大數(shù)據(jù)處理:百分點(diǎn)實(shí)時(shí)計(jì)算架構(gòu)和算法
當(dāng)今時(shí)代���,數(shù)據(jù)不再昂貴�����,但從海量數(shù)據(jù)中獲取價(jià)值變得昂貴��,而要及時(shí)獲取價(jià)值則更加昂貴��,這正是大數(shù)據(jù)實(shí)時(shí)計(jì)算越來越流行的原因����。以百分點(diǎn)公司為例�,在高峰期每秒鐘會(huì)有近萬HTTP請(qǐng)求發(fā)送到百分點(diǎn)服務(wù)器上�����,這些請(qǐng)求包含了用戶行為和個(gè)性化推薦請(qǐng)求。如何從這些數(shù)據(jù)中快速挖掘用戶興趣偏好并作出效果不錯(cuò)的推薦呢��?這是百分點(diǎn)推薦引擎面臨的首要問題。本文將從系統(tǒng)架構(gòu)和算法兩方面全介紹百分點(diǎn)公司在實(shí)時(shí)計(jì)算方面的經(jīng)驗(yàn)和心得體會(huì)���,供讀者參考��。
a) 實(shí)時(shí)計(jì)算架構(gòu)
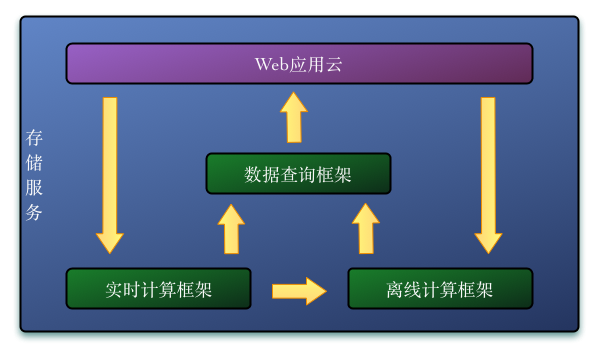
圖 1百分點(diǎn)大數(shù)據(jù)平臺(tái)原理示意圖
工欲善其事���,必先利其器。一個(gè)穩(wěn)定可靠且高效的底層架構(gòu)是實(shí)時(shí)計(jì)算的必要基礎(chǔ)�。圖 1給出了百分點(diǎn)數(shù)據(jù)大平臺(tái)的總體框架,如圖所示,大數(shù)據(jù)平臺(tái)包含數(shù)據(jù)存儲(chǔ)和數(shù)據(jù)處理兩個(gè)層次。
存儲(chǔ)服務(wù)層提供了數(shù)據(jù)處理層需要的各類分布式存儲(chǔ),包括分布式文件系統(tǒng)(Hadoop HDFS)�、分布式SQL數(shù)據(jù)庫(MySQL)����、分布式NoSQL數(shù)據(jù)庫(Redis����、MongoDB、HBase)�����、分布式消息隊(duì)列(Apache Kafka)、分布式搜索引擎(Apache Solr)以及必不可少的Apache Zookeeper���。
數(shù)據(jù)處理層由四個(gè)部分組成�。其中Web應(yīng)用云包含了所有直接面對(duì)用戶的Web服務(wù)���,每個(gè)Web應(yīng)用都會(huì)產(chǎn)生Web日志以及其他實(shí)時(shí)數(shù)據(jù)��,這些數(shù)據(jù)一方面會(huì)及時(shí)交由實(shí)時(shí)計(jì)算框架進(jìn)行處理�����,另一方面也會(huì)定期同步至離線計(jì)算框架;實(shí)時(shí)計(jì)算框架會(huì)處理接收到的實(shí)時(shí)數(shù)據(jù)����,并將處理結(jié)果輸出到數(shù)據(jù)查詢框架或者離線計(jì)算框架;離線計(jì)算框架則定期對(duì)數(shù)據(jù)進(jìn)行處理���,并將處理結(jié)果輸出至數(shù)據(jù)查詢框架�;數(shù)據(jù)查詢框架提供了一系列應(yīng)用接口供程序調(diào)取需要的各項(xiàng)數(shù)據(jù)����,同時(shí)提供了一些Web工具幫助業(yè)務(wù)人員對(duì)海量數(shù)據(jù)進(jìn)行統(tǒng)計(jì)�、匯總和分析��。
