CDA數(shù)據(jù)分析師 出品
作者:真達(dá)、Mika
數(shù)據(jù):真達(dá)
后期:澤龍
【導(dǎo)讀】
今天教大家如何用Python寫一個(gè)員工流失預(yù)測模型���。Show me data�,用數(shù)據(jù)說話���。我們聊一聊員工離職��,說到離職的原因����,可謂多種多樣���。人們歸總了兩點(diǎn):
1. 錢沒給到位
2. 心受委屈了
有人離職是因?yàn)椤笆澜缒敲创?���,我想去看看”�,也有人覺得“懷有絕技在身��,不怕天下無路”����。
另一方面�,員工離職對于企業(yè)而言有什么影響呢?
要知道�����,企業(yè)培養(yǎng)人才需要大量的成本���,為了防止人才再次流失�����,員工流失分析就顯得十分重要了。這不僅僅是公司評估員工流動率的過程��,通過找到導(dǎo)致員工流失的主要因素�����,預(yù)測未來的員工離職狀況���,從而進(jìn)一步減少員工流失��。
那么�����,哪些因素最容易導(dǎo)致員工離職呢����?
這次我們用數(shù)據(jù)說話,
教你如何用Python寫一個(gè)員工流失預(yù)測模型�。
01、數(shù)據(jù)理解
我們分析了kaggle平臺分享的員工離職相關(guān)的數(shù)據(jù)集��,共有10個(gè)字段14999條記錄��。數(shù)據(jù)主要包括影響員工離職的各種因素(員工滿意度����、績效考核、參與項(xiàng)目數(shù)�����、平均每月工作時(shí)長����、工作年限���、是否發(fā)生過工作差錯(cuò)、5年內(nèi)是否升職���、部門����、薪資)以及員工是否已經(jīng)離職的對應(yīng)記錄�。字段說明如下:
02、讀入數(shù)據(jù)
df = pd.read_csv('HR_comma_sep.csv')
df.head()
df = pd.read_csv('HR_comma_sep.csv')
df.head()
df = pd.read_csv('HR_comma_sep.csv')
df.head()
# 查看缺失值 print(df.isnull().any().sum())
# 查看缺失值 print(df.isnull().any().sum())
# 查看缺失值 print(df.isnull().any().sum())
可以發(fā)現(xiàn)�,數(shù)據(jù)質(zhì)量良好,沒有缺失數(shù)據(jù)���。
03����、探索性分析
描述性統(tǒng)計(jì)
df.describe().T
從上述描述性分析結(jié)果可以看出:
-
員工滿意度:范圍0.09~1, 中位數(shù)0.640, 均值0.613, 總體來說員工對公司比較滿意��;
-
績效考核:范圍0.36~1, 中位數(shù)0.72, 均值0.716, 員工平均考核水平在中等偏上�����;
-
參與項(xiàng)目數(shù):范圍2~7, 中位數(shù)4, 均值3.8, 平均參加項(xiàng)目數(shù)約4個(gè)�����;
-
平均每月工作時(shí)長:范圍96~310小時(shí), 中位數(shù)200, 均值201。
-
工作年限:范圍2~10年, 中位數(shù)3, 均值3.5。
離職人數(shù)占比
整理數(shù)據(jù)后發(fā)現(xiàn)���,總共有14999人,其中紅色部分代表離職人群,用數(shù)字1表示����,藍(lán)色為未離職人群����,用數(shù)字0表示。離職人數(shù)為3571��,占總?cè)藬?shù)的23.8%����。
員工滿意度
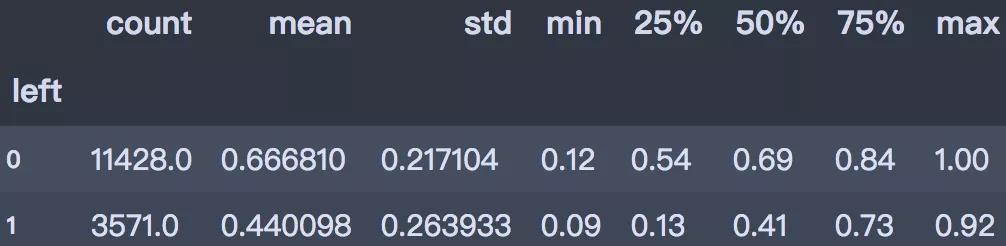
從直方圖可以看出,離職員工的滿意度評分明顯偏低����,平均值為0.44�����。滿意度低于0.126分的離職率為97.2%�?����?梢娞嵘龁T工滿意度可以有效防止人員流失�����。
df.groupby('left')['satisfaction_level'].describe()
def draw_numeric_graph(x_series, y_series, title): sat_cut = pd.cut(x_series, bins=25)
cross_table = round(pd.crosstab(sat_cut, y_series, normalize='index'),4)*100 x_data = cross_table.index.astype('str').tolist()
y_data1 = cross_table[cross_table.columns[1]].values.tolist()
y_data2 = cross_table[cross_table.columns[0]].values.tolist()
bar = Bar(init_opts=opts.InitOpts(width='1350px', height='750px'))
