大數(shù)據(jù)時代的數(shù)據(jù)挖掘:從應用的角度看大數(shù)據(jù)挖掘(上)
1 對大數(shù)據(jù)的理解和認識
大數(shù)據(jù)(big data)一詞經(jīng)常被用以描述和指代信息爆炸時代產(chǎn)生的海量信息。研究大數(shù)據(jù)的意義在于發(fā)現(xiàn)和理解信息內(nèi)容及信息與信息之間的聯(lián)系��。研究大數(shù)據(jù)首先要理清和了解大數(shù)據(jù)的特點及基本概念��,進而理解和認識大數(shù)據(jù)��。
1.1 大數(shù)據(jù)的特點“4V+4V”
從數(shù)據(jù)的表現(xiàn)形式看���,業(yè)界普遍認為大數(shù)據(jù)具有如下的“4V”特點[1]���。
● volume(大量):數(shù)據(jù)體量巨大,從TB級別躍升到PB級別��。
● variety(多樣):數(shù)據(jù)類型繁多����,如網(wǎng)絡日志、視頻�、圖片、地理位置信息等��。
● velocity(高速):處理速度快����,實時分析�,這也是和傳統(tǒng)的數(shù)據(jù)挖掘技術的本質(zhì)上的不同�����。
● value(價值):價值密度低�,蘊含有效價值高,合理利用低密度價值的數(shù)據(jù)并對其進行正確�����、準確的分析�,將會帶來巨大的商業(yè)和社會價值。
上述“4V”特點描述了大數(shù)據(jù)與以往部分抽樣的“小數(shù)據(jù)”的主要區(qū)別�����。然而����,實踐是大數(shù)據(jù)的最終價值體現(xiàn)的唯一途徑�����。從實際應用和大數(shù)據(jù)處理的復雜性看,大數(shù)據(jù)還具有如下新的“4V”特點����。
● variable(變化性):在不同的場景����、不同的研究目標下數(shù)據(jù)的結構和意義可能會發(fā)生變化,因此���,在實際研究中要考慮具體的上下文場景�����。
● veracity(真實性):獲取真實�����、可靠的數(shù)據(jù)是保證分析結果準確���、有效的前提。只有真實而準確的數(shù)據(jù)才能獲取真正有意義的結果����。
● volatility(波動性):由于數(shù)據(jù)本身含有噪音及分析流程的不規(guī)范性���,導致采用不同的算法或不同分析過程與手段會得到不穩(wěn)定的分析結果����。
● visualization(可視化):在大數(shù)據(jù)環(huán)境下��,通過數(shù)據(jù)可視化可以更加直觀地闡釋數(shù)據(jù)的意義���,幫助理解數(shù)據(jù),解釋結果�。
1.2 對大數(shù)據(jù)的理解
國內(nèi)外不同的專家和學者對大數(shù)據(jù)有不同的理解,中國科學院計算技術研究所李國杰院士認為:大數(shù)據(jù)就是“海量數(shù)據(jù)” 加“復雜數(shù)據(jù)類型”[2]����。維基百科對大數(shù)據(jù)的定義是:“大數(shù)據(jù)是由于規(guī)模����、復雜性����、實時性而導致的使之無法在一定時間內(nèi)用常規(guī)軟件工具對其進行獲取�����、存貯���、搜索、分享����、分析�����、可視化的數(shù)據(jù)集合”。Gartner咨詢公司給出的定義是:“大數(shù)據(jù)是需要新處理模式才能具有更強的決策力���、洞察發(fā)現(xiàn)力和流程優(yōu)化能力的海量�����、高增長率和多樣化的信息資產(chǎn)”�����。而互聯(lián)網(wǎng)數(shù)據(jù)中心將大數(shù)據(jù)定義為:“為更經(jīng)濟地從高頻率���、大容量����、不同結構和類型的數(shù)據(jù)中獲取價值而設計的新一代架構和技術”����。
結合上述大數(shù)據(jù)的“8V”特征����,筆者認為大數(shù)據(jù)的核心和本質(zhì)是應用、算法����、數(shù)據(jù)和平臺4個要素的有機結合���,如圖1所示�。大數(shù)據(jù)是應用驅(qū)動的�����,大數(shù)據(jù)來源于實踐�,海量數(shù)據(jù)產(chǎn)生于實際應用中��。
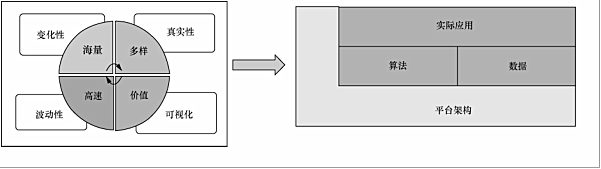
圖1 大數(shù)據(jù)架構