在百分點(diǎn)大數(shù)據(jù)平臺(tái)中�����,與實(shí)時(shí)計(jì)算密切相關(guān)的有實(shí)時(shí)計(jì)算框架和數(shù)據(jù)查詢框架�����,這部分的組件架構(gòu)和數(shù)據(jù)流如圖 2所示���。
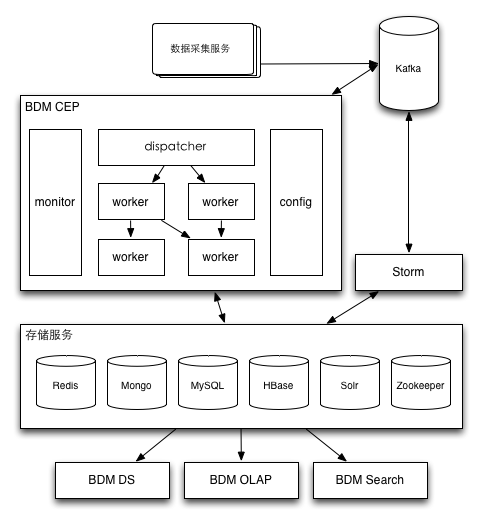
圖 2實(shí)時(shí)計(jì)算框架和數(shù)據(jù)查詢框架示意
從圖上可以看出�,數(shù)據(jù)采集服務(wù)會(huì)將收集到的實(shí)時(shí)數(shù)據(jù)推送到消息隊(duì)列Kafka中���;Kafka中的數(shù)據(jù)會(huì)被兩個(gè)處理平臺(tái)BDM CEP(Big Data Management Complex Event Processing)和Storm消費(fèi)并處理���。Storm是當(dāng)下比較流行的開源流處理框架,百分點(diǎn)公司在2013年中開始使用Storm進(jìn)行數(shù)據(jù)清洗�����、統(tǒng)計(jì)和一部分分析任務(wù)。在引入Storm之前����,百分點(diǎn)所有的實(shí)時(shí)計(jì)算都是基于BDM CEP進(jìn)行的,它是我們基于中間件ICE開發(fā)的一套流處理平臺(tái)����。BDM CEP包含有四類組件:dispatcher負(fù)責(zé)從Kafka中讀取消息,根據(jù)消息內(nèi)容分發(fā)給相應(yīng)的worker;worker復(fù)雜處理接收到的消息�����,并將處理結(jié)果傳遞給其他worker或者輸出到各類存儲(chǔ)服務(wù)中���;config負(fù)責(zé)維護(hù)dispatcher和worker的交互關(guān)系和配置信息����,并在交互關(guān)系或配置更新時(shí)及時(shí)通知dispatcher和worker;monitor負(fù)責(zé)監(jiān)控dispatcher和worker的運(yùn)行情況�,把監(jiān)控信息提交給Ganglia����,monitor還負(fù)責(zé)系統(tǒng)異常時(shí)的報(bào)警,以及dispatcher和worker發(fā)生故障時(shí)進(jìn)行重啟和遷移���。數(shù)據(jù)查詢框架由圖中最下層的三個(gè)組件組成���,其中BDM DS(Data Source)封裝了一系列的數(shù)據(jù)查詢邏輯并以REST API和ICE服務(wù)的形式供各種應(yīng)用調(diào)用�;BDM OLAP(Online Analytical Processing)提供了實(shí)時(shí)查詢用戶行為和標(biāo)簽明細(xì)���,以及近實(shí)時(shí)的用戶多維度統(tǒng)計(jì)�����、匯總和分析功能�����,這些功能是以REST API和Web應(yīng)用方式提供的����;BDM Search是對(duì)Solr和HBase的一次封裝���,以REST API和ICE服務(wù)方式對(duì)外提供近實(shí)時(shí)搜索功能���。
百分點(diǎn)公司的主要服務(wù)都是運(yùn)行在這套架構(gòu)上的,它擁有良好的穩(wěn)定性和擴(kuò)展性�,一般來說只需要增加水平擴(kuò)展結(jié)點(diǎn)即可提高數(shù)據(jù)處理能力�����,這為百分點(diǎn)業(yè)務(wù)的穩(wěn)定發(fā)展奠定了技術(shù)基礎(chǔ)��。
b) 實(shí)時(shí)計(jì)算算法