bar.add_xaxis(x_data)
bar.add_yaxis(str(cross_table.columns[1]), y_data1, stack='stack1', category_gap='0%')
bar.add_yaxis(str(cross_table.columns[0]), y_data2, stack='stack1', category_gap='0%')
bar.set_global_opts(title_opts=opts.TitleOpts(title),
xaxis_opts=opts.AxisOpts(name=x_series.name, name_location='middle', name_gap=30),
yaxis_opts=opts.AxisOpts(name='百分比', name_location='middle', name_gap=30, min_=0, max_=100),
legend_opts=opts.LegendOpts(orient='vertical', pos_top='15%', pos_right='2%'))
bar.set_series_opts(label_opts=opts.LabelOpts(is_show=False),
itemstyle_opts=opts.ItemStyleOpts(border_color='black', border_width=0.3))
bar.set_colors(['#BF4C51', '#8CB9D0'])
return bar
bar1 = draw_numeric_graph(df['satisfaction_level'], df['left'], title='滿意度評分與是否離職')
bar1.render()
績效考核
平均來看���,績效考核成績在離職/未離職員工之間差異不大�。在離職員工中����,績效考核低、能力不夠和績效考核較高但工作壓力大���、滿意度低����、對薪資不滿意可能成為離職的原因�。
平均每月工作時(shí)長
從直方圖可以看出,月工作時(shí)長正常的員工離職率最低�����。而工時(shí)過低�、過高的員工離職人數(shù)最多。證明恰當(dāng)?shù)墓ぷ魅蝿?wù)分配是非常重要的�����。
參加項(xiàng)目數(shù)
從圖中可以看出:除項(xiàng)目數(shù)為2以外����,隨著項(xiàng)目數(shù)的增多,離職率在增大���,且項(xiàng)目數(shù)是7的時(shí)候����,離職率達(dá)到了100%以上�。綜上兩點(diǎn)����,項(xiàng)目數(shù)2的離職率高����,可能是這部分人工作能力不被認(rèn)可。項(xiàng)目數(shù)6��、7的總體少�����,離職率高�����,體現(xiàn)了他們的工作能力強(qiáng)�,但同時(shí)工作壓力太大導(dǎo)致他們離職。
員工工齡
可以看到7年及以上工齡的員工基本沒有離職�����,只有工齡為5年的員工離職人數(shù)超過在職人數(shù)�。可見工齡長于6年的員工���,由于種種原因�����,其“忠誠度”較高��。
而員工進(jìn)入公司工作的第5年是一個(gè)較為“危險(xiǎn)”的年份�,也許是該企業(yè)的“5年之癢”����,應(yīng)當(dāng)重點(diǎn)關(guān)注該階段的員工滿意度、職業(yè)晉升等情況��,以順利過渡��。
工作事故
從圖中可看出�,是否發(fā)生工作事故對員工離職的影響較小,可推測該企業(yè)處理工作事故的方式有可取之處���。
職位晉升
從條形圖可以看出�����,在過去5年內(nèi)獲得未晉升的員工離職率為24.2%�����,比獲得晉升的員工高4倍���。設(shè)定良好的晉升通道可以很好的防止員工流失�。
薪資水平
可明顯看出�,薪資越高離職人數(shù)越少。證明為了減少離職率����,提升員工福利待遇是一個(gè)可行的手段。
不同部門
可見各部門離職率如上圖�����,離職率由高到低�����,前三位分別是:人力部�、財(cái)務(wù)部、科技部���。之后依次是:支持部����、銷售部、市場部����、IT部門、產(chǎn)品部���、研發(fā)部、管理部�。對于離職率過高的部門,應(yīng)進(jìn)一步分析關(guān)鍵原因���。
04����、數(shù)據(jù)預(yù)處理
由于sklearn在建模時(shí)不接受類別型變量��,我們主要對數(shù)據(jù)做以下處理���,以方便后續(xù)建模分析:
-
薪資水平salary為定序變量, 因此將其字符型轉(zhuǎn)化為數(shù)值型�����。
-
崗位是定類型變量, 對其進(jìn)行one-hot編碼���。
df['salary'] = df['salary'].map({"low": 0, "medium": 1, "high": 2}) df_dummies = pd.get_dummies(df,prefix='sales')
