大數(shù)據(jù)下的數(shù)據(jù)分析平臺(tái)架構(gòu)
隨著互聯(lián)網(wǎng)���、移動(dòng)互聯(lián)網(wǎng)和物聯(lián)網(wǎng)的發(fā)展���,誰(shuí)也無(wú)法否認(rèn),我們已經(jīng)切實(shí)地迎來(lái)了一個(gè)海量數(shù)據(jù)的時(shí)代���,數(shù)據(jù)調(diào)查公司IDC預(yù)計(jì)2011年的數(shù)據(jù)總量將達(dá)到1.8萬(wàn)億GB��,對(duì)這些海量數(shù)據(jù)的分析已經(jīng)成為一個(gè)非常重要且緊迫的需求��。
作為一家互聯(lián)網(wǎng)數(shù)據(jù)分析公司����,我們?cè)诤A繑?shù)據(jù)的分析領(lǐng)域那真是被“逼上梁山”��。多年來(lái)在嚴(yán)苛的業(yè)務(wù)需求和數(shù)據(jù)壓力下����,我們幾乎嘗試了所有可能的大數(shù)據(jù)分析方法,最終落地于Hadoop平臺(tái)之上���。
Hadoop在可伸縮性、健壯性��、計(jì)算性能和成本上具有無(wú)可替代的優(yōu)勢(shì),事實(shí)上已成為當(dāng)前互聯(lián)網(wǎng)企業(yè)主流的大數(shù)據(jù)分析平臺(tái)���。本文主要介紹一種基于Hadoop平臺(tái)的多維分析和數(shù)據(jù)挖掘平臺(tái)架構(gòu)�����。
大數(shù)據(jù)分析的分類(lèi)
Hadoop平臺(tái)對(duì)業(yè)務(wù)的針對(duì)性較強(qiáng)�����,為了讓你明確它是否符合你的業(yè)務(wù)����,現(xiàn)粗略地從幾個(gè)角度將大數(shù)據(jù)分析的業(yè)務(wù)需求分類(lèi)�����,針對(duì)不同的具體需求�,應(yīng)采用不同的數(shù)據(jù)分析架構(gòu)。
-
按照數(shù)據(jù)分析的實(shí)時(shí)性�,分為實(shí)時(shí)數(shù)據(jù)分析和離線數(shù)據(jù)分析兩種。
實(shí)時(shí)數(shù)據(jù)分析一般用于金融�、移動(dòng)和互聯(lián)網(wǎng)B2C等產(chǎn)品,往往要求在數(shù)秒內(nèi)返回上億行數(shù)據(jù)的分析���,從而達(dá)到不影響用戶(hù)體驗(yàn)的目的���。要滿(mǎn)足這樣的需求����,可以采用精心設(shè)計(jì)的傳統(tǒng)關(guān)系型數(shù)據(jù)庫(kù)組成并行處理集群�����,或者采用一些內(nèi)存計(jì)算平臺(tái)�����,或者采用HDD的架構(gòu)����,這些無(wú)疑都需要比較高的軟硬件成本。目前比較新的海量數(shù)據(jù)實(shí)時(shí)分析工具有EMC的Greenplum����、SAP的HANA等。
