我們自己終會成為大數據
對于大數據在商業(yè)上的用途��,這句話說得很清楚���。前半句是重點,了解用戶的行為習慣和愛好,這就是大數據的核心價值��。
1. 元數據(Metadata)的概念
簡單說�,元數據是對數據本身進行描述的數據,或者說�����,它不是對象本身��,它只描述對象的屬性�。
比如,一幅畫本身���,是數據��。而這幅畫的作者��、完成時間����、尺寸���、價格���、類型等等�,就是它的元數據����。
再比如,你媽逼你結婚�����,找了個男的讓你相親����。你并不認識他�,但你媽告訴你他的年齡、身高���、體重����、體貌特征�����、家庭背景、收入��、愛好特長��,你心里也就對他有了印象��。即便你還不認識他��。
元數據的價值����,第一是能夠從側面描述對象,第二點就是可以結構化��、信息化����。
什么意思呢?
比如���,我們要判斷一幅畫的價值����,除了專家直接通過畫的藝術性來評價�����,還可以通過元數據來判斷。
這幅畫是名家的還是二流畫家的����?這幅畫是作者在他創(chuàng)作鼎盛時期的作品,還是在年輕時的作品�����?這幅畫是作者擅長的類型還是他不熟悉的�?
用這些描述的信息,我們居然就能把這幅畫的價值算得八九不離十�。雖然肯定會存在誤差,但同樣是科學合理的方法�。
那用元數據而非數據本身描述對象的意義何在�����?
這就是在大數據上產生的價值了:對于非結構化的����、非量化的對象本身,結構化的元數據可以用以快速計算和判斷�。
比如��,你媽拿了 100 個單身男的資料��,你要是一個一個去仔細翻閱��,那幾天都翻不完�����。但你告訴你媽�����,高學歷的可能意味著素質很高���,高收入的可能意味著能力很強,所以先把低學歷低收入的篩掉���,剩下的再依據身高體重年齡這些信息排序���,那效率就高得多了。
注意����,這樣的方法仍然會有失誤的��,說不定真愛就在被篩掉的人里�。但這樣的概率微乎其微�����。
相親里似乎還不太明顯�����,但大數據在真正產品應用中����,產生的效果就天翻地覆了。
2. 大數據應用的第一階段:輔助產品����。
最初的應用比較簡單,就是用以輔助產品人員和市場人員做判斷��。
過去的實體產品做一次調研很麻煩���。比如飲料公司,調研人員要用各種方式觀看他們喝飲料的場景和步驟��。
問卷是最常見的,但不準����。所以會組織各種各樣專業(yè)的現場試驗,要搭建環(huán)境(一般是有單面玻璃或攝像頭的)�����、邀請志愿者��,然后引導他們按照日常的習慣去完成一些操作�����。
比如這樣的通過攝像頭監(jiān)視觀察室��。
顯然這種辦法非常笨重�����。
而現在的互聯網產品則根本無須這么麻煩���。用戶所有的使用數據�、行為,都是記錄在案的�,想知道什么,瞬間就能分析出來�。
過去想知道用戶有沒有做一件事,比如有沒有用過這個功能��?太難了�����。
現在呢��,就問點擊這個行為��,點擊了幾下�、點擊在哪里,什么時候點的�,甚至這是在什么地方點的、點擊之后又做了什么�,一清二楚。
用戶平時用不用這個功能����、怎么用這個功能,也就一目了然��。
對于產品設計者來說�,這是至關重要的數據。而且��,這是完整的數據��!如果是互聯網產品�����,那么我知道的是所有用戶的數據���,不是過去傳統行業(yè)產品的樣本數據�����。
騰訊知道所有微信用戶有多少用朋友圈�、知道這些用戶每天都發(fā)幾條朋友圈��、知道這些用戶每天都發(fā)了什么����。每一個數據都是真實可用的。
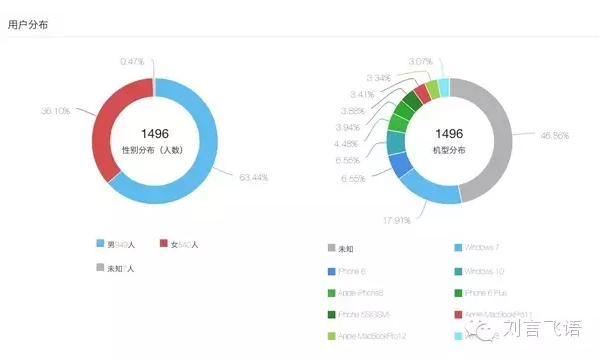
(過去發(fā)行量再大的報紙也很難知道讀者性別�����,然而現在再小的微信公眾號也可以實時獲取。)
