三種最典型的大數(shù)據(jù)存儲技術(shù)路線
大數(shù)據(jù)這個領(lǐng)域過去5年發(fā)展很快�、熱度很高,但是總的來說目前還在起步階段�。本次研討會我會先談?wù)剶?shù)據(jù),以及大數(shù)據(jù)對數(shù)據(jù)處理技術(shù)的壓力����,然后為大家分享一下為什么這幾年數(shù)據(jù)處理技術(shù)上的創(chuàng)新很多。
1. 數(shù)據(jù)價值的發(fā)現(xiàn)與使用
在大數(shù)據(jù)的4個V中����,最顯著的特征應(yīng)該是Value(價值)。不管數(shù)據(jù)多大��,是什么結(jié)構(gòu)����,來源如何����,能給使用者帶來價值的數(shù)據(jù)是最重要的數(shù)據(jù)����。
我跟數(shù)據(jù)打了20多年的交道,從來沒感覺到搞數(shù)據(jù)的地位有今天這么高�。整個社會對數(shù)據(jù)的認(rèn)知變了,大數(shù)據(jù)最大的貢獻(xiàn)至少是讓社會各個層面開始認(rèn)識到數(shù)據(jù)的重要性�,包括最高領(lǐng)導(dǎo)和底層的老百姓。
目前大家基本達(dá)成共識:數(shù)據(jù)像石油��、煤一樣是寶貴的資產(chǎn)��,其內(nèi)在的價值非常巨大�。另外一個顯著的貢獻(xiàn)無疑是互聯(lián)網(wǎng)企業(yè)對于數(shù)據(jù)的巧妙使用和價值體現(xiàn)。
2. 數(shù)據(jù)處理技術(shù)的回顧
互聯(lián)網(wǎng)的數(shù)據(jù)“大”是不爭的事實����,現(xiàn)在分析一下數(shù)據(jù)處理技術(shù)面臨的挑戰(zhàn)。目前除了互聯(lián)網(wǎng)企業(yè)外��,數(shù)據(jù)處理領(lǐng)域還是傳統(tǒng)關(guān)系型數(shù)據(jù)庫(RDBMS)的天下�。傳統(tǒng)RDBMS的核心設(shè)計思想基本上是30年前形成的��。過去30年脫穎而出的無疑是Oracle公司。全世界數(shù)據(jù)庫市場基本上被Oracle��,IBM/DB2�,Microsoft/SQL Server 壟斷,其他幾家市場份額都比較小���。SAP去年收購了Sybase�����,也想成為數(shù)據(jù)庫廠商���。有份量的獨立數(shù)據(jù)庫廠商現(xiàn)在就剩下Oracle和Teradata。開源數(shù)據(jù)庫主要是MySQL���,PostgreSQL����,除了互聯(lián)網(wǎng)領(lǐng)域外��,其他行業(yè)用的很少�。這些數(shù)據(jù)庫當(dāng)年主要是面向OLTP交易型需求設(shè)計�、開發(fā)的�����,是用來開發(fā)人機(jī)會話應(yīng)用為主的�����。這些傳統(tǒng)數(shù)據(jù)庫底層的物理存儲格式都是行存儲����,比較適合數(shù)據(jù)頻繁的增刪改操作,但對于統(tǒng)計分析類的查詢�����,行存儲其實效率很低���。在這些成熟的數(shù)據(jù)庫產(chǎn)品中��,有2個典型特例:一個是Teradata�����,一個是Sybase IQ���。
