聚類算法之K均值
有時(shí)候,我們只有訓(xùn)練樣本的特征�����,而對(duì)其類型一無(wú)所知。這種情況�,我們只能讓算法嘗試在訓(xùn)練數(shù)據(jù)中尋找其內(nèi)部的結(jié)構(gòu),試圖將其類別挖掘出來(lái)�����。這種方式叫做無(wú)監(jiān)督學(xué)習(xí)�����。由于這種方式通常是將樣本中相似的樣本聚集在一起�,所以又叫聚類算法。本文��,中顥潤(rùn)將介紹一種最常用的聚類算法:K均值聚類算法(K-Means)��。
1���、K均值聚類
K-Means算法思想簡(jiǎn)單���,效果卻很好,是最有名的聚類算法�。聚類算法的步驟如下:
a:初始化K個(gè)樣本作為初始聚類中心;
b:計(jì)算每個(gè)樣本點(diǎn)到K個(gè)中心的距離,選擇最近的中心作為其分類�,直到所有樣本點(diǎn)分類完畢;
c:分別計(jì)算K個(gè)類中所有樣本的質(zhì)心�,作為新的中心點(diǎn),完成一輪迭代�����。
通常的迭代結(jié)束條件為新的質(zhì)心與之前的質(zhì)心偏移值小于一個(gè)給定閾值�����。
下面給一個(gè)簡(jiǎn)單的例子來(lái)加深理解�����。如下圖有4個(gè)樣本點(diǎn)�����,坐標(biāo)分別為A(-1,-1),B(1,-1),C(-1,1),D(1,1)?����,F(xiàn)在要將他們聚成2類�����,指定A���、B作為初始聚類中心(聚類中心A0,B0)�����,指定閾值0.1��。K-Means迭代過(guò)程如下:
step 1.1:計(jì)算各樣本距離聚類中心的距離:
樣本A:d(A,A0) = 0;d(A,B0) = 2;因此樣本A屬于A0所在類����;
樣本B:d(B,A0) = 2;d(B,B0) = 0;因此樣本B屬于B0所在類�����;
樣本C:d(C,A0) = 2;d(C,B0) = 2.8;;因此樣本C屬于A0所在類�;
樣本C:d(D,A0) =2.8; d(D,B0) = 2;;因此樣本C屬于B0所在類;
step
1.2:全部樣本分類完畢���,現(xiàn)在計(jì)算A0類(包含樣本AC)和B0類(包含樣本BD)的新的聚類中心:
A1 =(-1, 0); B1 = (1,0);
step 1.3:計(jì)算聚類中心的偏移值是否滿足終止條件:
|A1-A0|= |(-1,0)-(-1,-1) | = |(0,1)| = 1
>0.1��,因此繼續(xù)迭代�����。
step 2.1:計(jì)算各樣本距離聚類中心的距離:
樣本A:d(A,A1) = 1;d(A,B1) = 2.2;因此樣本A屬于A1所在類�;
樣本B:d(B,A1) =2.2; d(B,B1) = 1;因此樣本B屬于B1所在類;
樣本C:d(C,A1) = 1;d(C,B1) = 2.2;;因此樣本C屬于A1所在類�;
樣本D:d(D,A1) =2.2; d(D,B1) = 1;;因此樣本C屬于B1所在類;
step
2.2:全部樣本分類完畢�����,現(xiàn)在計(jì)算A1類(包含樣本AC)和B1類(包含樣本BD)的新的聚類中心:
A2 =(-1, 0); B2 = (1,0);
step 2.3:計(jì)算聚類中心的偏移值是否滿足終止條件:
|A2-A1|= |B2-B1| = 0 <0.1��,因此迭代終止��。
2�、測(cè)試數(shù)據(jù)
下面這個(gè)測(cè)試數(shù)據(jù)有點(diǎn)類似SNS中的好友關(guān)系,假設(shè)是10個(gè)來(lái)自2個(gè)不同的圈子的同學(xué)的SNS聊天記錄���。顯然�����,同一個(gè)圈子內(nèi)的同學(xué)會(huì)有更密切的關(guān)系和互動(dòng)��。
數(shù)據(jù)如下所示�,每一行代表一個(gè)好友關(guān)系���。如第一行表示同學(xué)0與同學(xué)1的親密程度為9(越高表示聯(lián)系越密切)����。
顯然����,這個(gè)數(shù)據(jù)中并沒(méi)有告知我們這10個(gè)同學(xué)分別屬于哪個(gè)圈子。因此我們的目標(biāo)是使用K-Means聚類算法����,將他們聚成2類。
[plain]view plaincopy
0 1 9
0 2 5
0 3 6
0 4 3
1 2 8
......
這個(gè)例子設(shè)計(jì)的很簡(jiǎn)單��。我們使用上一篇文章中提到的關(guān)系矩陣���,將其可視化出來(lái)���,會(huì)看到如下結(jié)果:
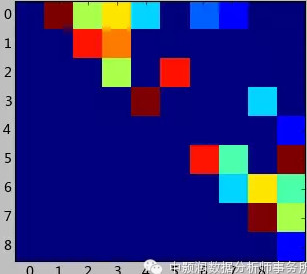
這是個(gè)上三角矩陣,因?yàn)檫@個(gè)數(shù)據(jù)中認(rèn)為好友關(guān)系是對(duì)稱的���。上圖其實(shí)很快能發(fā)現(xiàn)���,0,1,2,3,4用戶緊密聯(lián)系在一起��,而5,6,7,8,9組成了另外一個(gè)圈子。
下面我們看看K-Means算法能否找出這個(gè)答案��。
3�、代碼與分析
K-Means算法的Python代碼如下:
[python]view plaincopy
# -*-coding: utf-8 -*-
frommatplotlib import pyplot
importscipy as sp
importnumpy as np
fromsklearn import svm
importmatplotlib.pyplot as plt
fromsklearn.cluster import KMeans
fromscipy import sparse
#數(shù)據(jù)讀入
data =np.loadtxt('2.txt')
x_p =data[:, :2] # 取前2列
y_p =data[:, 2] # 取前2列
x =(sparse.csc_matrix((data[:,2], x_p.T)).astype(float))[:,
:].todense()
nUser =x.shape[0]
#可視化矩陣
pyplot.imshow(x,interpolation='nearest')
pyplot.xlabel('用戶')
pyplot.ylabel('用戶')
pyplot.xticks(range(nUser))
pyplot.yticks(range(nUser))
pyplot.show()
#使用默認(rèn)的K-Means算法
num_clusters= 2
clf =KMeans(n_clusters=num_clusters, n_init=1,
verbose=1)
clf.fit(x)
print(clf.labels_)
#指定用戶0與用戶5作為初始化聚類中心
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試�����,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情�����;
? 想學(xué)習(xí)CDA考試教材����,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫(kù),點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情;
? 想了解CDA考試含金量��,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330