對(duì)于大多數(shù)反饋時(shí)間要求不是那么嚴(yán)苛的應(yīng)用���,比如離線統(tǒng)計(jì)分析�����、機(jī)器學(xué)習(xí)����、搜索引擎的反向索引計(jì)算�、推薦引擎的計(jì)算等,應(yīng)采用離線分析的方式���,通過(guò)數(shù)據(jù)采集工具將日志數(shù)據(jù)導(dǎo)入專(zhuān)用的分析平臺(tái)���。但面對(duì)海量數(shù)據(jù),傳統(tǒng)的ETL工具往往徹底失效���,主要原因是數(shù)據(jù)格式轉(zhuǎn)換的開(kāi)銷(xiāo)太大�����,在性能上無(wú)法滿(mǎn)足海量數(shù)據(jù)的采集需求���。互聯(lián)網(wǎng)企業(yè)的海量數(shù)據(jù)采集工具�����,有Facebook開(kāi)源的Scribe、LinkedIn開(kāi)源的Kafka�����、淘寶開(kāi)源的 Timetunnel��、Hadoop的Chukwa等�����,均可以滿(mǎn)足每秒數(shù)百M(fèi)B的日志數(shù)據(jù)采集和傳輸需求�,并將這些數(shù)據(jù)上載到Hadoop中央系統(tǒng)上。
-
按照大數(shù)據(jù)的數(shù)據(jù)量�����,分為內(nèi)存級(jí)別�、BI級(jí)別、海量級(jí)別三種���。
這里的內(nèi)存級(jí)別指的是數(shù)據(jù)量不超過(guò)集群的內(nèi)存最大值���。不要小看今天內(nèi)存的容量���,F(xiàn)acebook緩存在內(nèi)存的Memcached中的數(shù)據(jù)高達(dá) 320TB,而目前的PC服務(wù)器�,內(nèi)存也可以超過(guò)百GB�����。因此可以采用一些內(nèi)存數(shù)據(jù)庫(kù)���,將熱點(diǎn)數(shù)據(jù)常駐內(nèi)存之中���,從而取得非常快速的分析能力�,非常適合實(shí)時(shí)分析業(yè)務(wù)。圖1是一種實(shí)際可行的MongoDB分析架構(gòu)�。
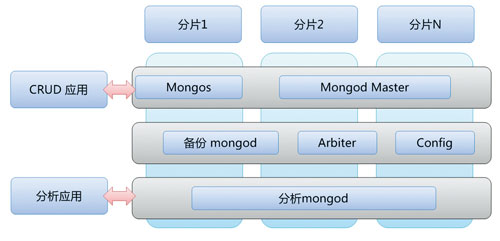
圖1 用于實(shí)時(shí)分析的MongoDB架構(gòu)
MongoDB大集群目前存在一些穩(wěn)定性問(wèn)題,會(huì)發(fā)生周期性的寫(xiě)堵塞和主從同步失效�����,但仍不失為一種潛力十足的可以用于高速數(shù)據(jù)分析的NoSQL��。
此外,目前大多數(shù)服務(wù)廠商都已經(jīng)推出了帶4GB以上SSD的解決方案��,利用內(nèi)存+SSD�����,也可以輕易達(dá)到內(nèi)存分析的性能�����。隨著SSD的發(fā)展�����,內(nèi)存數(shù)據(jù)分析必然能得到更加廣泛的應(yīng)用�。
BI級(jí)別指的是那些對(duì)于內(nèi)存來(lái)說(shuō)太大的數(shù)據(jù)量,但一般可以將其放入傳統(tǒng)的BI產(chǎn)品和專(zhuān)門(mén)設(shè)計(jì)的BI數(shù)據(jù)庫(kù)之中進(jìn)行分析�。目前主流的BI產(chǎn)品都有支持TB級(jí)以上的數(shù)據(jù)分析方案。種類(lèi)繁多�,就不具體列舉了。