要真正實(shí)現(xiàn)大數(shù)據(jù)實(shí)時(shí)計(jì)算��,光有框架是不行的�����,還必須針對(duì)特定業(yè)務(wù)開發(fā)特定的處理流程和算法����。相比較離線計(jì)算而言�����,實(shí)時(shí)計(jì)算在算法方面需要考慮的更多����,這是因?yàn)閷?shí)時(shí)計(jì)算能夠用到的存儲(chǔ)資源遠(yuǎn)不如離線�,而且處理過程的時(shí)間限制要比離線計(jì)算嚴(yán)格,這都要求實(shí)時(shí)計(jì)算算法必須做相當(dāng)多的優(yōu)化�。在這一節(jié)中����,筆者將以海量計(jì)數(shù)問題為例介紹百分點(diǎn)公司在實(shí)時(shí)計(jì)算算法方面的經(jīng)驗(yàn)�����。
目前���,百分點(diǎn)數(shù)據(jù)平臺(tái)上包含了近千萬的電商單品數(shù)據(jù)����,實(shí)時(shí)追蹤這些單品的瀏覽和交易數(shù)據(jù)是必須的��,這也是做個(gè)性化推薦���、商品畫像���、銷量預(yù)測和用戶畫像等業(yè)務(wù)的必要前提。我們的問題是:如何設(shè)計(jì)一種算法使得我們可以實(shí)時(shí)查看任意單品最近24小時(shí)的瀏覽量��?這個(gè)問題描述起來很簡單��,但稍加思索就會(huì)發(fā)現(xiàn)做起來并不容易�。下面我們先給出一個(gè)簡單方案����,而后按照一定的原則逐步精化到最佳方案���。
c) 簡單方案
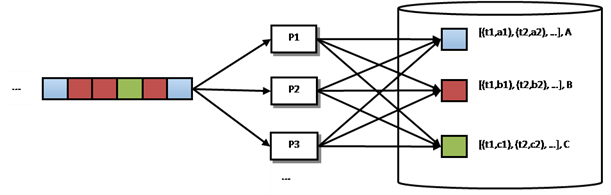
圖 3按秒計(jì)數(shù)方案
看到這個(gè)問題時(shí)��,大部分讀者會(huì)很快想到如圖 3所示的算法方案����。圖中紅色����、藍(lán)色和綠色的方塊分別表示不同的單品。在這個(gè)方案中�����,我們?yōu)槊總€(gè)單品保存一份瀏覽信息����,它包含兩個(gè)數(shù)據(jù)結(jié)構(gòu):
d) 歷史瀏覽量列表(簡稱歷史),一個(gè)列表����,列表中每個(gè)元素包含一個(gè)時(shí)間戳和一個(gè)整數(shù),分別代表過去24小時(shí)中的某一秒及這一秒鐘的瀏覽量�,按時(shí)間順序排序。這個(gè)列表的最長會(huì)包含24*3600=86400個(gè)元素����,但一般情況下極少有單品時(shí)時(shí)刻刻都被瀏覽,我們可以假設(shè)這個(gè)列表的平均長度不超過10000�。
e) 累計(jì)瀏覽量(簡稱累計(jì)量),一個(gè)整數(shù)�,代表截止到最后一次訪問時(shí)的瀏覽量。
如圖所示���,假設(shè)藍(lán)色單品對(duì)應(yīng)的數(shù)據(jù)是 [(t1, a1)���, (t2, a2), …���, (tn, an)]和A��。這表示t1時(shí)刻的該單品瀏覽量是a1��,t2時(shí)刻是a2���,tn是最后一次記錄到瀏覽該單品的時(shí)刻�,瀏覽量是an�。截止到tn,該單品的總瀏覽量是A���。
當(dāng)單品瀏覽源源不斷進(jìn)入到消息隊(duì)列時(shí)��,處理進(jìn)程(或線程)P1��,P2…會(huì)實(shí)時(shí)讀取到這些信息����,并修改對(duì)應(yīng)單品的數(shù)據(jù)信息����。例如,P1讀取到t時(shí)刻對(duì)藍(lán)色單品的瀏覽記錄時(shí)����,會(huì)進(jìn)行下面的操作:
