把近朱者赤�����,近墨者黑這一思想運(yùn)用到機(jī)器學(xué)習(xí)中會(huì)產(chǎn)生什么?當(dāng)然是KNN最鄰近算法啦!KNN(全稱K-Nearest Neighbor)最鄰近分類算法是數(shù)據(jù)挖掘分類算法中最簡(jiǎn)單的算法之一,白話解釋一下就是:由你的鄰居來(lái)推斷出你的類別�。那么KNN算法的原理是什么,如何實(shí)現(xiàn)?一起與小編來(lái)看下面的內(nèi)容吧��。
一�����、KNN最鄰近算法概念
KNN最鄰近算法�����,是著名的模式識(shí)別統(tǒng)計(jì)學(xué)方法之一��,在機(jī)器學(xué)習(xí)分類算法中占有很高的地位��。KNN最鄰近算法在理論上比較成熟���,不僅是最簡(jiǎn)單的機(jī)器學(xué)習(xí)算法之一����,而且也是基于實(shí)例的學(xué)習(xí)方法中最基本的�,最好的文本分類算法之一。
KNN最鄰近算法基本做法是:給定測(cè)試實(shí)例,基于某種距離度量找出訓(xùn)練集中與其最靠近的k個(gè)實(shí)例點(diǎn)�����,然后基于這k個(gè)最近鄰的信息來(lái)進(jìn)行預(yù)測(cè)����。
KNN最鄰近算法不具有顯式的學(xué)習(xí)過(guò)程,事實(shí)上��,它是懶惰學(xué)習(xí)(lazy learning)的著名代表���,此類學(xué)習(xí)技術(shù)在訓(xùn)練階段僅僅是把樣本保存起來(lái)����,訓(xùn)練時(shí)間開(kāi)銷為零�����,待收到測(cè)試樣本后再進(jìn)行處理�。
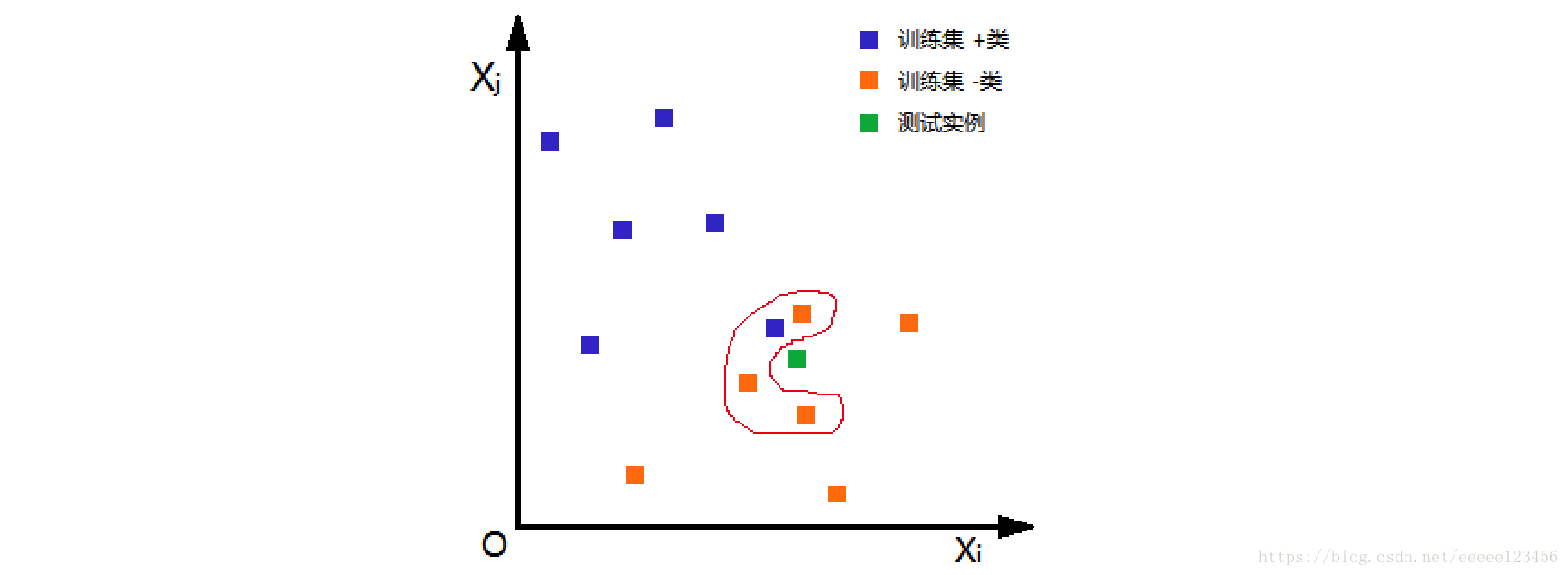
二、KNN最鄰近算法三要素
KNN最鄰近算法三要素為:距離度量���、k值的選擇及分類決策規(guī)則。根據(jù)選擇的距離度量(如曼哈頓距離或歐氏距離),可計(jì)算測(cè)試實(shí)例與訓(xùn)練集中的每個(gè)實(shí)例點(diǎn)的距離��,根據(jù)k值選擇k個(gè)最近鄰點(diǎn)�,最后根據(jù)分類決策規(guī)則將測(cè)試實(shí)例分類。