海量級(jí)別指的是對(duì)于數(shù)據(jù)庫(kù)和BI產(chǎn)品已經(jīng)完全失效或者成本過(guò)高的數(shù)據(jù)量�。海量數(shù)據(jù)級(jí)別的優(yōu)秀企業(yè)級(jí)產(chǎn)品也有很多,但基于軟硬件的成本原因,目前大多數(shù)互聯(lián)網(wǎng)企業(yè)采用Hadoop的HDFS分布式文件系統(tǒng)來(lái)存儲(chǔ)數(shù)據(jù),并使用MapReduce進(jìn)行分析���。本文稍后將主要介紹Hadoop上基于 MapReduce的一個(gè)多維數(shù)據(jù)分析平臺(tái)。
根據(jù)不同的業(yè)務(wù)需求���,數(shù)據(jù)分析的算法也差異巨大�,而數(shù)據(jù)分析的算法復(fù)雜度和架構(gòu)是緊密關(guān)聯(lián)的��。舉個(gè)例子�����,Redis是一個(gè)性能非常高的內(nèi)存Key- Value NoSQL�,它支持List和Set�����、SortedSet等簡(jiǎn)單集合����,如果你的數(shù)據(jù)分析需求簡(jiǎn)單地通過(guò)排序,鏈表就可以解決���,同時(shí)總的數(shù)據(jù)量不大于內(nèi)存(準(zhǔn)確地說(shuō)是內(nèi)存加上虛擬內(nèi)存再除以2)�,那么無(wú)疑使用Redis會(huì)達(dá)到非常驚人的分析性能���。
還有很多易并行問(wèn)題(Embarrassingly Parallel)����,計(jì)算可以分解成完全獨(dú)立的部分,或者很簡(jiǎn)單地就能改造出分布式算法�����,比如大規(guī)模臉部識(shí)別��、圖形渲染等��,這樣的問(wèn)題自然是使用并行處理集群比較適合��。
而大多數(shù)統(tǒng)計(jì)分析���,機(jī)器學(xué)習(xí)問(wèn)題可以用MapReduce算法改寫(xiě)���。MapReduce目前最擅長(zhǎng)的計(jì)算領(lǐng)域有流量統(tǒng)計(jì)、推薦引擎��、趨勢(shì)分析�����、用戶(hù)行為分析、數(shù)據(jù)挖掘分類(lèi)器�����、分布式索引等�。
面對(duì)大數(shù)據(jù)OLAP分析的一些問(wèn)題
OLAP分析需要進(jìn)行大量的數(shù)據(jù)分組和表間關(guān)聯(lián),而這些顯然不是NoSQL和傳統(tǒng)數(shù)據(jù)庫(kù)的強(qiáng)項(xiàng)�,往往必須使用特定的針對(duì)BI優(yōu)化的數(shù)據(jù)庫(kù)。比如絕大多數(shù)針對(duì)BI優(yōu)化的數(shù)據(jù)庫(kù)采用了列存儲(chǔ)或混合存儲(chǔ)�����、壓縮��、延遲加載�、對(duì)存儲(chǔ)數(shù)據(jù)塊的預(yù)統(tǒng)計(jì)�、分片索引等技術(shù)。
Hadoop平臺(tái)上的OLAP分析�����,同樣存在這個(gè)問(wèn)題����,F(xiàn)acebook針對(duì)Hive開(kāi)發(fā)的RCFile數(shù)據(jù)格式���,就是采用了上述的一些優(yōu)化技術(shù),從而達(dá)到了較好的數(shù)據(jù)分析性能�����。如圖2所示�����。
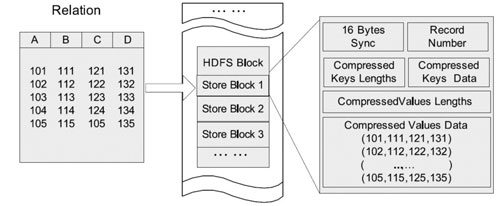
圖2 RCFile的行列混合存