f) 得到當(dāng)前時(shí)刻ct;
g) 對(duì)數(shù)據(jù)庫中藍(lán)色單品數(shù)據(jù)加鎖,加鎖成功后讀取出數(shù)據(jù)��,假設(shè)歷史是[(t1, a1)��, (t2, a2), …����, (tn, an)],累計(jì)量是A;
h) 累計(jì)量遞增����,即從A修改為A+1
i) 如果ct=tn����,則更新歷史為[(t1, a1), (t2, a2)�, …, (tn, an+1)]�����,否則更新為[(t1, a1)����, (t2, a2), …�����, (tn, an), (ct,1)];最后刪除時(shí)間戳小于ct-24*3600的列表元素�,刪除的同時(shí)從累計(jì)量中減去對(duì)應(yīng)時(shí)刻的瀏覽量,例如只有元素t1> ct-24*3600�,則操作完成后的瀏覽量為A+1-a1;
j) 將新的歷史和累計(jì)量輸出至數(shù)據(jù)庫,釋放鎖��。
不難驗(yàn)證這個(gè)方案是可以正確得出每個(gè)單品24小時(shí)內(nèi)的瀏覽量的����,并且只要在資源(計(jì)算、存儲(chǔ)和網(wǎng)絡(luò))充足的情況下�����,數(shù)據(jù)庫中單品的瀏覽量是實(shí)時(shí)更新的��。這個(gè)方案也是分布式實(shí)時(shí)計(jì)算中最簡單最常見的一種模式����。
k) 避免鎖
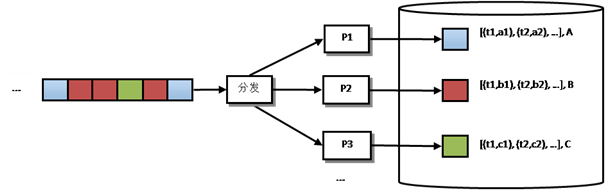
圖 4不包含鎖的方案
第一個(gè)方案中需要對(duì)數(shù)據(jù)庫加鎖,無論加鎖粒度多細(xì)���,都會(huì)嚴(yán)重影響計(jì)算效率����。雖然像Redis一類的內(nèi)存數(shù)據(jù)庫提供了incr這樣的原子操作,但這種操作多數(shù)情況下只適用于整型數(shù)據(jù)�����,并不適合本問題的歷史數(shù)據(jù)���。
要想提高實(shí)時(shí)處理效率�����,避免鎖是非常重要的。一種常見的做法是將并行操作串行化�����,就像MapReduce中的Reduce階段一樣���,將key相同的數(shù)據(jù)交由同一個(gè)reducer處理�����?����;谶@個(gè)原理����,我們可以將方案改造為如圖 4所示,我們新增一個(gè)數(shù)據(jù)分發(fā)處理過程�,它的作用是保證同一個(gè)單品的所有數(shù)據(jù)都會(huì)發(fā)送給同一個(gè)處理程序。例如將藍(lán)色單品交由P1處理�����,紅色交由P2處理��,綠色交由P3處理����。這樣P1在處理過程中不需要對(duì)數(shù)據(jù)庫加鎖,因?yàn)椴淮嬖谫Y源競爭��。這樣可以極大的提高計(jì)算效率���,于是整個(gè)計(jì)算過程變?yōu)椋?/span>
l) 得到當(dāng)前時(shí)刻ct;
m) 讀取數(shù)據(jù)庫中藍(lán)色單品信息����,假設(shè)歷史是[(t1, a1)���, (t2, a2)�, …, (tn, an)]�����,累計(jì)量是A;
n) 累計(jì)遞增�����,即從A修改為A+1
o) 如果ct=tn��,則更新歷史為[(t1, a1)���, (t2, a2), …��, (tn, an+1)]�,否則更新為[(t1, a1), (t2, a2)�, …, (tn, an)����, (ct,1)];最后刪除時(shí)間戳小于ct-24*3600的列表元素��,刪除的同時(shí)從累量中減去對(duì)應(yīng)時(shí)刻的瀏覽量����;
