在數(shù)據(jù)分析過程中���,我們會用到各種各樣的數(shù)據(jù)模型��。但有些模型并不是完美的�����,存在者各種各樣的缺點����,置之不理很可能會影響最終的數(shù)據(jù)分析結果。這也就意味著�,我們需要讓模型最優(yōu)化。通過模型優(yōu)化���,訓練出更好的模型,更好的進行數(shù)據(jù)分析��。下面���,小編簡單整理了幾種常用的模型優(yōu)化方法����,希望對大家有所幫助�。
1. 梯度下降法(Gradient Descent)
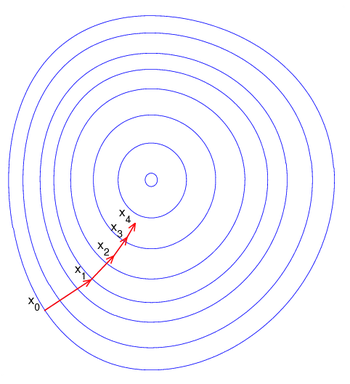
梯度下降法——最早的���、最容易,同時也是最長用到的模型優(yōu)化方法�。
梯度下降法實現(xiàn)很容易,在目標函數(shù)為凸函數(shù)的情況下��,梯度下降法的解就是全局解�。通常來說,其解是全局最優(yōu)解這一點并不能保證��,而且梯度下降法�,它的速度也并不是最快的。梯度下降法的優(yōu)化思想為:把當前位置負梯度的方向當做搜索方向��,這是該這一方向是當前位置的最快下降方向��,所以又有”最速下降法“的叫法����。梯度下降法越是接近目標值,其步長就會越小�����,前進也會越慢����。
2. 牛頓法和擬牛頓法
a.牛頓法(Newton's method)
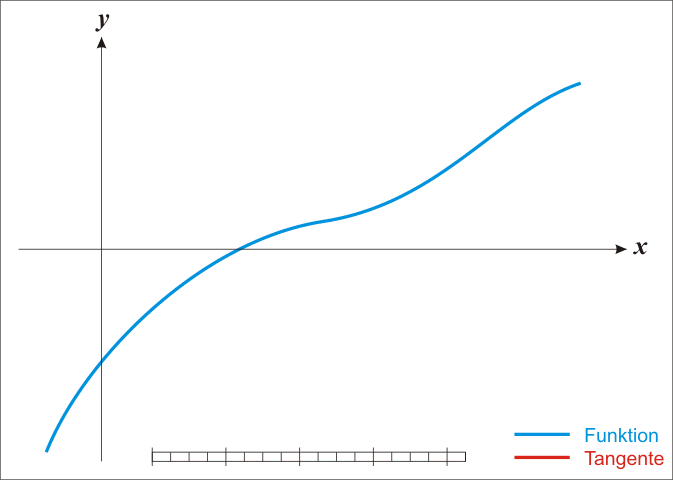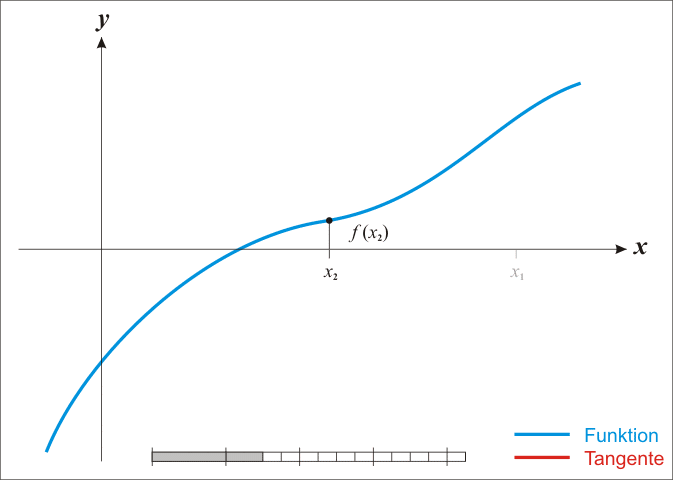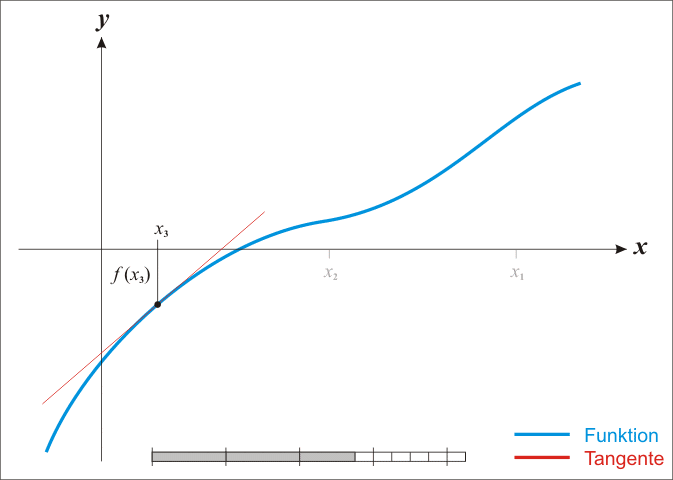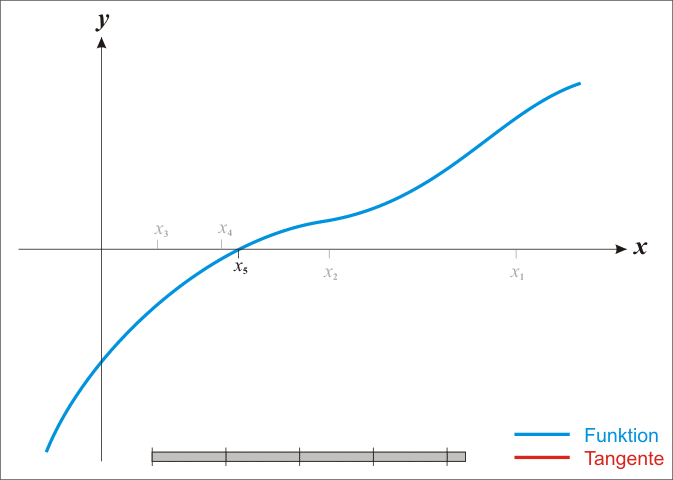
牛頓法其實是一種在實數(shù)域和復數(shù)域上�,近似求解方程的方法����。此方法使用f (x)函數(shù)的泰勒級數(shù)里的前面幾項來找尋方程f (x) = 0的根。收斂速度快是此方法最大的特點�����。
因為牛頓法是確定下一次的位置依靠的是當前位置的切線����,所以又有"切線法"這一很形象的名稱。
b.擬牛頓法(Quasi-Newton Methods)