然而����,對(duì)于Hadoop平臺(tái)來(lái)說(shuō),單單通過(guò)使用Hive模仿出SQL����,對(duì)于數(shù)據(jù)分析來(lái)說(shuō)遠(yuǎn)遠(yuǎn)不夠,首先Hive雖然將HiveQL翻譯MapReduce的時(shí)候進(jìn)行了優(yōu)化��,但依然效率低下�。多維分析時(shí)依然要做事實(shí)表和維度表的關(guān)聯(lián),維度一多性能必然大幅下降�����。其次,RCFile的行列混合存儲(chǔ)模式����,事實(shí)上限制死了數(shù)據(jù)格式,也就是說(shuō)數(shù)據(jù)格式是針對(duì)特定分析預(yù)先設(shè)計(jì)好的����,一旦分析的業(yè)務(wù)模型有所改動(dòng),海量數(shù)據(jù)轉(zhuǎn)換格式的代價(jià)是極其巨大的�。最后,HiveQL對(duì)OLAP業(yè)務(wù)分析人員依然是非常不友善的��,維度和度量才是直接針對(duì)業(yè)務(wù)人員的分析語(yǔ)言��。
而且目前OLAP存在的最大問(wèn)題是:業(yè)務(wù)靈活多變���,必然導(dǎo)致業(yè)務(wù)模型隨之經(jīng)常發(fā)生變化���,而業(yè)務(wù)維度和度量一旦發(fā)生變化�����,技術(shù)人員需要把整個(gè) Cube(多維立方體)重新定義并重新生成���,業(yè)務(wù)人員只能在此Cube上進(jìn)行多維分析�,這樣就限制了業(yè)務(wù)人員快速改變問(wèn)題分析的角度,從而使所謂的BI系統(tǒng)成為死板的日常報(bào)表系統(tǒng)�。
使用Hadoop進(jìn)行多維分析,首先能解決上述維度難以改變的問(wèn)題����,利用Hadoop中數(shù)據(jù)非結(jié)構(gòu)化的特征,采集來(lái)的數(shù)據(jù)本身就是包含大量冗余信息的�。同時(shí)也可以將大量冗余的維度信息整合到事實(shí)表中,這樣可以在冗余維度下靈活地改變問(wèn)題分析的角度����。其次利用Hadoop MapReduce強(qiáng)大的并行化處理能力,無(wú)論OLAP分析中的維度增加多少����,開(kāi)銷(xiāo)并不顯著增長(zhǎng)。換言之�����,Hadoop可以支持一個(gè)巨大無(wú)比的Cube��,包含了無(wú)數(shù)你想到或者想不到的維度,而且每次多維分析����,都可以支持成千上百個(gè)維度,并不會(huì)顯著影響分析的性能�。
因此,我們的大數(shù)據(jù)分析架構(gòu)在這個(gè)巨大Cube的支持下��,直接把維度和度量的生成交給業(yè)務(wù)人員��,由業(yè)務(wù)人員自己定義好維度和度量之后�,將業(yè)務(wù)的維度和度量直接翻譯成MapReduce運(yùn)行,并最終生成報(bào)表�。可以簡(jiǎn)單理解為用戶(hù)快速自定義的“MDX”(多維表達(dá)式�,或者多維立方體查詢(xún))語(yǔ)言 →MapReduce的轉(zhuǎn)換工具。同時(shí)OLAP分析和報(bào)表結(jié)果的展示�����,依然兼容傳統(tǒng)的BI和報(bào)表產(chǎn)品���。如圖3所示���。
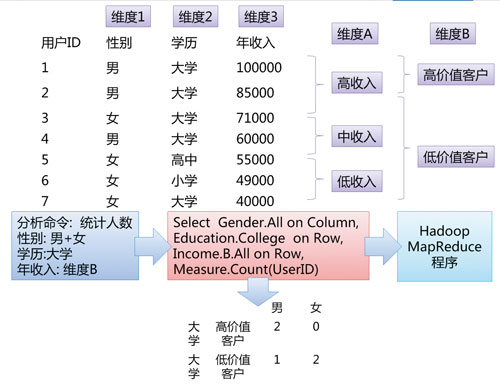
圖3 MDX→MapReduce簡(jiǎn)略示意圖
