使用Storm實現(xiàn)實時大數(shù)據(jù)分析
簡單和明了�,Storm讓大數(shù)據(jù)分析變得輕松加愉快�。
當(dāng)今世界,公司的日常運營經(jīng)常會生成TB級別的數(shù)據(jù)���。數(shù)據(jù)來源囊括了互聯(lián)網(wǎng)裝置可以捕獲的任何類型數(shù)據(jù)�,網(wǎng)站��、社交媒體��、交易型商業(yè)數(shù)據(jù)以及其它商業(yè)環(huán)境中創(chuàng)建的數(shù)據(jù)����?�?紤]到數(shù)據(jù)的生成量�����,實時處理成為了許多機構(gòu)需要面對的首要挑戰(zhàn)�����。我們經(jīng)常用的一個非常有效的開源實時計算工具就是Storm —— Twitter開發(fā),通常被比作“實時的Hadoop”�����。然而Storm遠(yuǎn)比Hadoop來的簡單�����,因為用它處理大數(shù)據(jù)不會帶來新老技術(shù)的交替��。
Shruthi Kumar�、Siddharth Patankar共同效力于Infosys,分別從事技術(shù)分析和研發(fā)工作�����。本文詳述了Storm的使用方法����,例子中的項目名稱為“超速報警系統(tǒng)(Speeding Alert System)”。我們想實現(xiàn)的功能是:實時分析過往車輛的數(shù)據(jù)��,一旦車輛數(shù)據(jù)超過預(yù)設(shè)的臨界值 —— 便觸發(fā)一個trigger并把相關(guān)的數(shù)據(jù)存入數(shù)據(jù)庫����。
Storm
對比Hadoop的批處理�����,Storm是個實時的����、分布式以及具備高容錯的計算系統(tǒng)�����。同Hadoop一樣Storm也可以處理大批量的數(shù)據(jù)�,然而Storm在保證高可靠性的前提下還可以讓處理進(jìn)行的更加實時;也就是說,所有的信息都會被處理�����。Storm同樣還具備容錯和分布計算這些特性�,這就讓Storm可以擴展到不同的機器上進(jìn)行大批量的數(shù)據(jù)處理��。他同樣還有以下的這些特性:
易于擴展�����。對于擴展,你只需要添加機器和改變對應(yīng)的topology(拓?fù)?設(shè)置���。Storm使用Hadoop Zookeeper進(jìn)行集群協(xié)調(diào)�����,這樣可以充分的保證大型集群的良好運行�。
每條信息的處理都可以得到保證���。
Storm集群管理簡易�。
Storm的容錯機能:一旦topology遞交�,Storm會一直運行它直到topology被廢除或者被關(guān)閉。而在執(zhí)行中出現(xiàn)錯誤時����,也會由Storm重新分配任務(wù)。
盡管通常使用Java��,Storm中的topology可以用任何語言設(shè)計���。
當(dāng)然為了更好的理解文章�����,你首先需要安裝和設(shè)置Storm��。需要通過以下幾個簡單的步驟:
從Storm官方下載Storm安裝文件
將bin/directory解壓到你的PATH上,并保證bin/storm腳本是可執(zhí)行的�。
Storm組件
Storm集群主要由一個主節(jié)點和一群工作節(jié)點(worker node)組成,通過 Zookeeper進(jìn)行協(xié)調(diào)����。
主節(jié)點:
主節(jié)點通常運行一個后臺程序 —— Nimbus��,用于響應(yīng)分布在集群中的節(jié)點����,分配任務(wù)和監(jiān)測故障。這個很類似于Hadoop中的Job Tracker�����。