擬牛頓法可以說是非線性優(yōu)化問題求解最常用的��、最有效的方法了����。擬牛頓法是20世紀50年代�,由美國Argonne國家實驗室的物理學家W.C.Davidon提出的·,這一算法在當時的時代�����,無疑是非線性優(yōu)化領域最具有創(chuàng)造性的發(fā)明之一了。
擬牛頓法的本質(zhì)思想為:對牛頓法每次需要求解復雜的Hessian矩陣的逆矩陣這一缺陷進行改善����。擬牛頓法使用正定矩陣來近似Hessian矩陣的逆,這樣在很大程度上減小了運算的復雜度��。擬牛頓法與梯度下降法相同�,只對每一步迭代時知道目標函數(shù)的梯度有要求。通過測量梯度的變化����,構造出一個目標函數(shù)的模型,并使之足以產(chǎn)生超線性收斂性����。而且相比牛頓法,擬牛頓法并不需要二階導數(shù)的信息���,所以有時反而比牛頓法更有效��。
3. 共軛梯度法(Conjugate Gradient)
共軛梯度法是介于梯度下降法與牛頓法之間的一個模型優(yōu)化方法���,只需要利用一階導數(shù)信息,但卻改善了梯度下降法收斂速度慢這一缺陷����,同時又克服了�����,牛頓法需要存儲和計算Hesse矩陣��,并求逆的缺點�����。共軛梯度法既能解決大型線性方程組問題���,又是解大型非線性最優(yōu)化最有用的算法之一。因為共軛梯度法具有所需存儲量小��,步收斂性���,高穩(wěn)定性��,不需要任何外來參數(shù)的優(yōu)點��,在各種模型優(yōu)化方法中���,是極為重要的一種。
4. 啟發(fā)式優(yōu)化方法
啟發(fā)式優(yōu)化方法指的是:人在解決問題時����,所采取的一種根據(jù)經(jīng)驗規(guī)則進行發(fā)現(xiàn)的方法。這一方法特點是�����,當解決問題時,可以利用過去的經(jīng)驗,選擇行之有效的方法�����,而并不是以系統(tǒng)的�����、確定的步驟去找尋答案�。啟發(fā)式優(yōu)化方法有很多種類,其中最為經(jīng)典的有:模擬退火方法����、遺傳算法、蟻群算法以及粒子群算法等等����。
CDA數(shù)據(jù)分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330