對(duì)于理論�����,我一向更熱衷于實(shí)踐��。這種學(xué)習(xí)方式也一直在激勵(lì)我��。本文將分享 8 個(gè)經(jīng)過(guò)證實(shí)的方法�,使用這些方法可以建立穩(wěn)健的機(jī)器學(xué)習(xí)模型。希望我的知識(shí)可以幫助大家獲得更高的職業(yè)成就���。.
正文:
模型的開發(fā)周期有多個(gè)不同的階段�����,從數(shù)據(jù)收集開始直到模型建立���。
不過(guò),在通過(guò)探索數(shù)據(jù)來(lái)理解(變量的)關(guān)系之前��,建議進(jìn)行假設(shè)生成(hypothesis generation)步驟(如果想了解更多有關(guān)假設(shè)生成的內(nèi)容����,推薦閱讀 why-and-when-is-hypothesis-generation-important )�。我認(rèn)為����,這是預(yù)測(cè)建模過(guò)程中最被低估的一個(gè)步驟。
花時(shí)間思考要回答的問(wèn)題以及獲取領(lǐng)域知識(shí)也很重要���。這有什么幫助呢?它會(huì)幫助你隨后建立更好的特征集����,不被當(dāng)前的數(shù)據(jù)集誤導(dǎo)。這是改善模型正確率的一個(gè)重要環(huán)節(jié)�。
在這個(gè)階段,你應(yīng)該對(duì)問(wèn)題進(jìn)行結(jié)構(gòu)化思考��,即進(jìn)行一個(gè)把此問(wèn)題相關(guān)的所有可能的方面納入考慮范圍的思考過(guò)程���。
現(xiàn)在讓我們挖掘得更深入一些���。讓我們看看這些已被證實(shí)的,用于改善模型準(zhǔn)確率的方法�����。
1. 增加更多數(shù)據(jù)
持有更多的數(shù)據(jù)永遠(yuǎn)是個(gè)好主意。相比于去依賴假設(shè)和弱相關(guān)���,更多的數(shù)據(jù)允許數(shù)據(jù)進(jìn)行“自我表達(dá)”�。數(shù)據(jù)越多�,模型越好,正確率越高�。
我明白,有時(shí)無(wú)法獲得更多數(shù)據(jù)�����。比如����,在數(shù)據(jù)科學(xué)競(jìng)賽中,訓(xùn)練集的數(shù)據(jù)量是無(wú)法增加的�����。但對(duì)于企業(yè)項(xiàng)目��,我建議���,如果可能的話��,去索取更多數(shù)據(jù)�����。這會(huì)減少由于數(shù)據(jù)集規(guī)模有限帶來(lái)的痛苦�。
2. 處理缺失值和異常值
訓(xùn)練集中缺失值與異常值的意外出現(xiàn),往往會(huì)導(dǎo)致模型正確率低或有偏差���。這會(huì)導(dǎo)致錯(cuò)誤的預(yù)測(cè)�����。這是由于我們沒(méi)能正確分析目標(biāo)行為以及與其他變量的關(guān)系。所以處理好缺失值和異常值很重要��。
仔細(xì)看下面一幅截圖�����。在存在缺失值的情況下�����,男性和女性玩板球的概率相同���。但如果看第二張表(缺失值根據(jù)稱呼“Miss”被填補(bǔ)以后)�����,相對(duì)于男性��,女性玩板球的概率更高���。
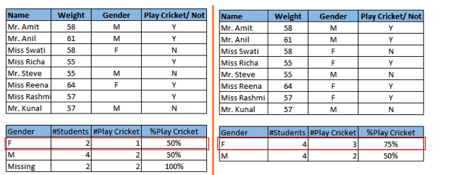
左側(cè):缺失值處理前�;右側(cè):缺失值處理后
從上面的例子中����,我們可以看出缺失值對(duì)于模型準(zhǔn)確率的不利影響。所幸����,我們有各種方法可以應(yīng)對(duì)缺失值和異常值:
-
缺失值:對(duì)于連續(xù)變量,可以把缺失值替換成平均值��、中位數(shù)�����、眾數(shù)。對(duì)于分類變量�,可以把變量作為一個(gè)特殊類別看待。你也可以建立模型預(yù)測(cè)缺失值����。KNN 為處理缺失值提供了很好的方法。想了解更多這方面內(nèi)容�����,推薦閱讀《Methods to deal and treat missing values》���。
-
異常值:你可以刪除這些條目���,進(jìn)行轉(zhuǎn)換,分箱��。如同缺失值��,你也可以對(duì)異常值進(jìn)行區(qū)別對(duì)待���。想了解更多這方面內(nèi)容,推薦閱讀《How to detect Outliers in your dataset and treat them?》����。
3. 特征工程學(xué)(Feature Engineering)