df_dummies.head()
05�、建模分析
我們使用決策樹和隨機(jī)森林進(jìn)行模型建置��,首先導(dǎo)入所需包:
from sklearn.model_selection import train_test_split, GridSearchCV from sklearn.tree import DecisionTreeClassifier from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import classification_report, f1_score, roc_curve, plot_roc_curve
然后劃分訓(xùn)練集和測試集�,采用分層抽樣方法劃分80%數(shù)據(jù)為訓(xùn)練集,20%數(shù)據(jù)為測試集����。
train_pred = GS.best_estimator_.predict(X_train)
test_pred = GS.best_estimator_.predict(X_test) print('訓(xùn)練集:', classification_report(y_train, train_pred)) print('-' * 60) print('測試集:', classification_report(y_test, test_pred))
決策樹
我們使用決策樹進(jìn)行建模,設(shè)置特征選擇標(biāo)準(zhǔn)為gini���,樹的深度為5����。輸出分類的評估報(bào)告:
clf = DecisionTreeClassifier(criterion='gini', max_depth=5, random_state=25)
clf.fit(X_train, y_train)
train_pred = clf.predict(X_train)
test_pred = clf.predict(X_test) print('訓(xùn)練集:', classification_report(y_train, train_pred)) print('-' * 60) print('測試集:', classification_report(y_test, test_pred))
訓(xùn)練集: precision recall f1-score support 0 0.98 0.99 0.98 9142 1 0.97 0.93 0.95 2857 accuracy 0.98 11999 macro avg 0.97 0.96 0.97 11999 weighted avg 0.98 0.98 0.97 11999 ------------------------------------------------------------ 測試集: precision recall f1-score support 0 0.98 0.99 0.98 2286 1 0.97 0.93 0.95 714 accuracy 0.98 3000 macro avg 0.97 0.96 0.97 3000 weighted avg 0.98 0.98 0.98 3000
假設(shè)我們關(guān)注的是1類(即離職類)的F1-score,可以看到訓(xùn)練集的分?jǐn)?shù)為0.95��,測試集分?jǐn)?shù)為0.95�。
# 重要性 imp = pd.DataFrame([*zip(X_train.columns,clf.feature_importances_)], columns=['vars', 'importance'])
imp.sort_values('importance', ascending=False)
imp = imp[imp.importance!=0]
imp
在屬性的重要性排序中,員工滿意度最高�����,其次是最新的績效考核、參與項(xiàng)目數(shù)�����、每月工作時(shí)長�。
然后使用網(wǎng)格搜索進(jìn)行參數(shù)調(diào)優(yōu)。
parameters = {'splitter':('best','random'),
'criterion':("gini","entropy"),
"max_depth":[*range(1, 20)],
}
clf = DecisionTreeClassifier(random_state=25)
GS = GridSearchCV(clf, parameters, cv=10)
GS.fit(X_train, y_train) print(GS.best_params_) print(GS.best_score_)
{'criterion': 'gini', 'max_depth': 15, 'splitter': 'best'}
0.9800813177648042
使用最優(yōu)的模型重新評估訓(xùn)練集和測試集效果:
train_pred = GS.best_estimator_.predict(X_train)