工作節(jié)點:
工作節(jié)點同樣會運行一個后臺程序 —— Supervisor,用于收聽工作指派并基于要求運行工作進(jìn)程���。每個工作節(jié)點都是topology中一個子集的實現(xiàn)�。而Nimbus和Supervisor之間的協(xié)調(diào)則通過Zookeeper系統(tǒng)或者集群����。
Zookeeper
Zookeeper是完成Supervisor和Nimbus之間協(xié)調(diào)的服務(wù)�。而應(yīng)用程序?qū)崿F(xiàn)實時的邏輯則被封裝進(jìn)Storm中的“topology”�����。topology則是一組由Spouts(數(shù)據(jù)源)和Bolts(數(shù)據(jù)操作)通過Stream Groupings進(jìn)行連接的圖����。下面對出現(xiàn)的術(shù)語進(jìn)行更深刻的解析。
Spout:
簡而言之,Spout從來源處讀取數(shù)據(jù)并放入topology���。Spout分成可靠和不可靠兩種;當(dāng)Storm接收失敗時����,可靠的Spout會對tuple(元組����,數(shù)據(jù)項組成的列表)進(jìn)行重發(fā);而不可靠的Spout不會考慮接收成功與否只發(fā)射一次�����。而Spout中最主要的方法就是nextTuple(),該方法會發(fā)射一個新的tuple到topology����,如果沒有新tuple發(fā)射則會簡單的返回。
Bolt:
Topology中所有的處理都由Bolt完成����。Bolt可以完成任何事,比如:連接的過濾��、聚合、訪問文件/數(shù)據(jù)庫�����、等等����。Bolt從Spout中接收數(shù)據(jù)并進(jìn)行處理,如果遇到復(fù)雜流的處理也可能將tuple發(fā)送給另一個Bolt進(jìn)行處理�。而Bolt中最重要的方法是execute()����,以新的tuple作為參數(shù)接收���。不管是Spout還是Bolt,如果將tuple發(fā)射成多個流���,這些流都可以通過declareStream()來聲明���。
Stream Groupings:
Stream Grouping定義了一個流在Bolt任務(wù)間該如何被切分�����。這里有Storm提供的6個Stream Grouping類型:
1. 隨機分組(Shuffle grouping):隨機分發(fā)tuple到Bolt的任務(wù)���,保證每個任務(wù)獲得相等數(shù)量的tuple��。
2. 字段分組(Fields grouping):根據(jù)指定字段分割數(shù)據(jù)流�����,并分組。例如����,根據(jù)“user-id”字段�,相同“user-id”的元組總是分發(fā)到同一個任務(wù),不同“user-id”的元組可能分發(fā)到不同的任務(wù)。
3. 全部分組(All grouping):tuple被復(fù)制到bolt的所有任務(wù)��。這種類型需要謹(jǐn)慎使用�。
4. 全局分組(Global grouping):全部流都分配到bolt的同一個任務(wù)�����。明確地說�,是分配給ID最小的那個task。
5. 無分組(None grouping):你不需要關(guān)心流是如何分組。目前��,無分組等效于隨機分組�。但最終����,Storm將把無分組的Bolts放到Bolts或Spouts訂閱它們的同一線程去執(zhí)行(如果可能)�。