數(shù)據(jù)挖掘源于實踐中的實際應用需求�,用具體的應用數(shù)據(jù)作為驅(qū)動�����,以算法��、工具和平臺作為支撐���,最終將發(fā)現(xiàn)的知識和信息用到實踐中去�����,從而提供量化、合理���、可行����、能夠產(chǎn)生巨大價值的信息���。另外���,挖掘大數(shù)據(jù)所蘊含的有用信息�,需要設計和開發(fā)相應的數(shù)據(jù)挖掘和機器學習算法��。算法的設計和開發(fā)要以具體的應用數(shù)據(jù)為驅(qū)動,同時也要在實際問題中得到應用和驗證����,而算法的實現(xiàn)與應用需要高效的處理平臺。高效的處理平臺需要有效地分析海量的數(shù)據(jù)及對多源數(shù)據(jù)進行集成�, 同時有力支持數(shù)據(jù)挖掘算法以及數(shù)據(jù)可視化的執(zhí)行,并對數(shù)據(jù)分析的流程進行規(guī)范����。總而言之����,這個應用�、算法�����、數(shù)據(jù)和平臺相結合的思想是對上述大數(shù)據(jù)的理解和認識的一個綜合與凝練��,體現(xiàn)了大數(shù)據(jù)的本質(zhì)和核心�����。建立在此架構上的大數(shù)據(jù)挖掘�����,能夠有效處理大數(shù)據(jù)的復雜特征���,挖掘大數(shù)據(jù)的價值�����。
本文在此框架下�����,從應用的角度探討了大數(shù)據(jù)時代的數(shù)據(jù)挖掘的機遇與挑戰(zhàn)�, 介紹了研究團隊開發(fā)的大數(shù)據(jù)挖掘平臺FIU-Miner以及成功應用該平臺實現(xiàn)的高端制造業(yè)數(shù)據(jù)挖掘���、空間數(shù)據(jù)挖掘和商務智能3個大型���、復雜數(shù)據(jù)挖掘案例���。
2 大數(shù)據(jù)時代的數(shù)據(jù)挖掘
2.1 數(shù)據(jù)挖掘
在大數(shù)據(jù)時代,數(shù)據(jù)的產(chǎn)生和收集是基礎����,數(shù)據(jù)挖掘是關鍵。數(shù)據(jù)挖掘是大數(shù)據(jù)中最關鍵也最有價值的工作���。通常��,數(shù)據(jù)挖掘或知識發(fā)現(xiàn)泛指從大量數(shù)據(jù)中挖掘出隱含的、先前未知但潛在的有用信息和模式的一個工程化和系統(tǒng)化的過程����。數(shù)據(jù)挖據(jù)可以用以下4個特性概括[3]。
(1)應用性:數(shù)據(jù)挖掘是理論算法和應用實踐的完美結合���。數(shù)據(jù)挖掘源于實際生產(chǎn)生活中應用的需求,挖掘的數(shù)據(jù)來自于具體應用,同時通過數(shù)據(jù)挖掘發(fā)現(xiàn)的知識又要運用到實踐中去����,輔助實際決策�。所以����,數(shù)據(jù)挖掘來自于應用實踐�,同時也服務于應用實踐����。
(2)工程性:數(shù)據(jù)挖掘是一個由多個步驟組成的工程化過程。數(shù)據(jù)挖掘的應用特性決定了數(shù)據(jù)挖掘不僅僅是算法分析和應用��,而是一個包含數(shù)據(jù)準備和管理、數(shù)據(jù)預處理和轉(zhuǎn)換����、挖掘算法開發(fā)和應用�����、結果展示和驗證以及知識積累和使用的完整過程。而且在實際應用中���,典型的數(shù)據(jù)挖掘過程還是一個交互和循環(huán)的過程��。
(3)集合性:數(shù)據(jù)挖掘是多種功能的集合。常用的數(shù)據(jù)挖掘功能包括數(shù)據(jù)探索分析�����、關聯(lián)規(guī)則挖掘�����、時間序列模式挖掘��、分類預測��、聚類分析、異常檢測�、數(shù)據(jù)可視化和鏈接分析等。一個具體的應用案例往往涉及多個不同的功能。不同的功能通常有不同的理論和技術基礎����,而且每一個功能都有不同的算法支撐����。
(4)交叉性:數(shù)據(jù)挖掘是一個交叉學科,它利用了來自統(tǒng)計分析����、模式識別、機器學習���、人工智能���、信息檢索�����、數(shù)據(jù)庫等諸多不同領域的研究成果和學術思想�����。同時,一些其他領域如隨機算法���、信息論�����、可視化����、分布式計算和最優(yōu)化也對數(shù)據(jù)挖掘的發(fā)展起到重要的作用��。數(shù)據(jù)挖掘與這些相關領域的區(qū)別可以由前面提到的數(shù)據(jù)挖掘的3個特性來總結,最重要的是它更側重于應用�����。
具體而言����,實際應用的需求是數(shù)據(jù)挖掘領域很多方法提出和發(fā)展的根源���。從最開始的顧客交易數(shù)據(jù)分析(market basket analysis)����、多媒體數(shù)據(jù)挖掘(multimedia data mining)�、隱私保護數(shù)據(jù)挖掘(privacy-preserving data mining)到文本數(shù)據(jù)挖掘(text mining) 和 Web 挖掘(Web mining)��,再到社交媒體挖掘(social media mining)都是由應用推動的�����。工程性和集合性決定了數(shù)據(jù)挖掘研究內(nèi)容和方向的廣泛性�����。其中�����,工程性使得整個研究過程里的不同步驟都屬于數(shù)據(jù)挖掘的研究范疇。