在實體產品的行業(yè)��,隨著未來整個產品從生產到銷售到使用的信息化��,大數據也會漸漸起到更大的作用�����。過去我賣的一瓶水�����,可能到某個超市就斷掉了�����,我不知道這瓶水被誰買走了�。但現在我在天貓賣的一瓶水,我知道對方這個用戶是每個月買十箱水的��,他的地址是某個高檔餐廳�,那我就知道這瓶水的目標受眾是誰了。
這是元數據的價值所在��。
所以說,大數據的第一階段是:輔助產品設計者做判斷��、讓產品制造者更好地滿足用戶�����。
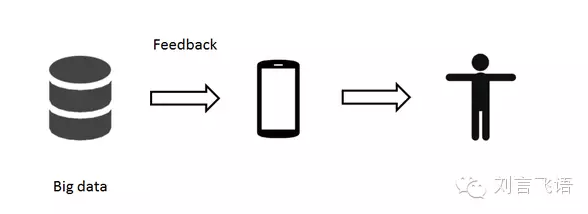
這時候的大數據主要是來為產品提供支持����,產品再應用于用戶��。
3. 大數據應用的第二階段:創(chuàng)造價值����。
在數據的數量和質量達到一定程度后,事情開始變化了����。元數據將不僅作為產品的輔助,而是變成了最有價值的產生本身��。
很簡單的���,全中國最熟悉老百姓消費習慣的是工商局嗎�?是哪個協會嗎?是哪個科研機構嗎�����?都不是�����,是淘寶�����。
擁有最全面的個人信用信息的���,是人事局嗎��?是銀行嗎�����?是咨詢公司嗎����?都不是�,是支付寶���。
道理也簡單得很,所有行為(消費�����、交易)發(fā)生在了這個平臺上����,而這個平臺又有所有數據的記錄��,那這些數據就能產生巨大的價值�����。
你以為做醫(yī)療健康這方面的產品僅僅是關注你的健康嗎�����?并不是��,他們同時還能夠記錄你所有的體征�,這是第一線的臨床數據。
此時�,大數據本身已經成為了產品���,可以輸出有價值的內容。
消費行為數據��,賣給廣告商���,廣告商就可以定向給你投送廣告����;信用數據���,賣給銀行����,銀行就可以判斷出你的信用程度����;健康數據,賣給保險公司...你懂的��。
近幾年����,互聯網公司已經能夠對全國各領域的市場���,給出最有說服力的統計報告了,這些之前可都是政府做的:
淘寶網發(fā)布中國互聯網消費趨勢報告
攜程旅行網發(fā)布《2014年旅游者調查報告》
滴滴攜兩大機構發(fā)布首份智能出行年度報告
不僅僅是將數據出售���,數據提供的內容完全可以創(chuàng)造出新的產品�。尤其像 O2O 這樣的產品/服務��,上游是服務提供者和資源�,下游是用戶,都能夠有價值可以發(fā)掘����。
以前做美甲的時候�,我們設想的商業(yè)模式,有一項就是從上游��,了解美甲師用品的情況���,跟生產廠家合作����,把控渠道�;另外就是從下游�����,知道用戶的情況����,從而也能夠跟其他美業(yè)產品合作(定向幫你把產品帶到家里��,河貍家其實已經在做)�,來讓用戶數據產生價值。
我之前聽說餓了么在嘗試一項新服務��,就是為餐館提供食材��。乍一聽有點怪����,但后來想想的確是再合理不過。除了餓了么還有誰更能清楚某塊區(qū)域的餐品售賣數據呢�?這地方蘿卜白菜賣得多、有多少量�����,餓了么清楚得很,跟農場談合作�,可以很好地把控上游渠道。
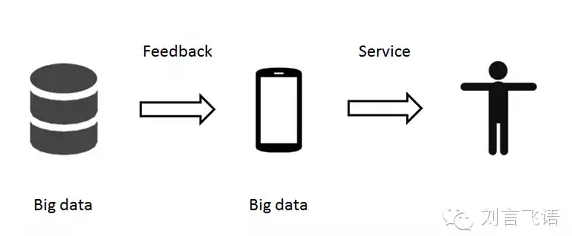
這階段的大數據����,已經可以成為產品,為用戶直接服務��。
從另一個角度看����,不知道你發(fā)現沒,通過我們行為數據這些元數據����,我們已經在慢慢被量化的信息給描述出來了?���?吹竭@些數字(一年花了多少錢����、在哪方面花的錢等等)已經對這個人可以有相對粗糙的認識了。而大數據最終的形態(tài)開始初現����。
4. 大數據應用的第三階段:塑造我們�。
我之前也總是對行為數據表示不屑�����。你知道我在淘寶買了點東西����、跟誰微信聊了幾句話、去百度隨便查了點東西����,就能知道我是什么人了?