6. 直接分組(Direct grouping):這是一個特別的分組類型���。元組生產(chǎn)者決定tuple由哪個元組處理者任務(wù)接收��。
當(dāng)然還可以實現(xiàn)CustomStreamGroupimg接口來定制自己需要的分組。
項目實施
當(dāng)下情況我們需要給Spout和Bolt設(shè)計一種能夠處理大量數(shù)據(jù)(日志文件)的topology�,當(dāng)一個特定數(shù)據(jù)值超過預(yù)設(shè)的臨界值時促發(fā)警報����。使用Storm的topology����,逐行讀入日志文件并且監(jiān)視輸入數(shù)據(jù)��。在Storm組件方面�,Spout負(fù)責(zé)讀入輸入數(shù)據(jù)���。它不僅從現(xiàn)有的文件中讀入數(shù)據(jù)���,同時還監(jiān)視著新文件�。文件一旦被修改Spout會讀入新的版本并且覆蓋之前的tuple(可以被Bolt讀入的格式)�����,將tuple發(fā)射給Bolt進(jìn)行臨界分析��,這樣就可以發(fā)現(xiàn)所有可能超臨界的記錄�。
下一節(jié)將對用例進(jìn)行詳細(xì)介紹��。
臨界分析
這一節(jié)����,將主要聚焦于臨界值的兩種分析類型:瞬間臨界(instant thershold)和時間序列臨界(time series threshold)��。
瞬間臨界值監(jiān)測:一個字段的值在那個瞬間超過了預(yù)設(shè)的臨界值,如果條件符合的話則觸發(fā)一個trigger。舉個例子當(dāng)車輛超越80公里每小時����,則觸發(fā)trigger�。
時間序列臨界監(jiān)測:字段的值在一個給定的時間段內(nèi)超過了預(yù)設(shè)的臨界值���,如果條件符合則觸發(fā)一個觸發(fā)器�。比如:在5分鐘類,時速超過80KM兩次及以上的車輛����。
Listing One顯示了我們將使用的一個類型日志,其中包含的車輛數(shù)據(jù)信息有:車牌號、車輛行駛的速度以及數(shù)據(jù)獲取的位置���。
AB 12360North city
BC 12370South city
CD 23440South city
DE 12340East city
EF 12390South city
GH 12350West city
這里將創(chuàng)建一個對應(yīng)的XML文件����,這將包含引入數(shù)據(jù)的模式�。這個XML將用于日志文件的解析���。XML的設(shè)計模式和對應(yīng)的說明請見下表�。
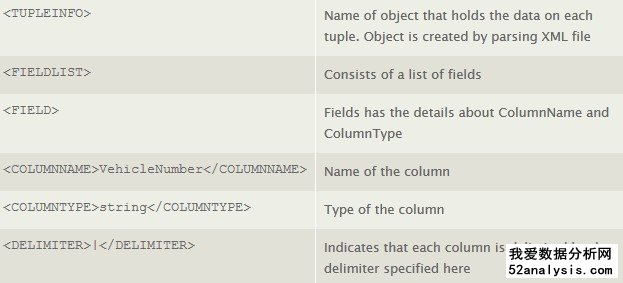
XML文件和日志文件都存放在Spout可以隨時監(jiān)測的目錄下,用以關(guān)注文件的實時更新��。而這個用例中的topology請見下圖��。

Figure 1:Storm中建立的topology,用以實現(xiàn)數(shù)據(jù)實時處理
如圖所示:FilelistenerSpout接收輸入日志并進(jìn)行逐行的讀入���,接著將數(shù)據(jù)發(fā)射給ThresoldCalculatorBolt進(jìn)行更深一步的臨界值處理����。一旦處理完成���,被計算行的數(shù)據(jù)將發(fā)送給DBWriterBolt����,然后由DBWriterBolt存入給數(shù)據(jù)庫�。下面將對這個過程的實現(xiàn)進(jìn)行詳細(xì)的解析。
Spout的實現(xiàn)
Spout以日志文件和XML描述文件作為接收對象��。XML文件包含了與日志一致的設(shè)計模式��。不妨設(shè)想一下一個示例日志文件���,包含了車輛的車牌號、行駛速度、以及數(shù)據(jù)的捕獲位置��。(看下圖)