test_pred = GS.best_estimator_.predict(X_test) print('訓(xùn)練集:', classification_report(y_train, train_pred)) print('-' * 60) print('測試集:', classification_report(y_test, test_pred))
訓(xùn)練集: precision recall f1-score support 0 1.00 1.00 1.00 9142 1 1.00 0.99 0.99 2857 accuracy 1.00 11999 macro avg 1.00 0.99 1.00 11999 weighted avg 1.00 1.00 1.00 11999 ------------------------------------------------------------ 測試集: precision recall f1-score support 0 0.99 0.98 0.99 2286 1 0.95 0.97 0.96 714 accuracy 0.98 3000 macro avg 0.97 0.98 0.97 3000 weighted avg 0.98 0.98 0.98 3000
可見在最優(yōu)模型下模型效果有較大提升����,1類的F1-score訓(xùn)練集的分?jǐn)?shù)為0.99,測試集分?jǐn)?shù)為0.96���。
隨機(jī)森林
下面使用集成算法隨機(jī)森林進(jìn)行模型建置,并調(diào)整max_depth參數(shù)����。
rf_model = RandomForestClassifier(n_estimators=1000, oob_score=True, n_jobs=-1,
random_state=0)
parameters = {'max_depth': np.arange(3, 17, 1) }
GS = GridSearchCV(rf_model, param_grid=parameters, cv=10)
GS.fit(X_train, y_train) print(GS.best_params_) print(GS.best_score_)
{'max_depth': 16} 0.988582151793161
train_pred = GS.best_estimator_.predict(X_train)
test_pred = GS.best_estimator_.predict(X_test) print('訓(xùn)練集:', classification_report(y_train, train_pred)) print('-' * 60) print('測試集:', classification_report(y_test, test_pred))
訓(xùn)練集: precision recall f1-score support 0 1.00 1.00 1.00 9142 1 1.00 0.99 0.99 2857 accuracy 1.00 11999 macro avg 1.00 1.00 1.00 11999 weighted avg 1.00 1.00 1.00 11999 ------------------------------------------------------------ 測試集: precision recall f1-score support 0 0.99 1.00 0.99 2286 1 0.99 0.97 0.98 714 accuracy 0.99 3000 macro avg 0.99 0.99 0.99 3000 weighted avg 0.99 0.99 0.99 3000
可以看到在調(diào)優(yōu)之后的隨機(jī)森林模型中,1類的F1-score訓(xùn)練集的分?jǐn)?shù)為0.99����,測試集分?jǐn)?shù)為0.98。
模型后續(xù)可優(yōu)化方向:
-
屬性:數(shù)值型數(shù)據(jù)常常是模型不穩(wěn)定的來源��,可考慮對其進(jìn)行分箱��;重要屬性篩選和字段擴(kuò)充;
-
算法:其他的集成方法����;不同效能評估下的作法調(diào)整。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試�����,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情�����;
? 想學(xué)習(xí)CDA考試教材�,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫�,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量�,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330