作者:肖冠宇
來源:大數(shù)據(jù)DT(ID:hzdashuju)
內(nèi)容摘編自《企業(yè)大數(shù)據(jù)處理:Spark����、Druid��、Flume與Kafka應(yīng)用實踐》
導讀:Spark是由加州大學伯克利分校AMP實驗室開源的分布式大規(guī)模數(shù)據(jù)處理通用引擎�����,具有高吞吐��、低延時、通用易擴展��、高容錯等特點����。Spark內(nèi)部提供了豐富的開發(fā)庫,集成了數(shù)據(jù)分析引擎Spark SQL���、圖計算框架GraphX��、機器學習庫MLlib���、流計算引擎Spark Streaming�。
Spark在函數(shù)式編程語言Scala中實現(xiàn)�,提供了豐富的開發(fā)API,支持Scala����、Java、Python�、R等多種開發(fā)語言。同時���,Spark提供了多種運行模式��,既可以采用獨立部署的方式運行�����,也可以依托Hadoop YARN����、Apache Mesos等資源管理器調(diào)度任務(wù)運行���。
目前��,Spark已經(jīng)在金融�、交通、醫(yī)療�����、氣象等多種領(lǐng)域中廣泛使用���。

01 Spark概述
1. 核心概念介紹
Spark架構(gòu)示意圖如圖2-1所示�����,下面將分別介紹各核心組件����。
Client:客戶端進程��,負責提交作業(yè)���。
Driver:一個Spark作業(yè)有一個Spark Context,一個Spark Context對應(yīng)一個Driver進程�����,作業(yè)的main函數(shù)運行在Driver中。Driver主要負責Spark作業(yè)的解析�,以及通過DAGScheduler劃分Stage,將Stage轉(zhuǎn)化成TaskSet提交給TaskScheduler任務(wù)調(diào)度器���,進而調(diào)度Task到Executor上執(zhí)行�����。
Executor:負責執(zhí)行Driver分發(fā)的Task任務(wù)���。集群中一個節(jié)點可以啟動多個Executor,每一個Executor可以執(zhí)行多個Task任務(wù)�����。
Catche:Spark提供了對RDD不同級別的緩存策略��,分別可以緩存到內(nèi)存�、磁盤、外部分布式內(nèi)存存儲系統(tǒng)Tachyon等�����。
Application:提交的一個作業(yè)就是一個Application,一個Application只有一個Spark Context����。
Job:RDD執(zhí)行一次Action操作就會生成一個Job。
Task:Spark運行的基本單位����,負責處理RDD的計算邏輯。
Stage:DAGScheduler將Job劃分為多個Stage���,Stage的劃分界限為Shuffle的產(chǎn)生���,Shuffle標志著上一個Stage的結(jié)束和下一個Stage的開始。
TaskSet:劃分的Stage會轉(zhuǎn)換成一組相關(guān)聯(lián)的任務(wù)集�����。
RDD(Resilient Distributed Dataset):彈性分布式數(shù)據(jù)集���,可以理解為一種只讀的分布式多分區(qū)的數(shù)組��,Spark計算操作都是基于RDD進行的,下面會有詳細介紹���。
DAG(Directed Acyclic Graph):有向無環(huán)圖�����。Spark實現(xiàn)了DAG的計算模型��,DAG計算模型是指將一個計算任務(wù)按照計算規(guī)則分解為若干子任務(wù)���,這些子任務(wù)之間根據(jù)邏輯關(guān)系構(gòu)建成有向無環(huán)圖����。
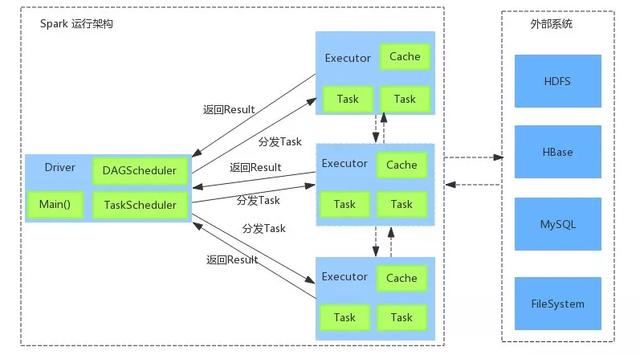
▲圖2-1 Spark架構(gòu)示意圖
2. RDD介紹
RDD從字面上理解有些困難�����,我們可以認為是一種分布式多分區(qū)只讀的數(shù)組��,Spark計算操作都是基于RDD進行的��。
RDD具有幾個特性:只讀�、多分區(qū)、分布式�����,可以將HDFS塊文件轉(zhuǎn)換成RDD,也可以由一個或多個RDD轉(zhuǎn)換成新的RDD��,失效自動重構(gòu)����。基于這些特性�����,RDD在分布式環(huán)境下能夠被高效地并行處理����。
(1)計算類型