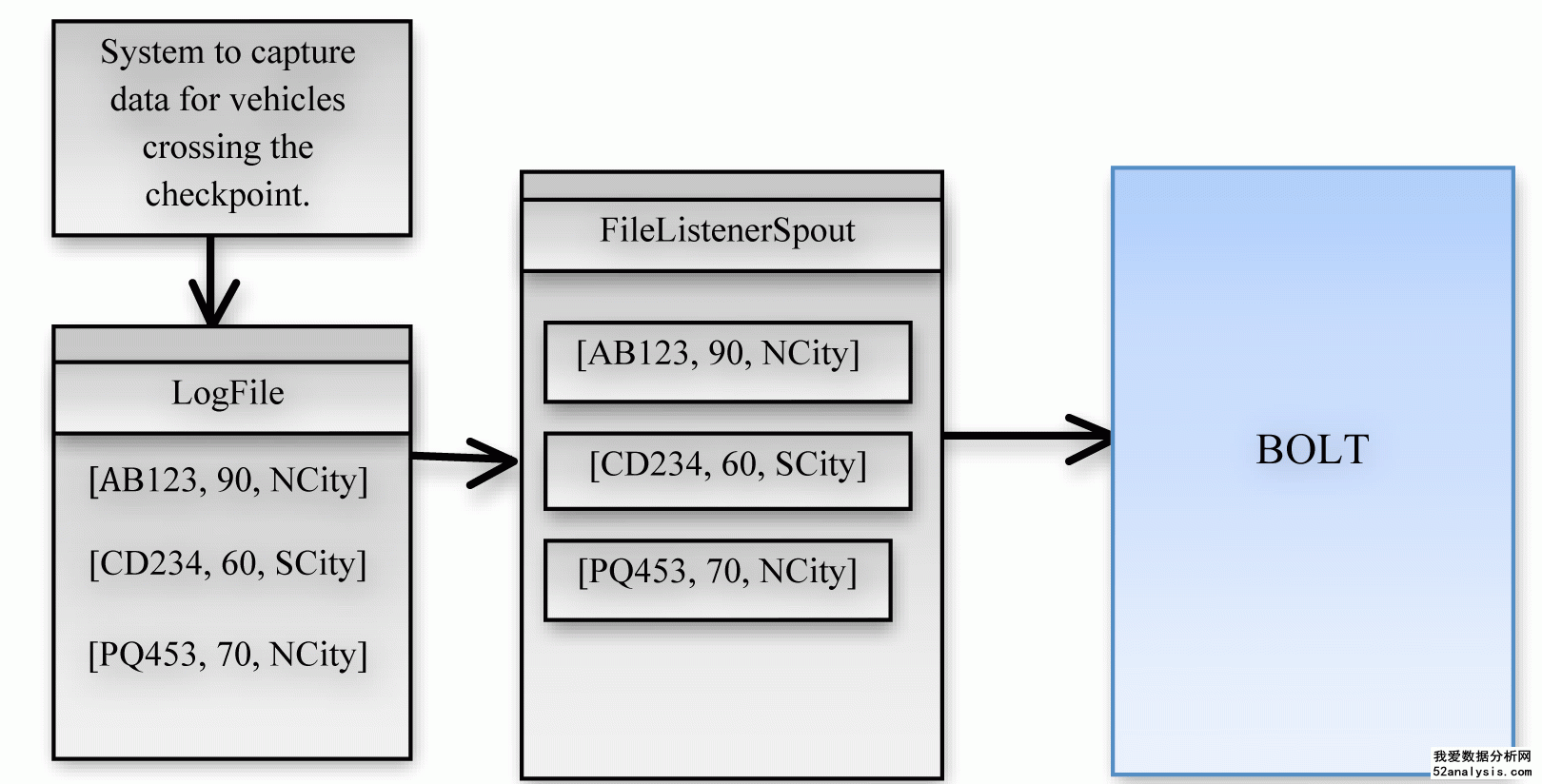
Figure2:數(shù)據(jù)從日志文件到Spout的流程圖
Listing Two顯示了tuple對應(yīng)的XML,其中指定了字段、將日志文件切割成字段的定界符以及字段的類型����。XML文件以及數(shù)據(jù)都被保存到Spout指定的路徑�����。
Listing Two:用以描述日志文件的XML文件���。
<
TUPLEINFO
>
<
FIELDLIST
>
<
FIELD
>
<
COLUMNNAME
>
vehicle_number
COLUMNNAME
>
<
COLUMNTYPE
>
string
COLUMNTYPE
>
FIELD
>
<
FIELD
>
<
COLUMNNAME
>
speed
COLUMNNAME
>
<
COLUMNTYPE
>
int
COLUMNTYPE
>
FIELD
>
<
FIELD
>
<
COLUMNNAME
>
location
COLUMNNAME
>
<
COLUMNTYPE
>
string
COLUMNTYPE
>
FIELD
>
FIELDLIST
>
<
DELIMITER
>
,
DELIMITER
>
TUPLEINFO
>
通過構(gòu)造函數(shù)及它的參數(shù)Directory、PathSpout和TupleInfo對象創(chuàng)建Spout對象。TupleInfo儲存了日志文件的字段�、定界符、字段的類型這些很必要的信息。這個對象通過XSTream序列化XML時建立�����。
Spout的實現(xiàn)步驟:
對文件的改變進(jìn)行分開的監(jiān)聽�����,并監(jiān)視目錄下有無新日志文件添加�����。
在數(shù)據(jù)得到了字段的說明后����,將其轉(zhuǎn)換成tuple�。
聲明Spout和Bolt之間的分組,并決定tuple發(fā)送給Bolt的途徑��。
Spout的具體編碼在Listing Three中顯示����。
Listing Three:Spout中open、nextTuple和delcareOutputFields方法的邏輯�����。
public void open( Map conf, TopologyContext context,SpoutOutputCollector collector )
{
_collector = collector;
try
{
fileReader = new BufferedReader(new FileReader(new File(file)));
}
catch (FileNotFoundException e)
{
System.exit(1);
}
}
public void nextTuple()
{
protected void ListenFile(File file)
{
Utils.sleep(2000);
RandomAccessFile access = null;
String line = null;
try
{
while ((line = access.readLine()) != null)
{
if (line !=null)
{
String[] fields=null;
if (tupleInfo.getDelimiter().equals("|")) fields = line.split("\\"+tupleInfo.getDelimiter());
else
fields = line.split (tupleInfo.getDelimiter());