而集合性使得數(shù)據(jù)挖掘有多種不同的功能�, 而如何將多種功能聯(lián)系和結合起來�,從一定程度上影響了數(shù)據(jù)挖掘研究方法的發(fā)展�����。比如���,2 0 世紀9 0 年代中期����,數(shù)據(jù)挖掘的研究主要集中在關聯(lián)規(guī)則和時間序列模式的挖掘。到20世紀9 0年代末���,研究人員開始研究基于關聯(lián)規(guī)則和時間序列模式的分類算法(如classification based on association),將兩種不同的數(shù)據(jù)挖掘功能有機地結合起來���。21世紀初,一個研究的熱點是半監(jiān)督學習(semi-supervised learning)和半監(jiān)督聚類(semi-supervised clustering)�����,也是將分類和聚類這兩種功能有機結合起來。近年來的一些其他研究方向如子空間聚類(subspace clustering)(特征抽取和聚類的結合)和圖分類(graph classification) (圖挖掘和分類的結合)也是將多種功能聯(lián)系和結合在一起���。最后���,交叉性導致了研究思路和方法設計的多樣化。
2.2 從數(shù)據(jù)挖掘應用的角度看大數(shù)據(jù)
大數(shù)據(jù)是現(xiàn)象�����,核心是要挖掘數(shù)據(jù)的價值��。結合數(shù)據(jù)挖掘的各種特性�,尤其是其應用性,從應用業(yè)務的角度對大數(shù)據(jù)提出如下兩點的認識[3]���。
首先����,大數(shù)據(jù)是“一把手工程”�����。在一個企業(yè)里����,大數(shù)據(jù)通常涉及多個業(yè)務部門,業(yè)務邏輯復雜�。一方面,要對大數(shù)據(jù)進行收集和整合��,需要業(yè)務部門的配合和溝通以及業(yè)務人員的大力參與,這些需要企業(yè)決策人員的重視和認可�,提供必要的資源調(diào)配和支持。另一方面����,要對數(shù)據(jù)挖掘的結果進行驗證和運用,更離不開相關人員的決策����。數(shù)據(jù)挖掘的結果大多是相關關系����,而不是因果關系����,這些結果還可能有不確定性�。另外,有時候數(shù)據(jù)挖掘的結果與企業(yè)運作的常識不一致���,甚至相悖��。所以����,如何看待這些可能的不確定性和反常識的分析結論��,充分利用好數(shù)據(jù)挖掘結果�,必然離不開決策者的遠見卓識。
其次�����,大數(shù)據(jù)需要數(shù)據(jù)導入�����、整合和預處理���。當面對來自不同數(shù)據(jù)源的大量復雜數(shù)據(jù)時�����,具體業(yè)務邏輯復雜與數(shù)據(jù)之間的關系瑣碎直接導致企業(yè)的業(yè)務流程和數(shù)據(jù)流程很難理解�。因此,企業(yè)在實施大數(shù)據(jù)時可能并不清楚要挖掘和發(fā)現(xiàn)什么���,對數(shù)據(jù)挖掘到底能幫助企業(yè)做什么并沒有直觀和清楚的認識��。所以����,很多時候都不可能先把數(shù)據(jù)事先規(guī)劃好和準備好�,這樣在具體的數(shù)據(jù)挖掘中�,就需要在數(shù)據(jù)的導入、整合和預處理上有很大的靈活性��,只有通過業(yè)務人員和數(shù)據(jù)挖掘工程師的配合�,不斷嘗試,才能有效地將企業(yè)的業(yè)務需求與數(shù)據(jù)挖掘的功能聯(lián)系起來�。
2.3 大數(shù)據(jù)時代應用數(shù)據(jù)挖掘的挑戰(zhàn)
大數(shù)據(jù)時代的來臨使得數(shù)據(jù)的規(guī)模和復雜性都出現(xiàn)爆炸式的增長,促使不同應用領域的數(shù)據(jù)分析人員利用數(shù)據(jù)挖掘技術對數(shù)據(jù)進行分析�����。在應用領域中,如醫(yī)療保健�����、高端制造��、金融等�,一個典型的數(shù)據(jù)挖掘任務往往需要復雜的子任務配置,整合多種不同類型的挖掘算法以及在分布式計算環(huán)境中高效運行��。因此��,在大數(shù)據(jù)時代進行數(shù)據(jù)挖掘應用的一個當務之急是要開發(fā)和建立計算平臺和工具�,支持應用領域的數(shù)據(jù)分析人員能夠有效地執(zhí)行數(shù)據(jù)分析任務。
現(xiàn)有的數(shù)據(jù)挖掘工具(如Weka[4]���、SPSS和SQL Server等)提供了友好的界面��,方便用戶進行分析���。然而,這些工具并不適合進行大規(guī)模的數(shù)據(jù)分析。同時使用這些工具時����,用戶很難添加新的算法程序。流行的數(shù)據(jù)挖掘算法庫(如Mahout[5]��、MLC++和MILK)提供了大量的數(shù)據(jù)挖掘算法����。但是,這些算法庫需要有高級編程技能才能在一個具體的數(shù)據(jù)挖掘任務中進行任務配置和算法集成��。最近出現(xiàn)的一些集成的數(shù)據(jù)挖掘產(chǎn)品(如Radoop[6]和BC-PDM[7])通過提供友好的用戶界面來快速配置數(shù)據(jù)挖掘任務�。然而,這些產(chǎn)品是基于Hadoop框架的�,對非Hadoop算法程序的支持非常有限。此外�,這些產(chǎn)品并沒有明確地解決在多用戶和多任務情況下的資源分配問題。
