機器學(xué)習(xí)中���,我們最常遇到的就是無監(jiān)督�,有監(jiān)督�����,半監(jiān)督了。無監(jiān)督和有監(jiān)督的區(qū)別�,小編之前跟大家分享過,今天跟大家分享的是無監(jiān)督機器學(xué)習(xí)中常見的聚類算法����,希望對大家無監(jiān)督學(xué)習(xí)有所幫助。
一���、基本概念
1.無監(jiān)督學(xué)習(xí):
無監(jiān)督學(xué)習(xí)是機器學(xué)習(xí)的一種方法�����,根據(jù)類別未知(沒有被標記)的訓(xùn)練樣本解決模式識別中的各種問題�����。無監(jiān)督學(xué)習(xí)應(yīng)用主要包含:聚類分析����、關(guān)系規(guī)則����、維度縮減。
2.聚類:
無監(jiān)督學(xué)習(xí)里典型例子是聚類����。聚類是把相似的對象通過靜態(tài)分類的方法分成不同的組別或者更多的子集�,這樣讓在同一個子集中的成員對象都有相似的一些屬性����,常見的包括在坐標系中更加短的空間距離等。
最常見的無監(jiān)督聚類算法:
K均值聚類
分層聚類
基于密度的掃描聚類(DBSCAN)
二���、無監(jiān)督聚類算法--K均值聚類
K均值聚類 是我們最常用的基于歐式距離的聚類算法,它是數(shù)值的����、非監(jiān)督的、非確定的�、迭代的,該算法旨在最小化一個目標函數(shù)——誤差平方函數(shù)(所有的觀測點與其中心點的距離之和)���,其認為兩個目標的距離越近����,相似度越大��,由于具有出色的速度和良好的可擴展性��,K均值聚類算得上是最著名的聚類方法。
1.K均值中最常用的距離是歐氏距離平方��。m維空間中兩點x和y之間的距離的示例是: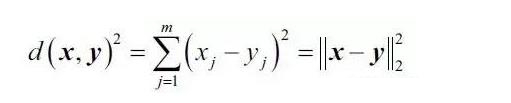
這里�����,j是采樣點x和y的第j維(或特征列)�����。
集群慣性是聚類上下文中給出的平方誤差之和的名稱����,表示如下: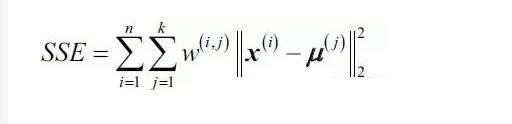
其中μ(j)是簇j的質(zhì)心,并且如果樣本x(i)在簇j中則w(i���,j)是1.否則是0.
K均值可以理解為試圖最小化群集慣性因子的算法���。
2.具體算法
(1)選擇k值,即我們想要查找的聚類數(shù)量��。
(2)算法將隨機選擇每個聚類的質(zhì)心���。
(3)將每個數(shù)據(jù)點分配給最近的質(zhì)心(使用歐氏距離)�����。
(4)計算群集慣性�。
(5)將計算新的質(zhì)心作為屬于上一步的質(zhì)心的點的平均值。換句話說���,通過計算數(shù)據(jù)點到每個簇中心的最小二次誤差�,將中心移向該點����。
(6)返回第3步。
二���、無監(jiān)督聚類算法--分層聚類
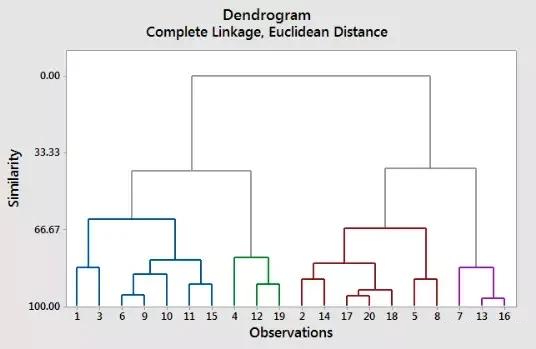
1.分層聚類是基于prototyope的聚類算法的替代方案。分層聚類的主要優(yōu)點是不需要指定聚類的數(shù)量��,它會自己找到它����。此外,它還可以繪制樹狀圖���。樹狀圖是二元分層聚類的可視化���。
在底部融合的觀察是相似的��,而在頂部的觀察是完全不同的�����。對于樹狀圖����,基于垂直軸的位置而不是水平軸的位置進行結(jié)算���。
2.分層聚類的類型
分層聚類有兩種方法:集聚和分裂�����。
分裂:這種方法首先將所有數(shù)據(jù)點放入一個集群中���。 然后,它將迭代地將簇分割成較小的簇�����,直到它們中的每一個僅包含一個樣本。
集聚:這種方法從每個樣本作為不同的集群開始���,然后將它們彼此靠近��,直到只有一個集群���。
3.分層聚類優(yōu)缺點
分層聚類的優(yōu)點;
(1)由此產(chǎn)生的層次結(jié)構(gòu)表示可以提供非常豐富的信息。
(2)樹狀圖提供了一種有趣且信息豐富的可視化方式���。
(3)當(dāng)數(shù)據(jù)集包含真正的層次關(guān)系時�,它們特別強大�����。
分層聚類的缺點:
(1)分層聚類對異常值非常敏感�����,并且在其存在的情況下��,模型性能顯著降低�����。
(2)從計算上講�,分層聚類非常昂貴。
三�、無監(jiān)督聚類算法--DBSCAN 聚類
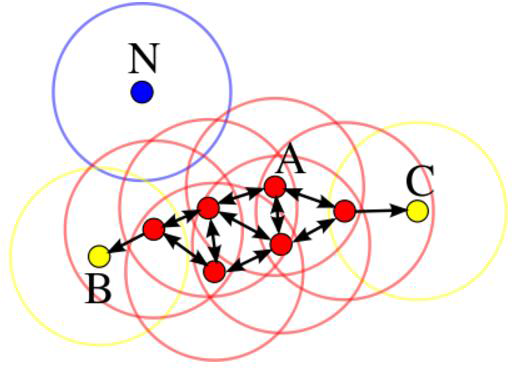
DBSCAN(帶噪聲的基于密度的空間聚類方法)是一種流行的聚類算法,它被用來在預(yù)測分析中替代 K 均值算法�。它并不要求輸入簇的個數(shù)才能運行。但是�����,你需要對其他兩個參數(shù)進行調(diào)優(yōu)��。
優(yōu)缺點:
1.優(yōu)點
①不需要指定簇的個數(shù);
②可以對任意形狀的稠密數(shù)據(jù)集進行聚類��,相對的���,K-Means之類的聚類算法一般只適用于凸數(shù)據(jù)集;
③擅長找到離群點(檢測任務(wù));
④兩個參數(shù)ε\varepsilonε和minPts就夠了;
⑤聚類結(jié)果沒有偏倚����,相對的�,K-Means之類的聚類算法初始值對聚類結(jié)果有很大影響。
2.缺點
①高維數(shù)據(jù)有些困難;
②Sklearn中效率很慢(數(shù)據(jù)削減策略);
③如果樣本集的密度不均勻��、聚類間距差相差很大時�,聚類質(zhì)量較差�,這時用DBSCAN聚類一般不適合;
④調(diào)參相對于傳統(tǒng)的K-Means之類的聚類算法稍復(fù)雜�,主要需要對距離閾值ε\varepsilonε,鄰域樣本數(shù)閾值MinPts聯(lián)合調(diào)參�,不同的參數(shù)組合對最后的聚類效果有較大影響。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學(xué)習(xí)CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330