p) 將新的歷史和累計(jì)量輸出至數(shù)據(jù)庫����。
步驟b)和e)省去了鎖操作,整個(gè)系統(tǒng)的并發(fā)性和吞吐量會(huì)得到大大提高�。當(dāng)然,沒有免費(fèi)的午餐����,這種方案的缺點(diǎn)在于存在單點(diǎn)隱患,例如一旦P1由于某些原因掛掉了����,那么藍(lán)色單品的數(shù)據(jù)將得不到及時(shí)處理,計(jì)數(shù)結(jié)果將無法保證實(shí)時(shí)��。這種計(jì)算過程對(duì)系統(tǒng)監(jiān)控和故障轉(zhuǎn)移會(huì)有很高的要求����。
q) 數(shù)據(jù)分層
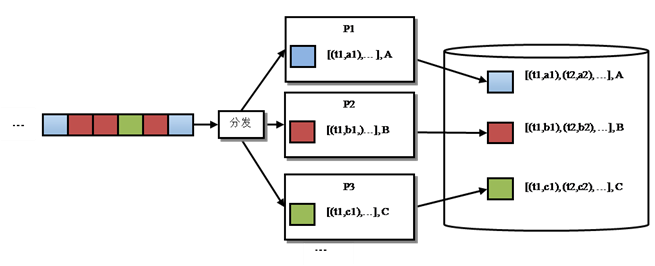
圖 5帶有本地緩存的方案
方案二已經(jīng)可以大大提高計(jì)算效率,但這還不夠��,我們可以看到在計(jì)算步驟b)和e)中總是要把歷史和累計(jì)量同時(shí)從數(shù)據(jù)庫中讀出或?qū)懭耄瑢?shí)際上這是沒有必要的���,因?yàn)橹挥欣塾?jì)量才是外部必須使用的數(shù)據(jù)���,而歷史只是算法的中間數(shù)據(jù)。這樣��,我們可以區(qū)別對(duì)待歷史和累計(jì)量����,我們將歷史和累計(jì)量都緩存在計(jì)算進(jìn)程中,定期更新歷史至數(shù)據(jù)庫���,而累計(jì)量則實(shí)時(shí)更新�����。新的方案如圖 5所示,計(jì)算過程變?yōu)椋?/span>
r) 得到當(dāng)前時(shí)刻ct;
s) 如果本地沒有藍(lán)色單品的信息����,則從數(shù)據(jù)庫中讀取藍(lán)色單品信息;否則直接使用本地緩存的信息�����。假設(shè)歷史是[(t1, a1), (t2, a2)�, …, (tn, an)]���,累計(jì)量是A;
t) 累計(jì)量遞增�����,即從A修改為A+1
u) 如果ct=tn��,則更新歷史為[(t1, a1)��, (t2, a2)����, …����, (tn, an+1)],否則更新為[(t1, a1)��, (t2, a2), …�����, (tn, an)����, (ct,1)];最后刪除時(shí)間戳小于ct-24*3600的列表元素,刪除的同時(shí)從累計(jì)量中減去對(duì)應(yīng)時(shí)刻的瀏覽量��;
v) 將新的累計(jì)量輸出至數(shù)據(jù)庫�����;如果滿足一定的條件(例如上次輸出時(shí)間足夠久遠(yuǎn)����,或者處理的消息量達(dá)到一定數(shù)量),則將歷史輸出至數(shù)據(jù)庫�����。
這種方案可以大大降低數(shù)據(jù)庫壓力�、數(shù)據(jù)IO和序列化反序列化次數(shù)��,從而提高整個(gè)系統(tǒng)的處理效率�。數(shù)據(jù)分層實(shí)際上是計(jì)算機(jī)中一種常用的路數(shù)�,例如硬件中的高速緩存/內(nèi)存/磁盤��,系統(tǒng)IO中的緩沖區(qū)/磁盤文件�����,數(shù)據(jù)庫的內(nèi)存索引��、系統(tǒng)DNS緩存等等�����。我們使用的開源搜索引擎Solr就使用了同樣的思路達(dá)到近實(shí)時(shí)索引�。Solr包含磁盤全量索引和實(shí)時(shí)增加的內(nèi)存增量索引,并引入了“soft提交”的方式更新新索引���。新數(shù)據(jù)到達(dá)后�����,Solr會(huì)使用“soft”提交的方式更新內(nèi)存增量索引��,在檢索的時(shí)候通過同時(shí)請(qǐng)求全量索引和增量索引并合并的方式獲得到最新的數(shù)據(jù)����。之后會(huì)在服務(wù)器空閑的時(shí)候,Solr會(huì)把內(nèi)存增量索引合并到磁盤全量索引中保證數(shù)據(jù)完整�。