這一步驟有助于從現(xiàn)有數(shù)據(jù)中提取更多信息�。新信息作為新特征被提取出來(lái)���。這些特征可能會(huì)更好地解釋訓(xùn)練集中的差異變化�。因此能改善模型的準(zhǔn)確率�。
假設(shè)生成對(duì)特征工程影響很大。好的假設(shè)能帶來(lái)更好的特征集��。這也是我一直建議在假設(shè)生成上花時(shí)間的原因�����。特征工程能被分為兩個(gè)步驟:
特征轉(zhuǎn)換:許多場(chǎng)景需要進(jìn)行特征轉(zhuǎn)換:
A) 把變量的范圍從原始范圍變?yōu)閺?0 到 1 ���。這通常被稱作數(shù)據(jù)標(biāo)準(zhǔn)化��。比如��,某個(gè)數(shù)據(jù)集中第一個(gè)變量以米計(jì)算�,第二個(gè)變量是厘米���,第三個(gè)是千米��,在這種情況下�����,在使用任何算法之前��,必須把數(shù)據(jù)標(biāo)準(zhǔn)化為相同范圍�。
B) 有些算法對(duì)于正態(tài)分布的數(shù)據(jù)表現(xiàn)更好。所以我們需要去掉變量的偏向�。對(duì)數(shù),平方根�,倒數(shù)等方法可用來(lái)修正偏斜。
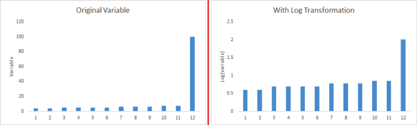
C) 有些時(shí)候�����,數(shù)值型的數(shù)據(jù)在分箱后表現(xiàn)更好�,因?yàn)檫@同時(shí)也處理了異常值。數(shù)值型數(shù)據(jù)可以通過(guò)把數(shù)值分組為箱變得離散�。這也被稱為數(shù)據(jù)離散化。
創(chuàng)建新特征:從現(xiàn)有的變量中衍生出新變量被稱為特征創(chuàng)建�。這有助于釋放出數(shù)據(jù)集中潛藏的關(guān)系��。比如����,我們想通過(guò)某家商店的交易日期預(yù)測(cè)其交易量��。在這個(gè)問(wèn)題上日期可能和交易量關(guān)系不大��,但如果研究這天是星期幾��,可能會(huì)有更高的相關(guān)����。在這個(gè)例子中�����,某個(gè)日期是星期幾的信息是潛在的。我們可以把這個(gè)信息提取為新特征����,優(yōu)化模型。
4. 特征選擇
特征選擇是尋找眾多屬性的哪個(gè)子集合����,能夠最好的解釋目標(biāo)變量與各個(gè)自變量的關(guān)系的過(guò)程�。
你可以根據(jù)多種標(biāo)準(zhǔn)選取有用的特征���,例如:
所在領(lǐng)域知識(shí):根據(jù)在此領(lǐng)域的經(jīng)驗(yàn)���,可以選出對(duì)目標(biāo)變量有更大影響的變量。
可視化:正如這名字所示����,可視化讓變量間的關(guān)系可以被看見,使特征選擇的過(guò)程更輕松�。
統(tǒng)計(jì)參數(shù):我們可以考慮 p 值,信息價(jià)值(information values)和其他統(tǒng)計(jì)參數(shù)來(lái)選擇正確的參數(shù)�����。
PCA:這種方法有助于在低維空間表現(xiàn)訓(xùn)練集數(shù)據(jù)�。這是一種降維技術(shù)。 降低數(shù)據(jù)集維度還有許多方法:如因子分析����、低方差、高相關(guān)�����、前向后向變量選擇及其他���。
5. 使用多種算法
使用正確的機(jī)器學(xué)習(xí)算法是獲得更高準(zhǔn)確率的理想方法�����。但是說(shuō)起來(lái)容易做起來(lái)難����。
這種直覺(jué)來(lái)自于經(jīng)驗(yàn)和不斷嘗試�����。有些算法比其他算法更適合特定類型數(shù)據(jù)�。因此��,我們應(yīng)該使用所有有關(guān)的模型,并檢測(cè)其表現(xiàn)�����。
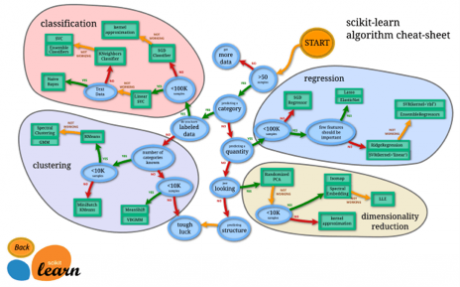
來(lái)源:Scikit-Learn 算法選擇圖
6. 算法的調(diào)整
我們都知道機(jī)器學(xué)習(xí)算法是由參數(shù)驅(qū)動(dòng)的���。這些參數(shù)對(duì)學(xué)習(xí)的結(jié)果有明顯影響�����。參數(shù)調(diào)整的目的是為每個(gè)參數(shù)尋找最優(yōu)值�,以改善模型正確率�。要調(diào)整這些參數(shù),你必須對(duì)它們的意義和各自的影響有所了解�。你可以在一些表現(xiàn)良好的模型上重復(fù)這個(gè)過(guò)程。