為了解決現(xiàn)有工具和產(chǎn)品在大數(shù)據(jù)挖掘中的局限性���,開發(fā)了一個新的平臺——FIU-Miner(a fast, integrated, and user-friendly system for data mining in distributed environment[8]),是一個用戶友好并支持在分布式環(huán)境中進行高效率計算和快速集成的數(shù)據(jù)挖掘系統(tǒng)��,該平臺支持數(shù)據(jù)分析人員快速��、有效地進行數(shù)據(jù)挖掘任務��。
3 大數(shù)據(jù)挖掘系統(tǒng)FIU-Miner的研究設計
3.1 FIU-Miner平臺介紹
與現(xiàn)有數(shù)據(jù)挖掘平臺相比,F(xiàn)IU-Miner提供了一組新的功能���,能夠幫助數(shù)據(jù)分析人員方便并有效地開展各項復雜的數(shù)據(jù)挖掘任務��。
具體而言��,F(xiàn)IU-Miner 具有以下突出的優(yōu)點��。
(1)用戶友好�����、人性化�、快速的數(shù)據(jù)挖掘任務配置:基于“軟件即服務”這一模式��,F(xiàn)IU-Miner隱藏了與數(shù)據(jù)分析任務無關的低端細節(jié)����。通過FIU-Miner提供的人性化用戶界面,用戶可以通過將現(xiàn)有算法直接組裝成工作流�����,輕松完成一個復雜數(shù)據(jù)挖掘問題的任務配置,而不需要編寫任何代碼�。
(2)靈活的多語言程序集成:FIU-Miner允許用戶將目前最先進的數(shù)據(jù)挖掘算法直接導入系統(tǒng)算法庫中,以此對分析工具集合進行擴充和管理��。同時����,由于FIU-Miner 能夠正確地將任務分配到有合適運行環(huán)境的計算節(jié)點上,所以對這些導入的算法沒有實現(xiàn)語言的限制��。
(3)異構環(huán)境中有效的資源管理: FIU-Miner支持在異構的計算環(huán)境中(包括圖形工作站��、單個計算機和服務器等)運行數(shù)據(jù)挖掘任務��。FIU-Miner綜合考慮各種因素(包括算法實現(xiàn)�、服務器負載平衡和數(shù)據(jù)位置)來優(yōu)化計算資源的利用率。
3.2 FIU-Miner系統(tǒng)架構
FIU-Miner的系統(tǒng)架構如圖2所示�����。該系統(tǒng)分為4層:user interface(用戶接口層)��、task and system management(任務與系統(tǒng)管理層)�����、abstracted resources (抽象資源層)和heterogeneous physical resource(異構物理資源層)���。這種分層架構充分考慮了海量數(shù)據(jù)的分布式存儲����、不同數(shù)據(jù)挖掘算法的集成�����、多種分析任務的配置以及系統(tǒng)和用戶的交互功能�。
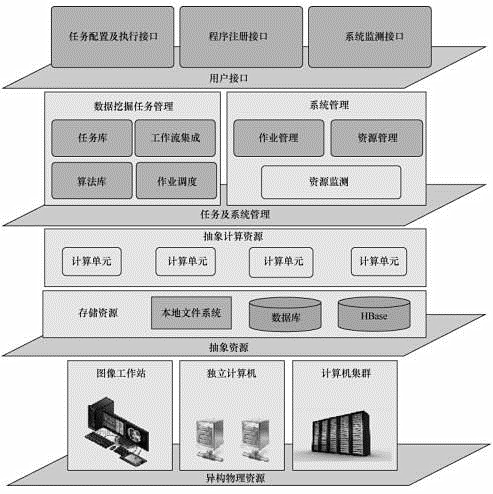
圖2 FIU-Miner 系統(tǒng)架構
3.2.1 用戶接口層
為了最大限度地提高系統(tǒng)的兼容性, 用戶接口層是完全用HTML 5開發(fā)的Web 應用程序�����。如圖3所示����,用戶接口層有如下3個功能模塊。
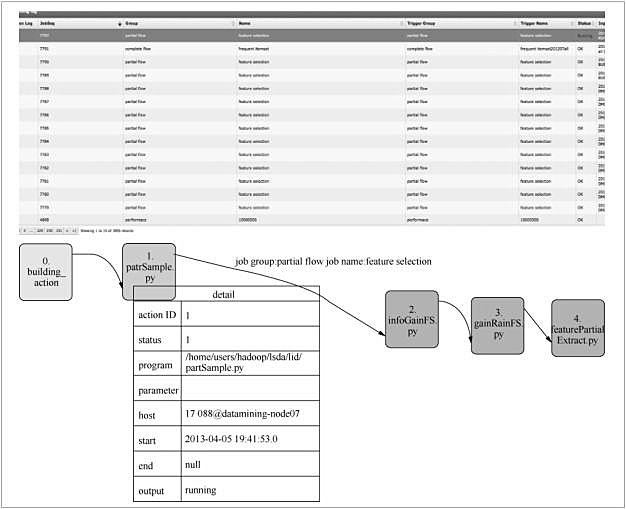
(a)任務配置和執(zhí)行
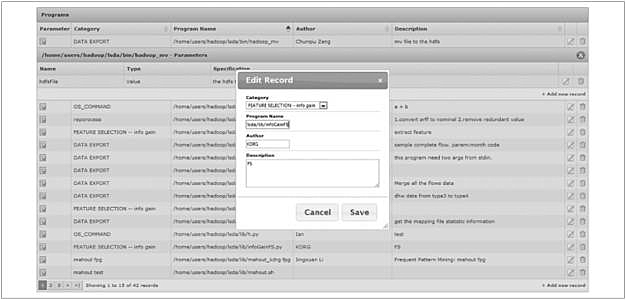
(b)程序注冊模塊

(c)系統(tǒng)監(jiān)控模塊
圖 3 用戶接口層功能模塊
(1)任務配置和執(zhí)行(task configuration and execution)
該模塊支持面向工作流的數(shù)據(jù)挖掘任務配置��。一個數(shù)據(jù)挖掘任務的工作流可以被表示為一個有向圖�����,其中圖的節(jié)點表示特定的算法,圖的邊表示算法中的數(shù)據(jù)相關性����。在FIU-Miner 中,一個工作流程可通過圖形用戶界面來快速配置����,而不需要編程。此外��,用戶可以設置數(shù)據(jù)挖掘任務的執(zhí)行計劃���,包括程序的定時�、循環(huán)�、順序等執(zhí)行方式。
(2)程序注冊(program registration)