當(dāng)然,這種方案也對(duì)系統(tǒng)的穩(wěn)定性提出了更高的要求�����,因?yàn)橐坏㏄1掛掉那么它緩存的數(shù)據(jù)將丟失�,及時(shí)P1及時(shí)重啟,這些數(shù)據(jù)也無法恢復(fù)��,那么在一段時(shí)間內(nèi)我們將無法得到準(zhǔn)確的實(shí)時(shí)瀏覽量�。
w) 模糊化
現(xiàn)在,我們來考慮存儲(chǔ)資源問題�����。假設(shè)時(shí)間戳和整型都用long類型(8字節(jié))保存�,那么按照方案一中的估計(jì),我們對(duì)每個(gè)單品的需要記錄的數(shù)據(jù)大小約為10000×(8+8)+8=16008字節(jié)≈156KB�����,1000萬單品的數(shù)據(jù)總量將超過1T�,如果考慮到數(shù)據(jù)庫和本地緩存因素��,那么整個(gè)系統(tǒng)需要的存儲(chǔ)量至少是2T!這對(duì)于計(jì)數(shù)這個(gè)問題而言顯然是得不償失的,我們必須嘗試將數(shù)據(jù)量降低���,在這個(gè)問題中可行的是降低歷史的存儲(chǔ)精度���。我們將歷史定義為小時(shí)級(jí)別精度,這樣每個(gè)單品的歷史至多有24個(gè)��,數(shù)據(jù)量最多392字節(jié)�����,1000萬單品的信息總量將變?yōu)?.6G�����,系統(tǒng)總的存儲(chǔ)量不超過8G����,這是可以接受的。如果考慮用int類型代替long類型存儲(chǔ)時(shí)間(小時(shí)數(shù))����,則存儲(chǔ)量可以進(jìn)一步降低到不足6G�。這樣新的計(jì)算過程變?yōu)椋?/span>
x) 得到當(dāng)前時(shí)刻精確到小時(shí)的部分ct;
y) 如果本地沒有藍(lán)色單品的信息���,則從數(shù)據(jù)庫中讀取藍(lán)色單品信息�����;否則直接使用本地緩存的信息�。假設(shè)歷史是[(t1, a1)���, (t2, a2)����, …����, (tn, an)],累計(jì)量是A;
z) 累計(jì)量遞增����,即從A修改為A+1
aa) 如果ct=tn,則更新歷史為[(t1, a1)�, (t2, a2), …�����, (tn, an+1)],否則更新為[(t1, a1)����, (t2, a2)�����, …�����, (tn, an)�, (ct,1)];最后刪除小時(shí)數(shù)小于ct-24的列表元素,刪除的同時(shí)從累計(jì)量中減去對(duì)應(yīng)時(shí)刻的瀏覽量��;
ab) 將新的瀏覽量輸出至數(shù)據(jù)庫��;如果滿足一定的條件�����,則將歷史輸出至數(shù)據(jù)庫��。
在這種方案下,數(shù)據(jù)庫中存儲(chǔ)的并不是過去24小時(shí)內(nèi)的瀏覽量��,而是過去23小時(shí)多一點(diǎn)內(nèi)的�。例如在1月2日12:15時(shí)數(shù)據(jù)庫中的瀏覽量實(shí)際上是1月1日13:00到1月2日12:15的瀏覽量!