例如��,在隨機(jī)森林中,我們有 max_features, number_trees, random_state, oob_score 以及其他參數(shù)�����。優(yōu)化這些參數(shù)值會(huì)帶來(lái)更好更準(zhǔn)確的模型。
想要詳細(xì)了解調(diào)整參數(shù)帶來(lái)的影響����,可以查閱《Tuning the parameters of your Random Forest model》。下面是隨機(jī)森林算法在scikit learn中的全部參數(shù)清單:
RandomForestClassifier(n_estimators=10,criterion='gini',max_depth=None,min_samples_split=2,min_samples_leaf=1,min_weight_fraction_leaf=0.0,max_features='auto',max_leaf_nodes=None,bootstrap=True,oob_score=False,n_jobs=1,random_state=None,verbose=0,warm_start=False,class_weight=None)
7. 集成模型
在數(shù)據(jù)科學(xué)競(jìng)賽獲勝方案中最常見的方法����。這個(gè)技術(shù)就是把多個(gè)弱模型的結(jié)果組合在一起�����,獲得更好的結(jié)果���。它能通過(guò)許多方式實(shí)現(xiàn)��,如:
Bagging (Bootstrap Aggregating)
Boosting
想了解更多這方面內(nèi)容��,可以查閱《Introduction to ensemble learning》�。
使用集成方法改進(jìn)模型正確率永遠(yuǎn)是個(gè)好主意���。主要有兩個(gè)原因:
1)集成方法通常比傳統(tǒng)方法更復(fù)雜����;
2)傳統(tǒng)方法提供好的基礎(chǔ)���,在此基礎(chǔ)上可以建立集成方法。
注意����!
到目前為止�,我們了解了改善模型準(zhǔn)確率的方法。但是�����,高準(zhǔn)確率的模型不一定(在未知數(shù)據(jù)上)有更好的表現(xiàn)。有時(shí)�,模型準(zhǔn)確率的改善是由于過(guò)度擬合。
8. 交叉驗(yàn)證
如果想解決這個(gè)問(wèn)題�,我們必須使用交叉驗(yàn)證技術(shù)(cross validation)。交叉驗(yàn)證是數(shù)據(jù)建模領(lǐng)域最重要的概念之一����。它是指,保留一部分?jǐn)?shù)據(jù)樣本不用來(lái)訓(xùn)練模型���,而是在完成模型前用來(lái)驗(yàn)證。
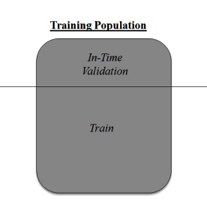
這種方法有助于得出更有概括性的關(guān)系�����。想了解更多有關(guān)交叉檢驗(yàn)的內(nèi)容���,建議查閱《Improve model performance using cross validation》���。
結(jié)語(yǔ)
預(yù)測(cè)建模的過(guò)程令人疲憊。但是�,如果你能靈活思考,就可以輕易勝過(guò)其他人��。簡(jiǎn)單地說(shuō),多考慮上面這8個(gè)步驟�。獲得數(shù)據(jù)集以后,遵循這些被驗(yàn)證過(guò)的方法�,你就一定會(huì)得到穩(wěn)健的機(jī)器學(xué)習(xí)模型。不過(guò)���,只有當(dāng)你熟練掌握了這些步驟��,它們才會(huì)真正有幫助。比如�����,想要建立一個(gè)集成模型,你必須對(duì)多種機(jī)器學(xué)習(xí)算法有所了解���。
本文分享了 8 個(gè)經(jīng)過(guò)證實(shí)的方法���。這些方法用來(lái)改善模型的預(yù)測(cè)表現(xiàn)。它們廣為人知���,但不一定要按照文中的順序逐個(gè)使用�。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試�����,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情���;
? 想學(xué)習(xí)CDA考試教材,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫(kù)��,點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情��;
? 想了解CDA考試含金量���,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330