還真的可以�。只要數據保質保量。
我知道你一個月沒買避孕套這兩天突然買了三盒����,那可能是你要跟異地戀的女朋友見面了;我發(fā)現你微信跟異地的某個妹子聊得特別多��、經常還視頻��,那這大概就是你異地的女朋友�;我了解你在百度一直搜東南亞的機票和旅行攻略���,那我知道你可能要去那里玩。
就是這么簡單的三條元數據��,我就能推測出來�,你很大概率上,最近要跟女朋友一起去東南亞旅行����。
說實話,做這么基礎的邏輯推斷�����,比下圍棋容易多了��。
這是說明元數據能夠推理信息的邏輯性��。而對于可獲取的元數據����,也越來越多了��。
你打電話時���,可以知道你給誰打(婦科醫(yī)生���?要生孩子了�。律師���?最近有官司��。)
你買東西時��,可以知道你的消費能力����、家庭狀況�����、喜好甚至性格(高端筆記本�����?愛玩游戲���。蠟筆和簡筆畫冊����?家里有小孩。)
你出門消費時�,可以知道你的生活習慣和個人情況(健身房?應該很健康�。經常大保健�?可能身體比較虛。)
你加別人微信時����,可以知道你的社交圈子(認識李開復?應該不是一般人�����。通訊錄里都是快遞員�?那可能也是快遞員。)
作為這些產品的數據的擁有者�,我完全不需要派個私家偵探來跟蹤你。只需要等你自己乖乖把這些數據送上來�。
春節(jié)的時候,支付寶為什么要和微信爭搶小額支付和社交場景的支付���?不是為了那點手續(xù)費�����,就是為了它缺失的社交支付這一塊�����。這塊數據的價值����,遠超想象�。
未來我們每個人的衣食住行�、生活起居,都將有大量的數據記錄��。我們的行為會變成一串串數字成為可量化的數據���,成為描述我們的信息��。我們工作用云筆記��、吃飯用餓了么���、打車用滴滴�����、搜東西用百度�����、社交用微信��,每一步都事無巨細被記了下來�。
不信你可以翻出你歷史所有在百度或者 Google 的搜索記錄來�,對你生活的描述絕對比你自己的日記都要真實。
這些數據將被轉換成有價值的商業(yè)數據����,來描述你各方面的信息。你喜歡黑色的衣服��、你喜歡胸大的妹子��、你比較文藝��、你有高度近視、你最近剛失戀...... 關于你,可能這些數據比你爹媽都要清楚���。
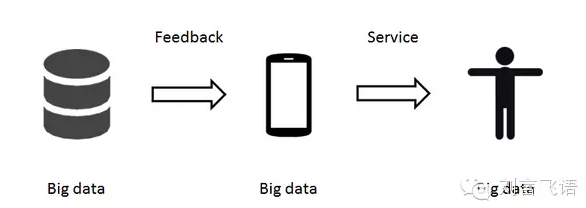
最終���,我們本身就是可以被量化的大數據對象,不存在多層的邏輯了��。
這樣的未來自然有利有弊�。利是我們無處不在享受著大數據帶來的便利,我們看到的每一條廣告都會是我們自己喜歡的�,我們查的每一條搜索記錄都是根據我們特點來推薦的,我們在加好友時系統甚至都可以說他是不是會跟我們合得來��。
弊在于���,我們的隱私就暴露無疑�。只要數據的擁有者想做點壞事����,那真的是什么都有可能。
大數據絕不會止步在為決策僅僅提供幫助��,它的終極形態(tài)就是可以用海量的數據描述我們一個個具體的個體�����。當達到這一步時,現在所謂的市場調研���、用戶分析就都是小兒科了���。
因為,大數據已經完全能夠塑造出我們了��。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情�;
? 想學習CDA考試教材,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫,點擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330