這種降低數(shù)據(jù)精度的方法我們可以稱之為模糊化��,它是用資源換效率的一種方法��。在對(duì)數(shù)據(jù)精確性不是特別敏感的領(lǐng)域�����,這種方法可以大大降低系統(tǒng)資源使用量���、提高系統(tǒng)的處理效率��。利用模糊化的實(shí)時(shí)算法快速得到近似結(jié)果��,而后用離線算法慢慢修正結(jié)果的精確度���,是百分點(diǎn)在大數(shù)據(jù)處理中經(jīng)常使用的招數(shù)。
ac) 局部精化
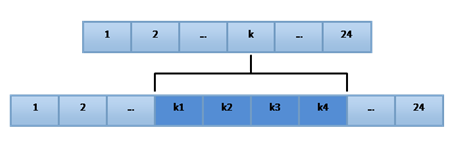
圖 6局部精華示意圖
有時(shí)候��,模糊化會(huì)掩蓋掉一些重要的細(xì)節(jié)信息�����,達(dá)不到業(yè)務(wù)需求的要求。例如�����,電商有很多的秒殺活動(dòng)�,此時(shí)必須及時(shí)監(jiān)測單品瀏覽量,如果我們還按小時(shí)維度進(jìn)行計(jì)算����,那顯然不能滿足要求�����。這種情況下我們就必須對(duì)局部數(shù)據(jù)進(jìn)行細(xì)化�,它是模糊化的逆操作,我們稱之為局部精化�����。如圖 6所示��,第k小時(shí)的數(shù)據(jù)是很敏感的���,我們希望它的數(shù)據(jù)能更實(shí)時(shí)一些���,那我們可以將第k小時(shí)的數(shù)據(jù)切分的更細(xì)�����,對(duì)它做10分鐘����、分鐘甚至秒級(jí)別的計(jì)算�,而其他時(shí)間段仍舊采用小時(shí)精度。
這種方案會(huì)增加系統(tǒng)的設(shè)計(jì)和開發(fā)難度���,而且必須有靈活的配置才能滿足多變的業(yè)務(wù)需求���。
ad) 數(shù)據(jù)建模
除了局部細(xì)化,還有一種方法可以提高數(shù)據(jù)的精確度���,這就是數(shù)據(jù)建模����。在方案四中我們提到在小時(shí)精度下,實(shí)際上只能得到23小時(shí)多一點(diǎn)之前的瀏覽量���,有一部分?jǐn)?shù)據(jù)丟失了沒有用到��。實(shí)際上我們可以將丟棄掉的數(shù)據(jù)利用起來得到更好的結(jié)果�����。最簡單思路是假設(shè)同一小時(shí)內(nèi)單品的瀏覽量是線性增加的�,那么我們顯然可以利用相鄰兩個(gè)小時(shí)的瀏覽歷史推算出任意時(shí)刻的瀏覽量���?����;氐椒桨杆闹械睦樱?月2日12:15的實(shí)時(shí)瀏覽量可以通過下面的公式計(jì)算得出:
[a0 + (a1-a0)×(60-15)/60] + a1 + … + a24
其中a0代表1月1日12:00到13:00之間的瀏覽量���,依次類推��,a24代表1月2日12:00到12:15之間的瀏覽量�����。公式中的a0 + (a1-a0)×(60-15)/60 估計(jì)了1月1日12:15-13:00之間的瀏覽量���,這樣就得出了從1月1日12:15到1月2日12:15之間24小時(shí)內(nèi)的瀏覽量����。