圖3可以看出��,在年收入上,用戶(hù)可以自己定義子維度�����。另外���,用戶(hù)也可以在列上自定義維度�,比如將性別和學(xué)歷合并為一個(gè)維度�����。由于Hadoop數(shù)據(jù)的非結(jié)構(gòu)化特征����,維度可以根據(jù)業(yè)務(wù)需求任意地劃分和重組。
一種Hadoop多維分析平臺(tái)的架構(gòu)
整個(gè)架構(gòu)由四大部分組成:數(shù)據(jù)采集模塊����、數(shù)據(jù)冗余模塊、維度定義模塊����、并行分析模塊。如圖4所示。
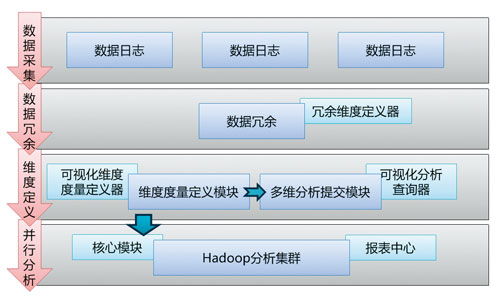
圖4 Hadoop多維分析平臺(tái)架構(gòu)圖
數(shù)據(jù)采集模塊采用了Cloudera的Flume�,將海量的小日志文件進(jìn)行高速傳輸和合并,并能夠確保數(shù)據(jù)的傳輸安全性��。單個(gè)collector宕機(jī)之后��,數(shù)據(jù)也不會(huì)丟失����,并能將agent數(shù)據(jù)自動(dòng)轉(zhuǎn)移到其他的colllecter處理,不會(huì)影響整個(gè)采集系統(tǒng)的運(yùn)行��。如圖5所示���。
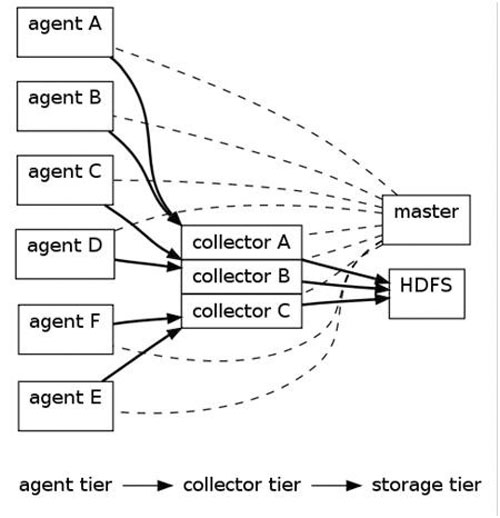
圖5 采集模塊
數(shù)據(jù)冗余模塊不是必須的���,但如果日志數(shù)據(jù)中沒(méi)有足夠的維度信息,或者需要比較頻繁地增加維度��,則需要定義數(shù)據(jù)冗余模塊�。通過(guò)冗余維度定義器定義需要冗余的維度信息和來(lái)源(數(shù)據(jù)庫(kù)、文件���、內(nèi)存等)���,并指定擴(kuò)展方式����,將信息寫(xiě)入數(shù)據(jù)日志中��。在海量數(shù)據(jù)下�,數(shù)據(jù)冗余模塊往往成為整個(gè)系統(tǒng)的瓶頸����,建議使用一些比較快的內(nèi)存NoSQL來(lái)冗余原始數(shù)據(jù),并采用盡可能多的節(jié)點(diǎn)進(jìn)行并行冗余;或者也完全可以在Hadoop中執(zhí)行批量Map���,進(jìn)行數(shù)據(jù)格式的轉(zhuǎn)化��。
維度定義模塊是面向業(yè)務(wù)用戶(hù)的前端模塊��,用戶(hù)通過(guò)可視化的定義器從數(shù)據(jù)日志中定義維度和度量��,并能自動(dòng)生成一種多維分析語(yǔ)言��,同時(shí)可以使用可視化的分析器通過(guò)GUI執(zhí)行剛剛定義好的多維分析命令�����。
并行分析模塊接受用戶(hù)提交的多維分析命令���,并將通過(guò)核心模塊將該命令解析為Map-Reduce�����,提交給Hadoop集群之后�����,生成報(bào)表供報(bào)表中心展示�����。
核心模塊是將多維分析語(yǔ)言轉(zhuǎn)化為MapReduce的解析器���,讀取用戶(hù)定義的維度和度量,將用戶(hù)的多維分析命令翻譯成MapReduce程序����。核心模塊的具體邏輯如圖6所示。
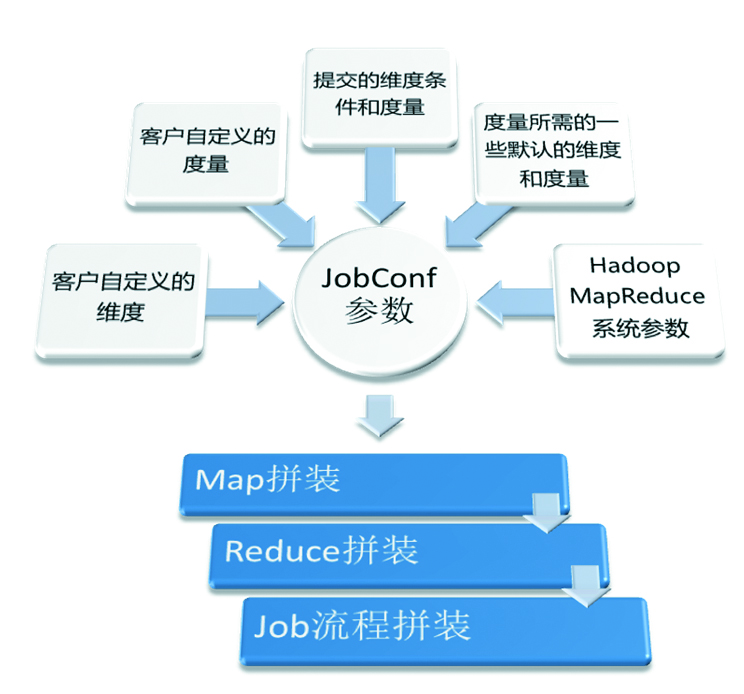
圖6 核心模塊的邏輯