Teradata一開始就使用MPP(Massive Parallel Processing)架構(gòu)�,以軟硬一體機(jī)的產(chǎn)品方式提供給客戶����,其定位是高端客戶的數(shù)據(jù)倉庫和決策分析系統(tǒng)�����,Teradata在全世界的客戶只有幾千個�����。在這個數(shù)據(jù)分析高端市場上�����,Teradata一直是老大��,在數(shù)據(jù)分析技術(shù)上Oracle和IBM打不過Teradata����。Sybase IQ是一款最早基于列存儲的關(guān)系型數(shù)據(jù)庫產(chǎn)品,其定位跟Teradata類似,不過是以軟件方式銷售的�。Teradata和Sybase IQ在數(shù)據(jù)分析應(yīng)用上的性能其實都比Oracle,DB2等要普遍好��。
3. 數(shù)據(jù)增長加速�,數(shù)據(jù)多樣化,大數(shù)據(jù)時代來臨
如果說現(xiàn)在是大數(shù)據(jù)時代了�����,其實是數(shù)據(jù)來源發(fā)生了質(zhì)的變化��。在互聯(lián)網(wǎng)出現(xiàn)之前����,數(shù)據(jù)主要是人機(jī)會話方式產(chǎn)生的,以結(jié)構(gòu)化數(shù)據(jù)為主�。所以大家都需要傳統(tǒng)的RDBMS來管理這些數(shù)據(jù)和應(yīng)用系統(tǒng)。那時候的數(shù)據(jù)增長緩慢��、系統(tǒng)都比較孤立�����,用傳統(tǒng)數(shù)據(jù)庫基本可以滿足各類應(yīng)用開發(fā)����。
互聯(lián)網(wǎng)的出現(xiàn)和快速發(fā)展��,尤其是移動互聯(lián)網(wǎng)的發(fā)展����,加上數(shù)碼設(shè)備的大規(guī)模使用���,今天數(shù)據(jù)的主要來源已經(jīng)不是人機(jī)會話了��,而是通過設(shè)備、服務(wù)器����、應(yīng)用自動產(chǎn)生的。傳統(tǒng)行業(yè)的數(shù)據(jù)同時也多起來了��,這些數(shù)據(jù)以非結(jié)構(gòu)��、半結(jié)構(gòu)化為主��,而真正的交易數(shù)據(jù)量并不大����,增長并不快。機(jī)器產(chǎn)生的數(shù)據(jù)正在幾何級增長,比如基因數(shù)據(jù)�、各種用戶行為數(shù)據(jù)、定位數(shù)據(jù)�����、圖片�、視頻、氣象����、地震、醫(yī)療等等����。
所謂的“大數(shù)據(jù)應(yīng)用”主要是對各類數(shù)據(jù)進(jìn)行整理、交叉分析����、比對,對數(shù)據(jù)進(jìn)行深度挖掘����,對用戶提供自助的即席、迭代分析能力����。還有一類就是對非結(jié)構(gòu)化數(shù)據(jù)的特征提取��,以及半結(jié)構(gòu)化數(shù)據(jù)的內(nèi)容檢索��、理解等����。
傳統(tǒng)數(shù)據(jù)庫對這類需求和應(yīng)用無論在技術(shù)上還是功能上都幾乎束手無策����。這樣其實就給類似Hadoop的技術(shù)和平臺提供了很好的發(fā)展機(jī)會和空間?��;ヂ?lián)網(wǎng)公司自然就選擇能支撐自己業(yè)務(wù)的開源技術(shù)了,反過來又推動了開源技術(shù)的快速發(fā)展�。
4. 新的數(shù)據(jù)處理技術(shù)、產(chǎn)品和創(chuàng)新