該模塊可以讓用戶輕松地導入外部數(shù)據(jù)挖掘算法�����,充實FIU-Miner的算法庫�。如果要導入外部程序,用戶需要上傳可執(zhí)行文件���,提供詳細的描述信息�����,包括程序的功能描述�、需要的運行環(huán)境�����、程序和相關數(shù)據(jù)以及參數(shù)規(guī)范��。導入的程序可以使用任何語言編寫�,只要后端服務器能支持它需要的運行環(huán)境。FIU-Miner目前支持Java(包括Hadoop的環(huán)境)�、Shell、Python和C/C+ +等語言編寫的程序��,因此幾乎所有實現(xiàn)的主流數(shù)據(jù)挖掘算法�����,如基于Weka�����、Mahout��、MILK等數(shù)據(jù)挖掘和機器學習算法庫的程序,都可以很容易地導入FIU-Miner��。用戶還可以將自己實現(xiàn)的算法導入系統(tǒng)中�。
(3)系統(tǒng)監(jiān)控(system monitoring)
該模塊實時監(jiān)測FIU-Miner的資源利用率,并且動態(tài)跟蹤系統(tǒng)中提交任務的運行狀態(tài)��。注意該模塊只顯示了抽象的資源(邏輯存儲和計算資源包括數(shù)據(jù)庫����、文件系統(tǒng)、計算單元等)���,使底層物理資源對用戶透明���。
3.2.2 任務及系統(tǒng)管理層
任務及系統(tǒng)管理層包含了兩個主要功能模塊:任務管理和系統(tǒng)管理。
(1)任務管理
FIU-Miner允許用戶動態(tài)配置數(shù)據(jù)挖掘任務��,以滿足他們的分析需求�。用戶可以選擇在算法庫(algorithm library)中注冊的算法作為基本模塊來構造工作流。工作流集成器(workflow integrator)負責工作流的任務集成和驗證�,同時發(fā)現(xiàn)和報告無效的流程。一旦新的數(shù)據(jù)挖掘任務集成和配置完成后�����,它將被自動添加到任務庫(task library),可以隨時被調(diào)度運行�。作業(yè)調(diào)度器(job scheduler)負責分配計算資源及優(yōu)化運行時間。FIU-Miner里的調(diào)度比較復雜����。一方面,F(xiàn)IU-Miner支持不同編程語言實現(xiàn)的程序在異構的計算環(huán)境中運行�。一個任務里的不同程序可能會有不同的運行環(huán)境要求�。所以,簡單地把任務分配到空閑的計算單元不一定可行����。另一方面,將一個作業(yè)分成不同的步驟����,讓每個步驟在不同的計算單元上運行,可能會增加I/O成本�����。如果再考慮多用戶��、多任務的情況�����,F(xiàn)IU-Miner里的調(diào)度就會變得更加困難和復雜。為了解決上面的難題����,在實現(xiàn)FIU-Miner的調(diào)度時,綜合考慮了如下因素:給定任務每一步的運行環(huán)境要求���; 每個計算單元支持的運行環(huán)境��;每個計算結點的當前運行狀態(tài)����;輸入數(shù)據(jù)的大小��。
(2)系統(tǒng)管理
作業(yè)管理器(job manager)跟蹤執(zhí)行作業(yè)的運行狀態(tài)��。用戶會收到作業(yè)的實時狀態(tài)�。除了作業(yè)監(jiān)視,F(xiàn)IU-Miner還會跟蹤計算單元以及相關計算資源的狀態(tài)����。資源監(jiān)視器(resource monitor)監(jiān)視計算單元并提供作業(yè)調(diào)度程序的運行狀態(tài), 以幫助調(diào)度決策。資源管理器(resource manager)管理所有可用的計算單元�����。FIU-Miner的一個獨特的優(yōu)點是�����,它不需要人工登記可用物理資源�����。一旦計算單元部署在物理服務器上���,它會將服務器的信息發(fā)送給資源管理器,自動將服務器在FIU-Miner里注冊����。
3.2.3 抽象資源層
抽象資源層包括存儲和計算資源�����。存儲資源建立在物理設備的基礎上�����,包括傳統(tǒng)數(shù)據(jù)庫�����、本地文件系統(tǒng)��、分布式文件系統(tǒng)(比如HDFS)等�。計算單元是邏輯上的計算資源。平臺的計算能力依賴計算單元的數(shù)量�。通過擴展配置計算單元的數(shù)量,能有效地支撐上層的數(shù)據(jù)挖掘任務���。
在FIU-Miner中�����,物理服務器的計算能力是由計算單元的數(shù)量和安排的數(shù)據(jù)挖掘任務來量化的����。這種機制是一個系統(tǒng)虛擬化的簡化版本�����,能夠最大限度地提高計算資源的利用率�。為了有效地管理計算資源,每個計算單元都包含詳細規(guī)范的配置文件(信息包括計算能力、支持的運行環(huán)境���、運行狀態(tài)等)�。一臺物理服務器的存儲(包括可用的數(shù)據(jù)庫��、HDFS和本地文件系統(tǒng))由該服務器上布置的計算單元共享�����。
3.2.4 異構物理資源層
