最近小編了解到了一個的概念: FP-growth�,廢話就不多說了,直接把整理的FP-growth的干貨分享給大家����。
一、FP-growth是什么
FP-Growth(頻繁模式增長)算法是由韓家煒老師在2000年提出的關(guān)聯(lián)分析算法�����,它的分治策略為:將提供頻繁項集的數(shù)據(jù)庫壓縮到一棵頻繁模式樹(FP-Tree)����,但仍保留項集關(guān)聯(lián)信息。
FP-growth算法通常被用來挖掘頻繁項集�����,即從已給的多條數(shù)據(jù)記錄中�����,挖掘出哪些項是頻繁一起出現(xiàn)的��。這種算法算法適用于標稱型數(shù)據(jù)���,也就是離散型數(shù)據(jù)�。其實我們經(jīng)常能接觸到FP-growth算法,就比如�,我們在百度的搜索框內(nèi)輸入某個字或者詞,搜索引擎就會會自動補全查詢詞項�,往往這些詞項都是與搜索詞經(jīng)常一同出現(xiàn)的。
FP-growth算法源于Apriori的��,是通過將數(shù)據(jù)集存儲在FP(Frequent Pattern)樹上發(fā)現(xiàn)頻繁項集��,但缺點是�,不能發(fā)現(xiàn)數(shù)據(jù)之間的關(guān)聯(lián)規(guī)則。與Apriori相比�����,F(xiàn)P-growth算法更為高效���,因為FP-growth算法只需要對數(shù)據(jù)庫進行兩次掃描��,而Apriori算法在求每個潛在的頻繁項集時都需要掃描一次數(shù)據(jù)集�。
二���、FP-Tree算法基本結(jié)構(gòu)
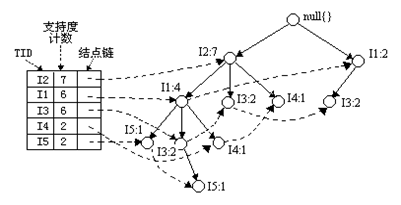
FPTree算法的基本數(shù)據(jù)結(jié)構(gòu)��,包含一個一棵FP樹和一個項頭表���,每個項通過一個結(jié)點鏈指向它在樹中出現(xiàn)的位置���?���;窘Y(jié)構(gòu)如下所示。需要注意的是項頭表需要按照支持度遞減排序�,在FPTree中高支持度的節(jié)點只能是低支持度節(jié)點的祖先節(jié)點。
FP-Tree:即上面的那棵樹����,是把事務(wù)數(shù)據(jù)表中的各個事務(wù)數(shù)據(jù)項按照支持度排序后,把每個事務(wù)中的數(shù)據(jù)項按降序依次插入到一棵以NULL為根結(jié)點的樹中�,同時在每個結(jié)點處記錄該結(jié)點出現(xiàn)的支持度。
條件模式基:包含F(xiàn)P-Tree中與后綴模式一起出現(xiàn)的前綴路徑的集合�。即同一個頻繁項在PF樹中的所有節(jié)點的祖先路徑的集合。例如I3在FP樹中總共出現(xiàn)了3次���,其祖先路徑分別是{I2.I1:2(頻度為2)}�����,{I2:2}和{I1:2}���。這3個祖先路徑的集合就是頻繁項I3的條件模式基����。
條件樹:將條件模式基按照FP-Tree的構(gòu)造原則形成的一個新的FP-Tree���。比如上圖中I3的條件樹就是����。
三����、FP-growth算法
FP-growth算法挖掘頻繁項集的基本過程分為兩步:
(1)構(gòu)建FP樹。
首先構(gòu)造FP樹��,然后利用它來挖掘頻繁項集��。在構(gòu)造FP樹時����,需要對數(shù)據(jù)集掃描兩邊,第一遍掃描用來統(tǒng)計頻率�����,第二遍掃描至考慮頻繁項集。
(2)從FP樹中挖掘頻繁項集�����。
首先���,獲取條件模式基。條件模式基是以所查找元素項為結(jié)尾的路徑集合����,表示的是所查找的元素項與樹根節(jié)點之間的所有內(nèi)容。
其次�,構(gòu)建條件模式基。對于每一個頻繁項�����,都需要創(chuàng)建一棵條件FP樹��,使用創(chuàng)建的條件模式基作為輸入�,采用相同的建樹代碼來構(gòu)建樹,相應(yīng)的遞歸發(fā)現(xiàn)頻繁項�����、發(fā)現(xiàn)條件模式基和另外的條件樹。
四��、python代碼實現(xiàn)
class treeNode:
def __init__(self, nameValue, numOccur, parentNode):
self.name = nameValue
self.count = numOccur
self.nodeLink = None
self.parent = parentNode
self.children = {}
def inc(self, numOccur):
self.count += numOccur
def disp(self, ind=1):
print ' '*ind, self.name, ' ', self.count
for child in self.children.values():
child.disp(ind+1)
def updateHeader(nodeToTest, targetNode):
while nodeToTest.nodeLink != None:
nodeToTest = nodeToTest.nodeLink
nodeToTest.nodeLink = targetNode
def updateFPtree(items, inTree, headerTable, count):
if items[0] in inTree.children:
# 判斷items的第一個結(jié)點是否已作為子結(jié)點
inTree.children[items[0]].inc(count)
else:
# 創(chuàng)建新的分支
inTree.children[items[0]] = treeNode(items[0], count, inTree)
# 更新相應(yīng)頻繁項集的鏈表�����,往后添加
if headerTable[items[0]][1] == None:
headerTable[items[0]][1] = inTree.children[items[0]]
else:
updateHeader(headerTable[items[0]][1], inTree.children[items[0]])
# 遞歸
if len(items) > 1:
updateFPtree(items[1::], inTree.children[items[0]], headerTable, count)
def createFPtree(dataSet, minSup=1):
headerTable = {}
for trans in dataSet:
for item in trans:
headerTable[item] = headerTable.get(item, 0) + dataSet[trans]
for k in headerTable.keys():
if headerTable[k] < minSup:
del(headerTable[k]) # 刪除不滿足最小支持度的元素
freqItemSet = set(headerTable.keys()) # 滿足最小支持度的頻繁項集
if len(freqItemSet) == 0:
return None, None
for k in headerTable:
headerTable[k] = [headerTable[k], None] # element: [count, node]
retTree = treeNode('Null Set', 1, None)
for tranSet, count in dataSet.items():
# dataSet:[element, count]
localD = {}
for item in tranSet:
if item in freqItemSet: # 過濾�,只取該樣本中滿足最小支持度的頻繁項
localD[item] = headerTable[item][0] # element : count
if len(localD) > 0:
# 根據(jù)全局頻數(shù)從大到小對單樣本排序
orderedItem = [v[0] for v in sorted(localD.items(), key=lambda p:p[1], reverse=True)]
# 用過濾且排序后的樣本更新樹
updateFPtree(orderedItem, retTree, headerTable, count)
return retTree, headerTable
def loadSimpDat():
simDat = [['r','z','h','j','p'],
['z','y','x','w','v','u','t','s'],
['z'],
['r','x','n','o','s'],
['y','r','x','z','q','t','p'],
['y','z','x','e','q','s','t','m']]
return simDat
# 構(gòu)造成 element : count 的形式
def createInitSet(dataSet):
retDict={}
for trans in dataSet:
key = frozenset(trans)
if retDict.has_key(key):
retDict[frozenset(trans)] += 1
else:
retDict[frozenset(trans)] = 1
return retDict
# 數(shù)據(jù)集
def loadSimpDat():
simDat = [['r','z','h','j','p'],
['z','y','x','w','v','u','t','s'],
['z'],
['r','x','n','o','s'],
['y','r','x','z','q','t','p'],
['y','z','x','e','q','s','t','m']]
return simDat
# 構(gòu)造成 element : count 的形式
def createInitSet(dataSet):
retDict={}
for trans in dataSet:
key = frozenset(trans)
if retDict.has_key(key):
retDict[frozenset(trans)] += 1
else:
retDict[frozenset(trans)] = 1
return retDict
# 遞歸回溯
def ascendFPtree(leafNode, prefixPath):
if leafNode.parent != None:
prefixPath.append(leafNode.name)
ascendFPtree(leafNode.parent, prefixPath)
# 條件模式基
def findPrefixPath(basePat, myHeaderTab):
treeNode = myHeaderTab[basePat][1] # basePat在FP樹中的第一個結(jié)點
condPats = {}
while treeNode != None:
prefixPath = []
ascendFPtree(treeNode, prefixPath) # prefixPath是倒過來的,從treeNode開始到根
if len(prefixPath) > 1:
condPats[frozenset(prefixPath[1:])] = treeNode.count # 關(guān)聯(lián)treeNode的計數(shù)
treeNode = treeNode.nodeLink # 下一個basePat結(jié)點
return condPats
def mineFPtree(inTree, headerTable, minSup, preFix, freqItemList):
# 最開始的頻繁項集是headerTable中的各元素
bigL = [v[0] for v in sorted(headerTable.items(), key=lambda p:p[1])] # 根據(jù)頻繁項的總頻次排序
for basePat in bigL: # 對每個頻繁項
newFreqSet = preFix.copy()
newFreqSet.add(basePat)
freqItemList.append(newFreqSet)
condPattBases = findPrefixPath(basePat, headerTable) # 當前頻繁項集的條件模式基
myCondTree, myHead = createFPtree(condPattBases, minSup) # 構(gòu)造當前頻繁項的條件FP樹
if myHead != None:
# print 'conditional tree for: ', newFreqSet
# myCondTree.disp(1)
mineFPtree(myCondTree, myHead, minSup, newFreqSet, freqItemList) # 遞歸挖掘條件FP樹
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330