為了應(yīng)對數(shù)據(jù)處理的壓力�����,過去十年間在數(shù)據(jù)處理技術(shù)領(lǐng)域有了很多的創(chuàng)新和發(fā)展���。除了面向高并發(fā)�、短事務(wù)的OLTP內(nèi)存數(shù)據(jù)庫外(Altibase, Timesten)���,其他的技術(shù)創(chuàng)新和產(chǎn)品都是面向數(shù)據(jù)分析的��,而且是大規(guī)模數(shù)據(jù)分析的����,也可以說是大數(shù)據(jù)分析的�����。
在這些面向數(shù)據(jù)分析的創(chuàng)新和產(chǎn)品中��,除了基于Hadoop環(huán)境下的各種NoSQL外�,還有一類是基于Shared Nothing架構(gòu)的面向結(jié)構(gòu)化數(shù)據(jù)分析的新型數(shù)據(jù)庫產(chǎn)品(可以叫做NewSQL),如:Greenplum(EMC收購)����,Vertica(HP 收購),Asterdata(TD 收購)���,以及南大通用在國內(nèi)開發(fā)的GBase 8a MPP Cluster等����。目前可以看到的類似開源和商用產(chǎn)品達(dá)到幾十個,而且還有新的產(chǎn)品不斷涌出����。一個有趣的現(xiàn)象是這些新的數(shù)據(jù)庫廠商多數(shù)都還沒有10年歷史,而且發(fā)展好的基本都被收購了�。收購這些新型數(shù)據(jù)庫廠商的公司,比如EMC��、HP����,都希望通過收購新技術(shù)和產(chǎn)品進(jìn)入大數(shù)據(jù)處理市場,是新的玩家��。SAP除了收購Sybase外�,自己開發(fā)了一款叫HANA的新產(chǎn)品,這是一款基于內(nèi)存�、面向數(shù)據(jù)分析的內(nèi)存數(shù)據(jù)庫產(chǎn)品。
這類新的分析型數(shù)據(jù)庫產(chǎn)品的共性主要是:
架構(gòu)基于大規(guī)模分布式計算(MPP)���;硬件基于X86 PC 服務(wù)器;存儲基于服務(wù)器自帶的本地硬盤��;操作系統(tǒng)主要是Linux;擁有極高的橫向擴(kuò)展能力(scale out)和內(nèi)在的故障容錯能力和數(shù)據(jù)高可用保障機(jī)制�;能大大降低每TB數(shù)據(jù)的處理成本����,為“大數(shù)據(jù)”處理提供技術(shù)和性價比支撐���。
總的來看�,數(shù)據(jù)處理技術(shù)進(jìn)入了一個新的創(chuàng)新和發(fā)展高潮���,機(jī)會很多��。這里的主要原因是一直沿用了30年的傳統(tǒng)數(shù)據(jù)庫技術(shù)遇到了技術(shù)瓶頸����,而市場和用戶的需求在推動著技術(shù)的創(chuàng)新��,并為此創(chuàng)造了很多機(jī)會����。在大數(shù)據(jù)面前,越來越多的用戶愿意嘗試新技術(shù)和新產(chǎn)品���,不那么保守了���,因為大家開始清晰地看到傳統(tǒng)技術(shù)的瓶頸���,選擇新的技術(shù)才有可能解決他們面臨的新問題。