異構物理資源層亦稱物理資源層�,主要包括底層的物理設備。這些物理設備能有效地支撐數(shù)據(jù)存儲和擴展���。
3.3 FIU-Miner系統(tǒng)亮點評述
FIU-Miner 建立于分布式異構環(huán)境之上����,大大減少了不同物理環(huán)境給構建數(shù)據(jù)分析任務帶來的復雜度����,充分利用分布式計算的能力提升數(shù)據(jù)分析的效率�����。另外,F(xiàn)IU-Miner的計算資源是可動態(tài)增減的��,使其具備根據(jù)具體分析任務數(shù)量進行在線調(diào)整計算物理資源的能力�����。最后��,友好的用戶接口為基于FIU-Miner構建不同的大數(shù)據(jù)挖掘應用提供了極大的便捷�。
4 FIU-Miner應用實例一:高端制造業(yè)
4.1 高端制造業(yè)大數(shù)據(jù)挖掘任務
制造業(yè)是指大規(guī)模地把原材料加工成成品的工業(yè)生產(chǎn)過程。高端制造業(yè)是指制造業(yè)中新出現(xiàn)的具有高技術含量��、高附加值�����、強競爭力的產(chǎn)業(yè)��。典型的高端制造業(yè)[9] 包括電子半導體生產(chǎn)�、精密儀器制造、生物制藥等��。這些制造領域往往涉及嚴密的工程設計���、復雜的裝配生產(chǎn)線��、大量的控制加工設備與工藝參數(shù)����、精確的過程控制和材料的嚴格規(guī)范。產(chǎn)量和品質(zhì)極大地依賴流程管控和優(yōu)化決策�。因此,制造企業(yè)不遺余力地采用各種措施優(yōu)化生產(chǎn)流程��,調(diào)優(yōu)控制參數(shù)��,提高產(chǎn)品品質(zhì)和產(chǎn)量����,從而提高企業(yè)的競爭力。
隨著工藝���、裝備和信息技術的不斷發(fā)展��,現(xiàn)代制造業(yè)(特別是高端制造業(yè))產(chǎn)生和積累了大量生產(chǎn)過程的歷史數(shù)據(jù)���。這些數(shù)據(jù)中蘊含對生產(chǎn)和管理有很高價值的知識和信息��。高端制造企業(yè)利用這些技術能夠更好地收集和管理生產(chǎn)流程數(shù)據(jù)���,也使得企業(yè)累積的相關數(shù)據(jù)在日益增多的同時�,也變得更加豐富、完備�、準確。
這些采集的數(shù)據(jù)來源于實際生產(chǎn)����,并與生產(chǎn)設計、機器設備���、原材料�����、環(huán)境條件����、生產(chǎn)流程等生產(chǎn)要素信息高度相關���。通常情況下�����,工程人員通過人工分析很難察覺到參數(shù)間的關聯(lián)模式和影響品質(zhì)的重要生產(chǎn)要素等信息�。然而,如何有效地利用這些數(shù)據(jù)優(yōu)化生產(chǎn)過程���,提升生產(chǎn)效率����,成為了企業(yè)關注的焦點�����。因此�����,制造企業(yè)需要一種高效���、可靠的分析方法及工具��,把隱藏在海量數(shù)據(jù)中有用的�、深層次的知識和信息挖掘出來����,以提升高端制造業(yè)在控制、優(yōu)化���、調(diào)度���、管理等各個層面分析和解決問題的能力。幸運的是�����,利用數(shù)據(jù)挖掘可以對這些數(shù)據(jù)進行有效的分析并轉(zhuǎn)換成有價值的生產(chǎn)知識,從而能夠在實際應用中改進產(chǎn)品品質(zhì),提升產(chǎn)品性能和生產(chǎn)效率,最終達到提高企業(yè)行業(yè)競爭力的目的�。因此����,數(shù)據(jù)挖掘技術是解決制造業(yè)海量信息數(shù)據(jù)處理的關鍵技術之一�����。
4.2 高端制造業(yè)大數(shù)據(jù)挖掘挑戰(zhàn)
高端制造業(yè)中的數(shù)據(jù)挖掘面臨很多挑戰(zhàn)����,比如:如何有效分析大規(guī)模數(shù)據(jù)���、如何保證數(shù)據(jù)分析效率和分析結果的準確性��?在實際應用中����,從海量數(shù)據(jù)中依靠傳統(tǒng)信息系統(tǒng)進行查詢和報警或單純利用專家經(jīng)驗來分析和發(fā)現(xiàn)潛在有價值的信息已經(jīng)變得不太現(xiàn)實。因此�����,企業(yè)需要利用數(shù)據(jù)分析技術、工具或平臺,智能地從大量復雜的生產(chǎn)原始數(shù)據(jù)中發(fā)現(xiàn)新的模式和知識作為改善生產(chǎn)過程的決策依據(jù),系統(tǒng)性地提高生產(chǎn)效率。
4.3 具體案例
FIU-Miner已經(jīng)被成功地應用在四川虹歐顯示器件有限公司�,作為等離子屏制造過程的數(shù)據(jù)分析平臺[3,10]��。
4.3.1 等離子顯示器制造