圖6中根據(jù)JobConf參數(shù)進(jìn)行Map和Reduce類(lèi)的拼裝并不復(fù)雜��,難點(diǎn)是很多實(shí)際問(wèn)題很難通過(guò)一個(gè)MapReduce Job解決����,必須通過(guò)多個(gè)MapReduce Job組成工作流(WorkFlow)�,這里是最需要根據(jù)業(yè)務(wù)進(jìn)行定制的部分��。圖7是一個(gè)簡(jiǎn)單的MapReduce工作流的例子��。

圖7 MapReduce WorkFlow例子
MapReduce的輸出一般是統(tǒng)計(jì)分析的結(jié)果����,數(shù)據(jù)量相較于輸入的海量數(shù)據(jù)會(huì)小很多���,這樣就可以導(dǎo)入傳統(tǒng)的數(shù)據(jù)報(bào)表產(chǎn)品中進(jìn)行展現(xiàn)�。
結(jié)束語(yǔ)
當(dāng)然�,這樣的多維分析架構(gòu)也不是沒(méi)有缺點(diǎn)。由于MapReduce本身就是以蠻力去掃描大部分?jǐn)?shù)據(jù)進(jìn)行計(jì)算��,因此無(wú)法像傳統(tǒng)BI產(chǎn)品一樣對(duì)條件查詢(xún)做優(yōu)化����,也沒(méi)有緩存的概念。往往很多很小的查詢(xún)需要“興師動(dòng)眾”��。盡管如此�����,開(kāi)源的Hadoop還是解決了很多人在大數(shù)據(jù)下的分析問(wèn)題,真可謂是“功德無(wú)量”��。
Hadoop集群軟硬件的花費(fèi)極低�,每GB存儲(chǔ)和計(jì)算的成本是其他企業(yè)級(jí)產(chǎn)品的百分之一甚至千分之一,性能卻非常出色�����。我們可以輕松地進(jìn)行千億乃至萬(wàn)億數(shù)據(jù)級(jí)別的多維統(tǒng)計(jì)分析和機(jī)器學(xué)習(xí)�。
6月29日的Hadoop Summit 2011上,Yahoo!剝離出一家專(zhuān)門(mén)負(fù)責(zé)Hadoop開(kāi)發(fā)和運(yùn)維的公司Hortonworks�����。Cloudera帶來(lái)了大量的輔助工具����,MapR帶來(lái)了號(hào)稱(chēng)三倍于Hadoop MapReduce速度的并行計(jì)算平臺(tái)。Hadoop必將很快迎來(lái)下一代產(chǎn)品��,屆時(shí)其必然擁有更強(qiáng)大的分析能力和更便捷的使用方式��,從而真正輕松面對(duì)未來(lái)海量數(shù)據(jù)的挑戰(zhàn)����。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試�,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情�����;
? 想學(xué)習(xí)CDA考試教材�,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫(kù)�����,點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情�����;
? 想了解CDA考試含金量�����,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330