現(xiàn)在的總體趨勢是在數(shù)據(jù)量快速增長����、多類數(shù)據(jù)分析并存的需求壓力下,數(shù)據(jù)處理技術(shù)朝著細(xì)分方向發(fā)展���,過去30年一種平臺滿足所有應(yīng)用需求的時代已經(jīng)過去�。我們必須開始根據(jù)應(yīng)用需求和數(shù)據(jù)量選擇最適合的產(chǎn)品和技術(shù)來支撐應(yīng)用����。世界數(shù)據(jù)處理市場格局正在發(fā)生革命性的變化,傳統(tǒng)數(shù)據(jù)庫(OldSQL)一統(tǒng)天下變成了OldSQL+NewSQL+NoSQL+其他新技術(shù)(流���、實時��、內(nèi)存等)共同支撐多類應(yīng)用的局面��。在大數(shù)據(jù)時代����,需要的是數(shù)據(jù)驅(qū)動最優(yōu)平臺和產(chǎn)品的選擇����。
5. MPP關(guān)系型數(shù)據(jù)庫與Hadoop的非關(guān)系型數(shù)據(jù)庫
大數(shù)據(jù)存儲技術(shù)路線最典型的共有三種:
第一種是采用MPP架構(gòu)的新型數(shù)據(jù)庫集群,重點面向行業(yè)大數(shù)據(jù)����,采用Shared Nothing架構(gòu),通過列存儲�����、粗粒度索引等多項大數(shù)據(jù)處理技術(shù)�,再結(jié)合MPP架構(gòu)高效的分布式計算模式,完成對分析類應(yīng)用的支撐����,運行環(huán)境多為低成本PC Server,具有高性能和高擴(kuò)展性的特點�����,在企業(yè)分析類應(yīng)用領(lǐng)域獲得極其廣泛的應(yīng)用���。
這類MPP產(chǎn)品可以有效支撐PB級別的結(jié)構(gòu)化數(shù)據(jù)分析����,這是傳統(tǒng)數(shù)據(jù)庫技術(shù)無法勝任的。對于企業(yè)新一代的數(shù)據(jù)倉庫和結(jié)構(gòu)化數(shù)據(jù)分析�,目前最佳選擇是MPP數(shù)據(jù)庫。
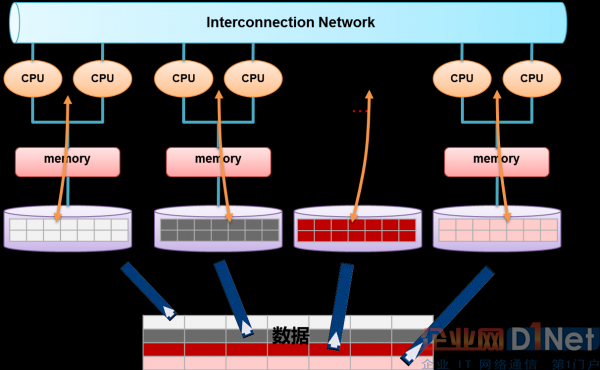
圖1 MPP架構(gòu)圖
第二種是基于Hadoop的技術(shù)擴(kuò)展和封裝��,圍繞Hadoop衍生出相關(guān)的大數(shù)據(jù)技術(shù)����,應(yīng)對傳統(tǒng)關(guān)系型數(shù)據(jù)庫較難處理的數(shù)據(jù)和場景,例如針對非結(jié)構(gòu)化數(shù)據(jù)的存儲和計算等�����,充分利用Hadoop開源的優(yōu)勢�����,伴隨相關(guān)技術(shù)的不斷進(jìn)步���,其應(yīng)用場景也將逐步擴(kuò)大���,目前最為典型的應(yīng)用場景就是通過擴(kuò)展和封裝Hadoop來實現(xiàn)對互聯(lián)網(wǎng)大數(shù)據(jù)存儲�、分析的支撐。這里面有幾十種NoSQL技術(shù)�,也在進(jìn)一步的細(xì)分。對于非結(jié)構(gòu)�、半結(jié)構(gòu)化數(shù)據(jù)處理、復(fù)雜的ETL流程����、復(fù)雜的數(shù)據(jù)挖掘和計算模型�����,Hadoop平臺更擅長����。