等離子顯示器(plasma display panel,PDP)是一種利用氣體等離子效應放出紫外線,從而激發(fā)三原色發(fā)光體獨立發(fā)光��,達到顯示不同顏色和控制亮度的高端圖像顯示器����。它具有亮度高、色彩多、面積大�����、視角廣��、圖像清晰等眾多優(yōu)勢����,是大面積顯示需求(如家庭影院����、電子廣告墻)的首選顯示器。
四川虹歐顯示器件有限公司是國內(nèi)最大的等離子生產(chǎn)公司��,每天生產(chǎn)超過1萬張等離子顯示面板��,其生產(chǎn)線的一些指標包括[10]:20個大工序�、151個小工序;1 000多臺設備串聯(lián)��;工藝設備共計279臺��,設備種類達8 3 種��;2 225個物流單元�����,全長6 000 m�;產(chǎn)品制造時間約76 h�����;單臺產(chǎn)品涉及的過程設備參數(shù)超過1.17 萬個。
具體而言����,在生產(chǎn)實踐中,技術人員關注如何提高產(chǎn)品的良品率�。實現(xiàn)這個目標, 需要回答下面的一些問題:哪些是關鍵的工藝參數(shù)(它們對產(chǎn)品的良品率有顯著的影響)���、參數(shù)值的變動會怎樣影響產(chǎn)品的良品率�����、哪些是有效的可以確保高良品率的工藝參數(shù)配方等��。從PDP的數(shù)據(jù)特點來說�����,每天生產(chǎn)的數(shù)據(jù)存儲量是10 GB以上,每月有3~5億筆制造過程記錄����,在數(shù)量、維度和數(shù)據(jù)產(chǎn)生速度上具有海量大數(shù)據(jù)特征��。在生產(chǎn)工序復雜�、設備參數(shù)眾多����、數(shù)據(jù)量大的背景下�,人為分析PDP生產(chǎn)過程,以期達到提高生產(chǎn)質(zhì)量的效果幾乎是無法實現(xiàn)的��。因此���,迫切需要研究基于等離子顯示屏制造過程的自動化流程和產(chǎn)品優(yōu)化工具�����,從而提升制造過程參數(shù)管控能力和產(chǎn)品品質(zhì)����。
4.3.2 基于FIU-Miner 的解決方案
在過去的幾年里�,筆者的研究團隊一直與四川虹歐顯示器件有限公司的技術人員和工程師緊密合作,利用數(shù)據(jù)挖掘來提高等離子屏的生產(chǎn)良品率�����。在這個合作過程中�,確定了如下兩個主要的分析難點,并提出了相應的基于FIU-Miner 的解決方案���。
● 7×24 h的自動化生產(chǎn)方式和新數(shù)據(jù)采集工具的使用���,使得數(shù)據(jù)量急劇增長, 需要強大的數(shù)據(jù)分析能力來支撐��。
● 大量過程控制參數(shù)造成的數(shù)據(jù)高維特性對數(shù)據(jù)分析效率和分析結果的準確性提出了更高要求。生產(chǎn)數(shù)據(jù)分析是對生產(chǎn)工作流程的一個認知過程����。這個過程本身就是對數(shù)據(jù)進行探索、分析和理解的一個循序漸進的迭代過程�。因此,一個實用的系統(tǒng)應該提供一個集成的�����、高效率的分析平臺來支持這個過程��。
筆者的研究團隊在FIU-Miner的基礎上�,開發(fā)了離子屏制造過程數(shù)據(jù)挖掘系統(tǒng)(PDP-Miner)[10]來解決PDP數(shù)據(jù)分析的難題。PDP-Miner的架構如圖4所示����。具體而言,在FIU-Miner的基礎上增加了數(shù)據(jù)分析層��。
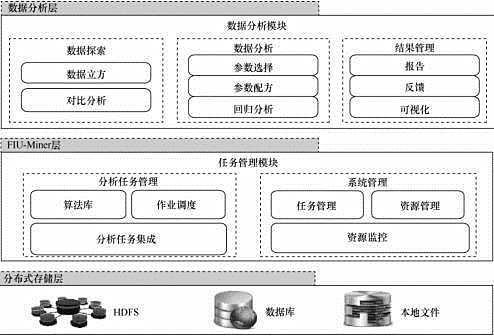
圖 4 PDP-Miner 的系統(tǒng)架構
數(shù)據(jù)分析層提供具體分析任務的用戶執(zhí)行接口����。以等離子屏數(shù)據(jù)挖掘系統(tǒng)為例, 數(shù)據(jù)分析任務主要包括數(shù)據(jù)立方�����、對比分析、回歸分析��、參數(shù)選擇����、參數(shù)配方�����、操作平臺����、結果展示和報告管理。
其中�����,數(shù)據(jù)立方使分析人員能夠?qū)?shù)據(jù)進行宏觀理解和快速預覽���。數(shù)據(jù)立方子系統(tǒng)可以通過OLAP技術建立數(shù)據(jù)立方來幫助分析人員大致掌握數(shù)據(jù)特性����。通過選擇維度和建立測度來對數(shù)據(jù)集進行分析。通過數(shù)據(jù)立方操作(下鉆���、上卷等)實現(xiàn)對數(shù)據(jù)的多粒度����、多角度的理解��。
對比分析子系統(tǒng)���,能快速發(fā)現(xiàn)敏感參數(shù)和驗證重要參數(shù)���,因此,在PDP生產(chǎn)系統(tǒng)中顯得特別重要��。通過比較參數(shù)在不同時期取值的統(tǒng)計特性����,有效發(fā)現(xiàn)異常參數(shù)值,從而定位敏感設備或數(shù)據(jù)集�����。