在Spark中RDD提供Transformation和Action兩種計算類型。Transformation操作非常豐富�����,采用延遲執(zhí)行的方式���,在邏輯上定義了RDD的依賴關(guān)系和計算邏輯����,但并不會真正觸發(fā)執(zhí)行動作,只有等到Action操作才會觸發(fā)真正執(zhí)行操作����。Action操作常用于最終結(jié)果的輸出����。
常用的Transformation操作及其描述:
map (func):接收一個處理函數(shù)并行處理源RDD中的每個元素,返回與源RDD元素一一對應(yīng)的新RDD
filter (func):并行處理源RDD中的每個元素�,接收一個處理函數(shù),并根據(jù)定義的規(guī)則對RDD中的每個元素進行過濾處理��,返回處理結(jié)果為true的元素重新組成新的RDD
flatMap (func):flatMap是map和flatten的組合操作�����,與map函數(shù)相似��,不過map函數(shù)返回的新RDD包含的元素可能是嵌套類型����,flatMap接收一個處理嵌套會將嵌套類型的元素展開映射成多個元素組成新的RDD
mapPartitions (func):與map函數(shù)應(yīng)用于RDD中的每個元素不同,mapPartitions應(yīng)用于RDD中的每個分區(qū)��。mapPartitions函數(shù)接收的參數(shù)為func函數(shù)��,func接收參數(shù)為每個分區(qū)的迭代器,返回值為每個分區(qū)元素處理之后組成的新的迭代器����,func會作用于分區(qū)中的每一個元素。有一種典型的應(yīng)用場景�����,比如待處理分區(qū)中的數(shù)據(jù)需要寫入到數(shù)據(jù)庫��,如果使用map函數(shù)����,每一個元素都會創(chuàng)建一個數(shù)據(jù)庫連接對象,非常耗時并且容易引起問題發(fā)生����,如果使用mapPartitions函數(shù)只會在分區(qū)中創(chuàng)建一個數(shù)據(jù)庫連接對象,性能提高明顯
mapPartitionsWithIndex(func):作用與mapPartitions函數(shù)相同����,只是接收的參數(shù)func函數(shù)需要傳入兩個參數(shù),分區(qū)的索引作為第一個參數(shù)傳入����,按照分區(qū)的索引對分區(qū)中元素進行處理
union (otherDataset):將兩個RDD進行合并���,返回結(jié)果為RDD中元素(不去重)
intersection (otherDataset):對兩個RDD進行取交集運算,返回結(jié)果為RDD無重復元素
distinct ([numTasks])):對RDD中元素去重
groupByKey ([numTasks]):在KV類型的RDD中按Key分組����,將相同Key的元素聚集到同一個分區(qū)內(nèi),此函數(shù)不能接收函數(shù)作為參數(shù)��,只接收一個可選參數(shù)任務(wù)數(shù)��,所以不能在RDD分區(qū)本地進行聚合計算�,如需按Key對Value聚合計算����,只能對groupByKey返回的新RDD繼續(xù)使用其他函數(shù)運算
reduceByKey (func, [numTasks]):對KV類型的RDD按Key分組,接收兩個參數(shù)����,第一個參數(shù)為處理函數(shù),第二個參數(shù)為可選參數(shù)設(shè)置reduce的任務(wù)數(shù)����。reduceByKey函數(shù)能夠在RDD分區(qū)本地提前進行聚合運算,這有效減少了shuffle過程傳輸?shù)臄?shù)據(jù)量�����。相對于groupByKey函數(shù)更簡潔高效
aggregateByKey (zeroValue)(seqOp, combOp):對KV類型的RDD按Key分組進行reduce計算,可接收三個參數(shù)����,第一個參數(shù)是初始化值,第二個參數(shù)是分區(qū)內(nèi)處理函數(shù)����,第三個參數(shù)是分區(qū)間處理函數(shù)
sortByKey ([ascending], [numTasks]):對KV類型的RDD內(nèi)部元素按照Key進行排序,排序過程會涉及Shuffle
