大數(shù)據(jù)處理時(shí)我們經(jīng)常會(huì)遇到數(shù)據(jù)傾斜的問題���,尤其是在數(shù)據(jù)量過大時(shí)�����,數(shù)據(jù)傾斜可能會(huì)導(dǎo)致各種各樣的問題�。Hadoop數(shù)據(jù)傾斜主要表現(xiàn)為:ruduce階段卡在99.99%���,而且是一直99.99%不能結(jié)束���。
具體來說就是:mapreduce程序執(zhí)行時(shí),reduce節(jié)點(diǎn)大部分已經(jīng)執(zhí)行完畢���,但是其中會(huì)有一個(gè)或者幾個(gè)reduce節(jié)點(diǎn)運(yùn)行速度很慢���,從而使得整個(gè)程序的處理時(shí)間很長�。原因是:某一個(gè)key的條數(shù)比其他key多出太多�,因此這條key所在的reduce節(jié)點(diǎn)所處理的數(shù)據(jù)量就比其他節(jié)點(diǎn)就大很多,這也就造成了某幾個(gè)節(jié)點(diǎn)遲遲運(yùn)行不完����。由于Hive是分階段執(zhí)行的,map處理數(shù)據(jù)量的差異���,取決于上一個(gè)stage的reduce輸出�����,因此將數(shù)據(jù)均勻的分配到各個(gè)reduce中���,這一點(diǎn)是解決數(shù)據(jù)傾斜的關(guān)鍵。
一�����、Hadoop數(shù)據(jù)傾斜常見情形
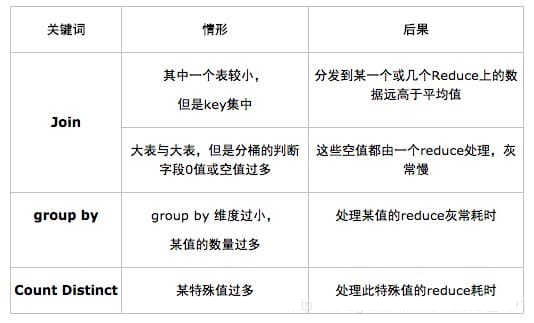
二�、Hadoop數(shù)據(jù)傾斜產(chǎn)生原因
1.Hadoop框架的特性
A、Hadoop不怕數(shù)據(jù)大��,但是怕數(shù)據(jù)傾斜
B、Jobs 數(shù)多的作業(yè)運(yùn)行效率會(huì)相對(duì)比較低
C�、countdistinct、group by��、join等操作�����,觸發(fā)了Shuffle動(dòng)作����,導(dǎo)致全部相同key的值聚集在一個(gè)或幾個(gè)節(jié)點(diǎn)上���,很容易發(fā)生單點(diǎn)問題����。
2.具體原因
A:key 分布不均勻�,某一個(gè)key的條數(shù)比其他key多太多
B:業(yè)務(wù)數(shù)據(jù)自帶的特性
C:建表時(shí)考慮不全面
D:可能某些 HQL 語句自身就存在數(shù)據(jù)傾斜 問題
三、Hadoop數(shù)據(jù)傾斜處理
1�����、從業(yè)務(wù)和數(shù)據(jù)方面解決數(shù)據(jù)傾斜
(1)有損的方法:找到異常數(shù)據(jù)��。
(2)無損的方法:
對(duì)分布不均勻的數(shù)據(jù),進(jìn)行單獨(dú)計(jì)算
首先對(duì)key做一層hash����,把數(shù)據(jù)打散,讓它的并行度變大��,之后進(jìn)行匯集
(3)數(shù)據(jù)預(yù)處理
2�����、Hadoop平臺(tái)的解決方法
(1)針對(duì)join產(chǎn)生的數(shù)據(jù)傾斜
A.大表和小表join產(chǎn)生的數(shù)據(jù)傾斜
a.在多表關(guān)聯(lián)情況下���,將小表(關(guān)聯(lián)鍵記錄少的表)依次放到前面�����,這樣能夠觸發(fā)reduce端減少操作次數(shù)�,從而減少運(yùn)行時(shí)間����。
b.同時(shí)使用Map Join讓小表緩存到內(nèi)存。在map端完成join過程���,這樣就能省掉redcue端的工作�。需要注意:這一功能使用時(shí),需要開啟map-side join的設(shè)置屬性:set hive.auto.convert.join=true(默認(rèn)是false)
還可以對(duì)使用這個(gè)優(yōu)化的小表的大小進(jìn)行設(shè)置:set hive.mapjoin.smalltable.filesize=25000000(默認(rèn)值25M)
B.大表和大表的join產(chǎn)生的數(shù)據(jù)傾斜
a.j將異常值賦一個(gè)隨機(jī)值�,以此來分散key,均勻分配給多個(gè)reduce去執(zhí)行
b.如果key值都是有效值的情況下,需要設(shè)置以下幾個(gè)參數(shù)來解決
set hive.exec.reducers.bytes.per.reducer = 1000000000
也就是每個(gè)節(jié)點(diǎn)的reduce��,其 默認(rèn)是處理數(shù)據(jù)地大小為1G��,如果join 操作也產(chǎn)生了數(shù)據(jù)傾斜��,那么就在hive 中設(shè)定
set hive.optimize.skewjoin = true;
set hive.skewjoin.key = skew_key_threshold (default = 100000)
(2)group by 造成的數(shù)據(jù)傾斜
解決方式相對(duì)簡單:
hive.map.aggr=true (默認(rèn)true) 這個(gè)配置項(xiàng)代表是否在map端進(jìn)行聚合����,相當(dāng)于Combiner
hive.groupby.skewindata
(3)count(distinct)或者其他參數(shù)不當(dāng)造成的數(shù)據(jù)傾斜
A.reduce個(gè)數(shù)太少
set mapred.reduce.tasks=800
B.HiveQL中包含count(distinct)時(shí)
使用sum...group byl來替代��。例如select a,sum(1) from (select a, b from t group by a,b) group by a;
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試��,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情����;
? 想學(xué)習(xí)CDA考試教材,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營許可證編號(hào):京B2-20210330