if (tupleInfo.getFieldList().size() == fields.length) _collector.emit(new Values(fields));
}
}
}
catch (IOException ex){ }
}
}
public void declareOutputFields(OutputFieldsDeclarer declarer)
{
String[] fieldsArr = new String [tupleInfo.getFieldList().size()];
for(int i=0; i
{
fieldsArr[i] = tupleInfo.getFieldList().get(i).getColumnName();
}
declarer.declare(new Fields(fieldsArr));
}
declareOutputFileds()決定了tuple發(fā)射的格式,這樣的話Bolt就可以用類似的方法將tuple譯碼。Spout持續(xù)對日志文件的數(shù)據(jù)的變更進(jìn)行監(jiān)聽�,一旦有添加Spout就會進(jìn)行讀入并且發(fā)送給Bolt進(jìn)行處理��。
Bolt的實現(xiàn)
Spout的輸出結(jié)果將給予Bolt進(jìn)行更深一步的處理���。經(jīng)過對用例的思考���,我們的topology中需要如Figure 3中的兩個Bolt�����。
Figure 3:Spout到Bolt的數(shù)據(jù)流程。
ThresholdCalculatorBolt
Spout將tuple發(fā)出����,由ThresholdCalculatorBolt接收并進(jìn)行臨界值處理。在這里�,它將接收好幾項輸入進(jìn)行檢查;分別是:
臨界值檢查
臨界值欄數(shù)檢查(拆分成字段的數(shù)目)
臨界值數(shù)據(jù)類型(拆分后字段的類型)
臨界值出現(xiàn)的頻數(shù)
臨界值時間段檢查
Listing Four中的類,定義用來保存這些值�。
Listing Four:ThresholdInfo類
public class ThresholdInfo implementsSerializable
{
private String action;
private String rule;
private Object thresholdValue;
private int thresholdColNumber;
private Integer timeWindow;
private int frequencyOfOccurence;
}
基于字段中提供的值���,臨界值檢查將被Listing Five中的execute()方法執(zhí)行。代碼大部分的功能是解析和接收值的檢測�。
Listing Five:臨界值檢測代碼段
public void execute(Tuple tuple, BasicOutputCollector collector)
{
if(tuple!=null)
{
List
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認(rèn)證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學(xué)習(xí)CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量����,點擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330