1.距離度量
特征空間中的兩個(gè)實(shí)例點(diǎn)的距離是兩個(gè)實(shí)例點(diǎn)相似程度的反映���。K近鄰法的特征空間一般是n維實(shí)數(shù)向量空間Rn�。使用的距離是歐氏距離���,但也可以是其他距離��,如更一般的Lp距離或Minkowski距離����。
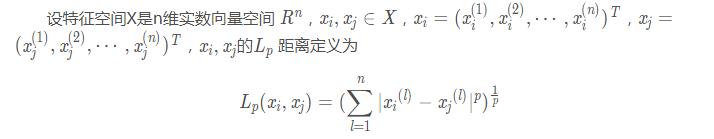
這里p≥1.
當(dāng)p=1時(shí)�,稱為曼哈頓距離(Manhattan distance),即
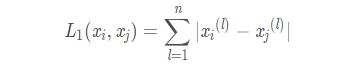
當(dāng)p=2時(shí)�,稱為歐氏距離(Euclidean distance),即
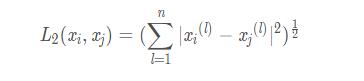

2.k值的選擇
k值的選擇會(huì)對(duì)KNN最鄰近算法的結(jié)果產(chǎn)生重大影響����。在應(yīng)用中,k值一般取一個(gè)比較小的數(shù)值��,通常采用交叉驗(yàn)證法來(lái)選取最優(yōu)的k值。
3.分類決策規(guī)則
KNN最鄰近算法中的分類決策規(guī)則通常是多數(shù)表決���,即由輸入實(shí)例的k個(gè)鄰近的訓(xùn)練實(shí)例中的多數(shù)類��,決定輸入實(shí)例的類�����。
三�、KNN最鄰近算法優(yōu)缺點(diǎn)
1.優(yōu)點(diǎn)
①簡(jiǎn)單��,易于理解���,易于實(shí)現(xiàn)����,無(wú)需參數(shù)估計(jì)���,無(wú)需訓(xùn)練;
②精度高����,對(duì)異常值不敏感(個(gè)別噪音數(shù)據(jù)對(duì)結(jié)果的影響不是很大);
③適合對(duì)稀有事件進(jìn)行分類;
④特別適合于多分類問(wèn)題(multi-modal,對(duì)象具有多個(gè)類別標(biāo)簽)�,KNN要比SVM表現(xiàn)要好.