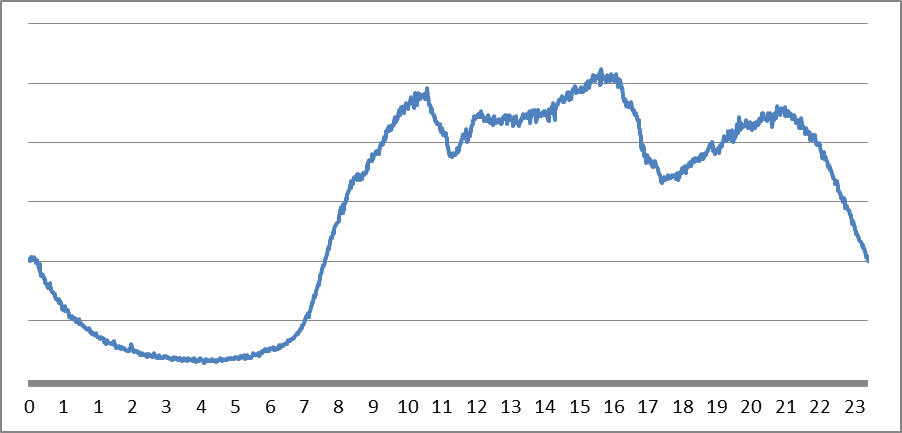
圖 7某單品的全天瀏覽分布
我們還可以利用更復(fù)雜的瀏覽量分布模型得出精度更高的估計(jì)����,圖 7給出了某單品一天的瀏覽分布曲線,這個(gè)分布適用于絕大多數(shù)的商品以及絕大多數(shù)的時(shí)間�����。因此����,我們完全可以利用這個(gè)分布來更精確的估計(jì)每個(gè)單品的瀏覽量,利用這個(gè)模型我們甚至不需要記錄瀏覽歷史���,只需要知道當(dāng)天0:00到當(dāng)前的瀏覽總量就可以計(jì)算出前24小時(shí)內(nèi)的瀏覽量�,甚至預(yù)測接下來的瀏覽量情況�!
當(dāng)然,模型也不是萬能的����,模型本身的建立和更新也是有代價(jià)的����,如果建模方法不恰當(dāng)或者模型更新不及時(shí)�����,很有可能得出的結(jié)果會(huì)很差�����。
ae) 小結(jié)
本文首先介紹了百分點(diǎn)公司大數(shù)據(jù)平臺(tái)的基本原理����,并詳細(xì)說明了其中與實(shí)時(shí)計(jì)算相關(guān)部分,實(shí)時(shí)計(jì)算框架和數(shù)據(jù)查詢框架�����,的系統(tǒng)架構(gòu)�����、處理流程和應(yīng)用���。而后�����,我們以海量數(shù)據(jù)計(jì)數(shù)問題為例�����,深入淺出的介紹了在百分點(diǎn)公司在實(shí)時(shí)計(jì)算算法中常用的方法和技巧����,以及它們適用的場景和可能帶來的問題���。這些方法和技巧具有普遍性和通用性���,被廣泛應(yīng)用于百分點(diǎn)個(gè)性化推薦引擎的各個(gè)模塊,包括用戶意圖預(yù)測�����、用戶畫像���、個(gè)性化推薦評(píng)分��、商品分類等等�。如果能在實(shí)際業(yè)務(wù)中靈活運(yùn)用這些方法和技巧,則能夠大大提高實(shí)時(shí)計(jì)算的數(shù)據(jù)規(guī)模和處理效率�����,幫助業(yè)務(wù)快速發(fā)展�。希望本文的介紹能夠幫助讀者更好的理解大數(shù)據(jù)實(shí)時(shí)計(jì)算的方方面面。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試���,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情����;
? 想學(xué)習(xí)CDA考試教材�����,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫��,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量�����,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營許可證編號(hào):京B2-20210330