第三種是大數(shù)據(jù)一體機(jī)�����,這是一種專為大數(shù)據(jù)的分析處理而設(shè)計的軟��、硬件結(jié)合的產(chǎn)品����,由一組集成的服務(wù)器、存儲設(shè)備、操作系統(tǒng)、數(shù)據(jù)庫管理系統(tǒng)以及為數(shù)據(jù)查詢�、處理����、分析用途而特別預(yù)先安裝及優(yōu)化的軟件組成,高性能大數(shù)據(jù)一體機(jī)具有良好的穩(wěn)定性和縱向擴(kuò)展性。
6. 數(shù)據(jù)倉庫的重要性
在互聯(lián)網(wǎng)高速發(fā)展之前�����,無論是電信運營商,還是大銀行,保險公司等都花費了巨額資金建立了自己的企業(yè)級數(shù)據(jù)倉庫�����。這些倉庫主要是為企業(yè)決策者生成企業(yè)的一些關(guān)鍵指標(biāo)(KPI)����,有的企業(yè)有幾千張�、甚至上萬張KPI報表,有日表�����,周表���,月表等等。這些系統(tǒng)有幾個主要特征:
技術(shù)架構(gòu)主要基于傳統(tǒng)RDBMS + 小型機(jī) + 高端陣列 (就是大家說的IOE)�,當(dāng)然數(shù)據(jù)庫有部分DB2,Teradata等。
報表基本都是固定的靜態(tài)報表�����,產(chǎn)生的方式是T+1 (無法即時產(chǎn)生)�����。
數(shù)據(jù)量增長相對緩慢,DW的環(huán)境變化很少。
最終用戶只能看匯總的報表,很少能夠基于匯總數(shù)據(jù)做動態(tài)drilldown (鉆取)����。
多數(shù)領(lǐng)導(dǎo)基本上認(rèn)為花了很多錢�,但看不出是否值得做��,有雞肋的感覺���。最后大家對大量的報表都視而不見了����。
這類系統(tǒng)屬于“高富帥”���,是有錢的企業(yè)給領(lǐng)導(dǎo)用的�����。
最后���,目前多數(shù)企業(yè)和部門根本就沒有數(shù)據(jù)倉庫。其實大家對傳統(tǒng)數(shù)據(jù)的分析還沒做得太好���、還沒有普及��,現(xiàn)在又遇上了大數(shù)據(jù)��。
數(shù)據(jù)倉庫對企業(yè)是真正有用的����,其關(guān)鍵還是如何把數(shù)據(jù)用好。
7. 數(shù)據(jù)處理技術(shù)的核心問題到底是什么���?
其實我們一直面臨著數(shù)據(jù)處理中最核心���、最大的問題,那就是性能問題���。性能不好的技術(shù)和產(chǎn)品是沒有生命力的���。數(shù)據(jù)處理性能問題不是因為大數(shù)據(jù)才出現(xiàn),也不會有了大數(shù)據(jù)技術(shù)而消失���。處理性能的提升將促進(jìn)對數(shù)據(jù)價值的挖掘和使用�,而數(shù)據(jù)價值挖掘的越多��、越深入��,對處理技術(shù)要求就越高����。
目前的數(shù)據(jù)倉庫只能滿足一些靜態(tài)統(tǒng)計需求,而且是T+1模式���;也是因為性能問題����,運營商無法有效構(gòu)造超過PB級別的大數(shù)據(jù)倉庫�,無法提供即席查詢、自助分析����、復(fù)雜模型迭代分析的能力,更無法讓大量一線人員使用數(shù)據(jù)分析手段�����。