2.缺點(diǎn)
①對(duì)測(cè)試樣本分類時(shí)的計(jì)算量大����,空間開(kāi)銷大�,因?yàn)閷?duì)每一個(gè)待分類的文本都要計(jì)算它到全體已知樣本的距離��,才能求得它的K個(gè)最近鄰點(diǎn)�。目前常用的解決方法是事先對(duì)已知樣本點(diǎn)進(jìn)行剪輯,事先去除對(duì)分類作用不大的樣本;
②可解釋性差��,無(wú)法給出決策樹(shù)那樣的規(guī)則;
③最大的缺點(diǎn)是當(dāng)樣本不平衡時(shí)�,如一個(gè)類的樣本容量很大,而其他類樣本容量很小時(shí)��,有可能導(dǎo)致當(dāng)輸入一個(gè)新樣本時(shí)���,該樣本的K個(gè)鄰居中大容量類的樣本占多數(shù)��。該算法只計(jì)算“最近的”鄰居樣本���,某一類的樣本數(shù)量很大,那么或者這類樣本并不接近目標(biāo)樣本��,或者這類樣本很靠近目標(biāo)樣本���。無(wú)論怎樣��,數(shù)量并不能影響運(yùn)行結(jié)果��??梢圆捎脵?quán)值的方法(和該樣本距離小的鄰居權(quán)值大)來(lái)改進(jìn);
④消極學(xué)習(xí)方法。
四�����、KNN算法實(shí)現(xiàn)
主要有以下三個(gè)步驟:
1. 算距離:給定待分類樣本�,計(jì)算它與已分類樣本中的每個(gè)樣本的距離;
2. 找鄰居:圈定與待分類樣本距離最近的K個(gè)已分類樣本,作為待分類樣本的近鄰;
3. 做分類:根據(jù)這K個(gè)近鄰中的大部分樣本所屬的類別來(lái)決定待分類樣本該屬于哪個(gè)分類;
python示例
import math
import csv
import operator
import random
import numpy as np
from sklearn.datasets import make_blobs
#Python version 3.6.5
# 生成樣本數(shù)據(jù)集 samples(樣本數(shù)量) features(特征向量的維度) centers(類別個(gè)數(shù))
def createDataSet(samples=100, features=2, centers=2):
return make_blobs(n_samples=samples, n_features=features, centers=centers, cluster_std=1.0, random_state=8)
# 加載鳶尾花卉數(shù)據(jù)集 filename(數(shù)據(jù)集文件存放路徑)
def loadIrisDataset(filename):
with open(filename, 'rt') as csvfile:
lines = csv.reader(csvfile)
dataset = list(lines)
for x in range(len(dataset)):
for y in range(4):
dataset[x][y] = float(dataset[x][y])
return dataset
# 拆分?jǐn)?shù)據(jù)集 dataset(要拆分的數(shù)據(jù)集) split(訓(xùn)練集所占比例) trainingSet(訓(xùn)練集) testSet(測(cè)試集)
def splitDataSet(dataSet, split, trainingSet=[], testSet=[]):
for x in range(len(dataSet)):
if random.random() <= split:
trainingSet.append(dataSet[x])
else:
testSet.append(dataSet[x])
# 計(jì)算歐氏距離
def euclideanDistance(instance1, instance2, length):
distance = 0
for x in range(length):
distance += pow((instance1[x] - instance2[x]), 2)
return math.sqrt(distance)
# 選取距離最近的K個(gè)實(shí)例
def getNeighbors(trainingSet, testInstance, k):
distances = []
length = len(testInstance) - 1
for x in range(len(trainingSet)):
dist = euclideanDistance(testInstance, trainingSet[x], length)
distances.append((trainingSet[x], dist))
distances.sort(key=operator.itemgetter(1))
neighbors = []
for x in range(k):
neighbors.append(distances[x][0])
return neighbors
# 獲取距離最近的K個(gè)實(shí)例中占比例較大的分類
def getResponse(neighbors):
classVotes = {}
for x in range(len(neighbors)):
response = neighbors[x][-1]
if response in classVotes:
classVotes[response] += 1
else:
classVotes[response] = 1
sortedVotes = sorted(classVotes.items(), key=operator.itemgetter(1), reverse=True)
return sortedVotes[0][0]
# 計(jì)算準(zhǔn)確率
def getAccuracy(testSet, predictions):
correct = 0
for x in range(len(testSet)):
if testSet[x][-1] == predictions[x]:
correct += 1
return (correct / float(len(testSet))) * 100.0
def main():
# 使用自定義創(chuàng)建的數(shù)據(jù)集進(jìn)行分類
# x,y = createDataSet(features=2)
# dataSet= np.c_[x,y]
# 使用鳶尾花卉數(shù)據(jù)集進(jìn)行分類
dataSet = loadIrisDataset(r'C:\DevTolls\eclipse-pureh2b\python\DeepLearning\KNN\iris_dataset.txt')
print(dataSet)
trainingSet = []
testSet = []
splitDataSet(dataSet, 0.75, trainingSet, testSet)
print('Train set:' + repr(len(trainingSet)))
print('Test set:' + repr(len(testSet)))
predictions = []
k = 7
for x in range(len(testSet)):
neighbors = getNeighbors(trainingSet, testSet[x], k)
result = getResponse(neighbors)
predictions.append(result)
print('>predicted=' + repr(result) + ',actual=' + repr(testSet[x][-1]))
accuracy = getAccuracy(testSet, predictions)
print('Accuracy: ' + repr(accuracy) + '%')
main()
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試�,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材���,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫(kù)��,點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情��;
? 想了解CDA考試含金量���,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330