隱樹模型的學習
隱樹模型的學習是一個對模型逐步優(yōu)化的過程,優(yōu)化的目標函數(shù)是一個稱為貝葉斯信息準則(Bayes information criterion����, 簡稱BIC) 的函數(shù):
BIC(m|D) = max θ log P(D|m, θ) – d(m)logN/2
BIC準則要求模型與數(shù)據(jù)盡量緊密地擬合,但其復雜不能過高��。所以式中第一項表示擬合程度���,而第二項是對于模型復雜度的一個懲罰項����。我們的優(yōu)化過程是一個基于搜索的爬山算法(Hill-Climbing)。以只包含一個隱變量的簡單的隱樹模型作為搜索的起始模型��,在搜索的過程中�,逐步引入新的隱變量、增加隱變量的取值個數(shù)�����、或者調(diào)整變量之間的連接�����。這是一個逐步修改模型的過程�,在這個過程中,模型與數(shù)據(jù)的擬合程度不斷改進���,從而BIC分逐步增加��。當模型就變得太復雜時��,BIC會不升反降���,于是搜索過程停止�。
隱樹模型的學習是一個非常耗時的過程�����,主要原因在于對于BIC分數(shù)的計算�。BIC函數(shù)的第一項叫做最大似然函數(shù),在模型包含缺失值或者隱變量時���,計算最大似然函數(shù)需要調(diào)用EM(Expectation-Maximization)算法。盡管我們已經(jīng)對于限制了模型結(jié)構(gòu)為簡單的樹狀結(jié)構(gòu)�,但是在這樣的模型上進行EM的計算依然是非常困難。圍繞隱樹模型的很多工作都是在研究如何對模型學習進行加速的���,這兒就不贅述了��。
基于隱樹模型的多維聚類分析實例

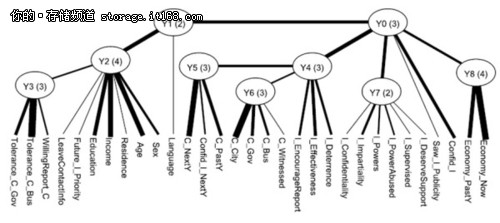
我們以一個真實的數(shù)據(jù)分析實例來展現(xiàn)多維聚類分析��。數(shù)據(jù)來自某地區(qū)的關(guān)于貪污的社會調(diào)查問卷���。通過一些數(shù)據(jù)預(yù)處理,我們的數(shù)據(jù)(如圖所示)包含了1200份的問卷,以及31個問題��。比如說C_City表示被訪問者對于該地區(qū)的貪污普遍性的看法����,可以有4個選項,分別是非常普遍��,普遍��,不普遍�,以及非常不普遍。C_Gov和C_Bus分別表示受訪者對于該地區(qū)政府部門或商業(yè)部門的貪污普遍性的看法����,同樣也有四個選項。Tolerance_C_Gov和Tolerance_C_Bus則分別表示受訪者對于該地區(qū)的政府部門以及商業(yè)部門的貪污的容忍程度�,可以選擇完全不能容忍,不能容忍���,能容忍����,完全能容忍��。數(shù)據(jù)表里面的-1表示受訪者對該問題的回答缺失。
利用隱樹的學習算法����,我們從這個數(shù)據(jù)得到了一個如圖所示的模型。葉節(jié)點對應(yīng)問卷問題��,即顯變量�����。中間結(jié)點�,Y0-Y8是從數(shù)據(jù)中發(fā)現(xiàn)的隱變量,括號里面的數(shù)字表示這個變量所取的狀態(tài)個數(shù)���。我們發(fā)現(xiàn)這些隱變量都有一定的意義,比如�����,Y2和問卷中的Sex�����,Age��,Income,Education這些問題緊密連接�,說明Y2應(yīng)該是表示受訪人的人口統(tǒng)計信息。Y3和問卷中的Tolerance_C_Gov和Tolerance_C_Bus緊密聯(lián)系�,說明Y3是反映受訪者總體對于貪污的看法。
模型中的每個隱變量表示數(shù)據(jù)聚類的一種方式�。比如,變量Y2有4個值��,說明Y2提示數(shù)據(jù)可以分成四個類����。這種聚類主要基于Sex,Age�,Income,Education這些人口統(tǒng)計信息相關(guān)變量的����,所以可以說當我們關(guān)注人群的人口統(tǒng)計信息這個側(cè)面時,我們可以根據(jù)Y2把人群分成四類���。具體地研究這四類的類條件概率(Class-Conditional ProbabilityDistribution)特性��,我們進一步發(fā)現(xiàn)它們分別代表:低收入的年輕人群��,低收入的女性人群����,受過高等教育的高收入人群,以及只接受初等教育的一般收入人群���。同時,我們看到Y(jié)3有3個取值�,這說明從人群對于貪污總體看法這個側(cè)面出發(fā),可以把人群分成三類�����,分別是對于貪污完全不能容忍的人群��,對于貪污比較不能容忍的人群�,對于貪污可以容忍的人群。同樣地����,我們的聚類也可以基于其他隱變量所代表的側(cè)面���。這樣從模型中我們得到了9種聚類的方法�,達到了多維同時聚類的效果�����。











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330