今天如果做“大數(shù)據(jù)”數(shù)據(jù)倉庫��,運營商面臨的挑戰(zhàn)比上個10年要大的多�。目前沒有單一技術(shù)和平臺能夠滿足類似運營商的數(shù)據(jù)分析需求?����?蛇x的方案只能是混搭架構(gòu)�,用不同的分布式技術(shù)來支撐一個超越PB級的數(shù)據(jù)倉庫系統(tǒng)����。這個混搭架構(gòu)主要的核心是新一代的MPP并行數(shù)據(jù)庫集群+ Hadoop集群�,再加上一些內(nèi)存計算、甚至流計算技術(shù)等���。
大數(shù)據(jù)需要多元化的技術(shù)來支撐�。當(dāng)前數(shù)據(jù)處理對企業(yè)的挑戰(zhàn)越來越大�����,主要是下面幾個原因:
第一個原因是數(shù)據(jù)量已經(jīng)是上一代的一個數(shù)量級了����,1個省份級運營商1年就可超越1PB結(jié)構(gòu)化數(shù)據(jù)。
第二個原因是“大數(shù)據(jù)”關(guān)注的更多是用戶行為�����、群體趨勢���、事件之間的相關(guān)性等��,而不僅僅是過去的KPI����,。這就對數(shù)據(jù)分析平臺對數(shù)據(jù)的分析能力和性能提出了新的要求和挑戰(zhàn)���。
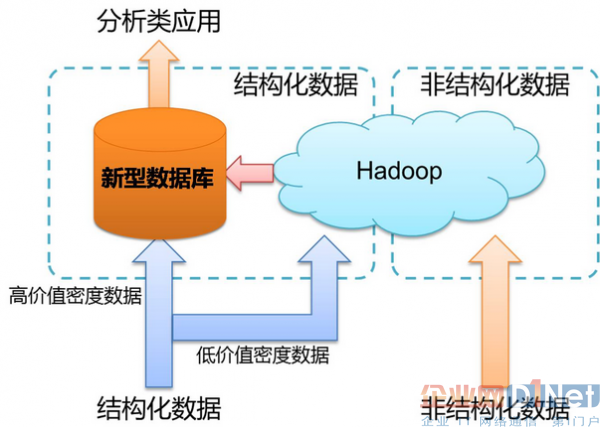
圖2未來大數(shù)據(jù)處理的核心技術(shù)
8. 總結(jié)——新型MPP數(shù)據(jù)庫的價值
技術(shù):基于列存儲+MPP架構(gòu)的新型數(shù)據(jù)庫在核心技術(shù)上跟傳統(tǒng)數(shù)據(jù)庫有巨大差別,是為面向結(jié)構(gòu)化數(shù)據(jù)分析設(shè)計開發(fā)的�,能夠有效處理PB級別的數(shù)據(jù)量。在技術(shù)上為很多行業(yè)用戶解決了數(shù)據(jù)處理性能問題����。
用戶價值:新型數(shù)據(jù)庫是運行在x-86 PC服務(wù)器之上的,可以大大降低數(shù)據(jù)處理的成本(1個數(shù)量級)��。
未來趨勢:新型數(shù)據(jù)庫將逐步與Hadoop生態(tài)系統(tǒng)結(jié)合混搭使用���,用MPP處理PB級別的����、高質(zhì)量的結(jié)構(gòu)化數(shù)據(jù)�,同時為應(yīng)用提供豐富的SQL和事務(wù)支持能力;用Hadoop實現(xiàn)半結(jié)構(gòu)化���、非結(jié)構(gòu)化數(shù)據(jù)處理��。這樣可同時滿足結(jié)構(gòu)化����、半結(jié)構(gòu)化和非結(jié)構(gòu)化數(shù)據(jù)的處理需求。
下圖是南大通用正在做的大數(shù)據(jù)處理平臺架構(gòu)圖�����,將逐步把MPP與Hadoop技術(shù)融合在一起���,為用戶提供透明的數(shù)據(jù)管理平臺����。
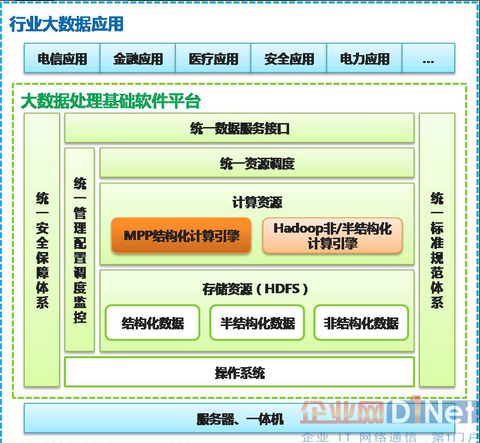
圖3 MPP與Hadoop技術(shù)融合的產(chǎn)品架構(gòu)圖
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認(rèn)證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材�,點擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量�,點擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330