數(shù)據(jù)分析子系統(tǒng)主要負責集成數(shù)據(jù)挖掘算法���,提供業(yè)務操作接口�����。由于該系統(tǒng)面向非專業(yè)領域的操作人員���,并聚焦到具體的分析業(yè)務,因此數(shù)據(jù)挖掘算法被合理封裝到各個業(yè)務中�����,對操作人員透明?���,F(xiàn)在的挖掘算法主要支持回歸分析、參數(shù)選擇�、參數(shù)配方等任務。
分析報告系統(tǒng)基于業(yè)務分析結果產(chǎn)生分析報告��。這些分析報告可以直接給決策者提供決策依據(jù)����。同時報告系統(tǒng)也為領域?qū)<姨峁┦占答伒慕涌凇nI域?qū)<抑R的引入對優(yōu)化模型���、改進算法具有很大的指導意義��。
圖5給出了兩個具體PDP挖掘的工作流��。其中第一個工作流(workflow 1)先集成多種特征選擇的方法來選出影響PDP生產(chǎn)的重要工藝參數(shù)�����,然后利用回歸分析來建立這些參數(shù)與產(chǎn)品質(zhì)量的關系����。第二個工作流(workflow 2)是利用頻繁模式分析來挖掘重要工藝參數(shù)的關聯(lián)關系,從而產(chǎn)生可能的參數(shù)配方�����。圖6給出了工作流的配置界面����。
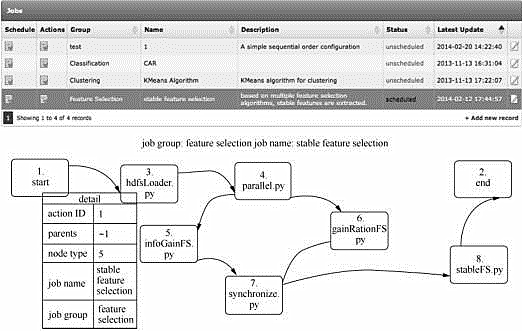
圖 5 PDP-Miner 工作流程
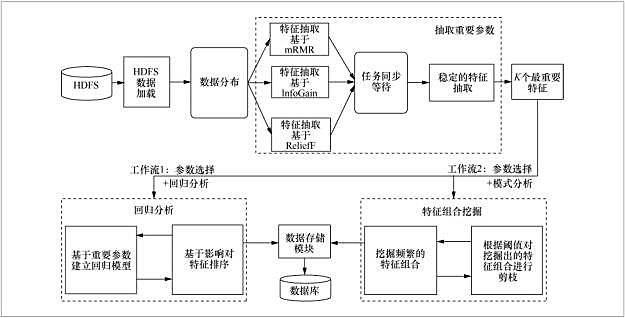
圖 6 PDP-Miner 工作流配置界面
使用等離子屏制造過程數(shù)據(jù)挖掘系統(tǒng)大大降低了對前臺使用人員的要求,可以使得操作人員能夠?qū)⒕劢沟娇焖侔l(fā)現(xiàn)問題和解決問題上�����。
通過技術人員將數(shù)據(jù)挖掘研究的結果和平臺進行有效應用����,提高了對制造過程中所出現(xiàn)問題的分析和解決的效率(見表1)�����,使PDP屏生產(chǎn)線的綜合良品率及生產(chǎn)效率得到了快速提升�。一方面���,在顯示器件制造業(yè)首次采用大數(shù)據(jù)挖據(jù)技術��,實現(xiàn)了由傳統(tǒng)離散型的試驗設計方法到數(shù)據(jù)挖掘模型來進行制造過程參數(shù)管控的動態(tài)在線分析處理方法,降低了制造過程品質(zhì)管控的試驗成本����。另一方面,通過數(shù)據(jù)挖掘平臺��,建立了等離子屏制造過程單工序/全工序的參數(shù)管控的主要數(shù)據(jù)挖掘分析模型�����,通過挖據(jù)結果的有效應用�����,促進了等離子顯示屏的制造良品率和生產(chǎn)效率的提升。最后����,利用平臺挖掘方便快捷地指導技術人員進行參數(shù)管控的常態(tài)化螺旋式提升。在成果應用的這些年里���, 促進了PDP良品率和產(chǎn)能的快速提升�,給公司帶來了巨大的生產(chǎn)經(jīng)濟效益����。圖7給出了PDP-Miner的實際應用的主界面,該系統(tǒng)的功能模塊包括數(shù)據(jù)探索(對比分析���、數(shù)據(jù)立方)���、數(shù)據(jù)分析(操作平臺、參數(shù)選擇�、回歸分析、判別分析)���、結果管理(可視化���、結果列表和反饋收集)��。需要特別指出的是�����,等離子顯示屏制造挖掘平臺可方便地移植于液晶面板��、OLED面板等其他平板顯示領域�,具備向整個平板行業(yè)推廣的基礎�����。
表 1 PDP-Miner 數(shù)據(jù)挖掘技術與傳統(tǒng)數(shù)據(jù)挖掘技術比較
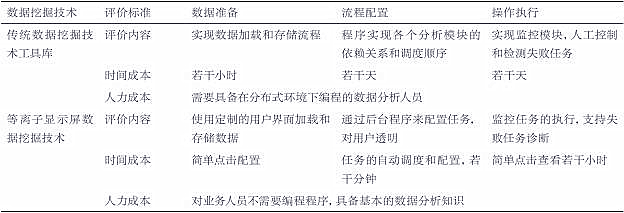
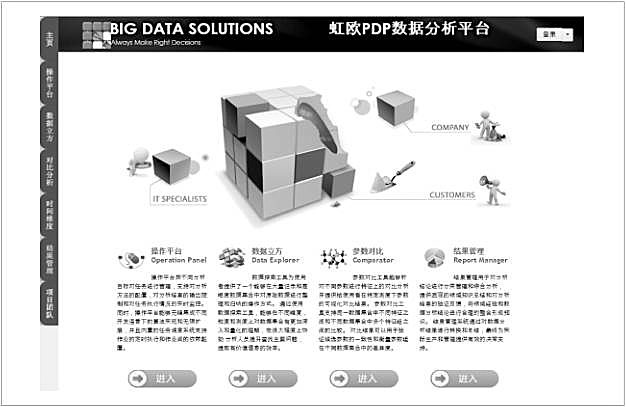
圖 7 PDP-Miner 實際應用的主界面
4.4 應用亮點評述
將FIU-Miner應用于高端制造業(yè)的實際案例��,在國際上率先將數(shù)據(jù)挖掘技術應用于顯示器件制造業(yè)���,為四川虹歐顯示器件有限公司構建了制造過程單工序/全工序數(shù)據(jù)挖掘 分析模型,開發(fā)了基于數(shù)據(jù)挖掘的PDP-Miner平臺����,有效提升了生產(chǎn)效率和產(chǎn)品質(zhì)量。該公司應用PDP-Miner平臺后�����,產(chǎn)品綜合良品率得到了很大提高,同時����,生產(chǎn)效率的提升也帶來了很大的經(jīng)濟效益。該研究獲得2013年“中國制造業(yè)IT 新興技術應用最佳實踐獎”��。
CDA數(shù)據(jù)分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情;
? 想學習CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量,點擊>>> “CDA含金量” 了解CDA考試詳情�����;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330