join (otherDataset, [numTasks]):對KV類型的RDD進行關(guān)聯(lián)���,只能是兩個RDD之間關(guān)聯(lián)����,超過兩個RDD關(guān)聯(lián)需要使用多次join函數(shù)����,join函數(shù)只會關(guān)聯(lián)出具有相同Key的元素,相當于SQL語句中的inner join
cogroup (otherDataset, [numTasks]):對KV類型的RDD進行關(guān)聯(lián)�����,cogroup處理多個RDD關(guān)聯(lián)比join更加優(yōu)雅���,它可以同時傳入多個RDD作為參數(shù)進行關(guān)聯(lián)����,產(chǎn)生的新RDD中的元素不會出現(xiàn)笛卡爾積的情況,使用fullOuterJoin函數(shù)會產(chǎn)生笛卡爾積
coalesce (numPartitions):對RDD重新分區(qū)��,將RDD中的分區(qū)數(shù)減小到參數(shù)numPartitions個�����,不會產(chǎn)生shuffle�����。在較大的數(shù)據(jù)集中使用filer等過濾操作后可能會產(chǎn)生多個大小不等的中間結(jié)果數(shù)據(jù)文件��,重新分區(qū)并減小分區(qū)可以提高作業(yè)的執(zhí)行效率���,是Spark中常用的一種優(yōu)化手段
repartition (numPartitions):對RDD重新分區(qū),接收一個參數(shù)——numPartitions分區(qū)數(shù)����,是coalesce函數(shù)設(shè)置shuffle為true的一種實現(xiàn)形式
repartitionAndSortWithinPartitions (partitioner):接收一個分區(qū)對象(如Spark提供的分區(qū)類HashPartitioner)對RDD中元素重新分區(qū)并在分區(qū)內(nèi)排序
常用的Action操作及其描述:
reduce(func):處理RDD兩兩之間元素的聚集操作
collect():返回RDD中所有數(shù)據(jù)元素
count():返回RDD中元素個數(shù)
first():返回RDD中的第一個元素
take(n):返回RDD中的前n個元素
saveAsTextFile(path):將RDD寫入文本文件,保存至本地文件系統(tǒng)或者HDFS中
saveAsSequenceFile(path):將KV類型的RDD寫入SequenceFile文件����,保存至本地文件系統(tǒng)或者HDFS中
countByKey():返回KV類型的RDD每個Key包含的元素個數(shù)
foreach(func):遍歷RDD中所有元素���,接收參數(shù)為func函數(shù),常用操作是傳入println函數(shù)打印所有元素
從HDFS文件生成Spark RDD�����,經(jīng)過map����、filter、join等多次Transformation操作���,最終調(diào)用saveAsTextFile Action操作將結(jié)果集輸出到HDFS��,并以文件形式保存�����。RDD的流轉(zhuǎn)過程如圖2-2所示��。
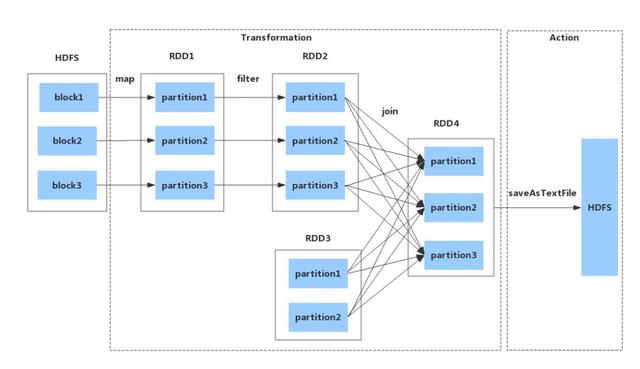
▲圖2-2 RDD的流轉(zhuǎn)過程示意圖
(2)緩存
在Spark中RDD可以緩存到內(nèi)存或者磁盤上��,提供緩存的主要目的是減少同一數(shù)據(jù)集被多次使用的網(wǎng)絡(luò)傳輸次數(shù)����,提高Spark的計算性能。Spark提供對RDD的多種緩存級別��,可以滿足不同場景對RDD的使用需求�����。RDD的緩存具有容錯性���,如果有分區(qū)丟失���,可以通過系統(tǒng)自動重新計算。
在代碼中可以使用persist()方法或cache()方法緩存RDD�。cache()方法默認將RDD緩存到內(nèi)存中�,cache()方法和persist()方法都可以用unpersist()方法來取消RDD緩存。示例如下:
val fileDataRdd = sc.textFile("hdfs://data/hadoop/test.text")
fileDataRdd.cache() // 緩存RDD到內(nèi)存
或者
fileDataRdd.persist(StorageLevel.MEMORY_ONLY)
fileDataRdd..unpersist() // 取消緩存
Spark的所有緩存級別定義在org.apache.spark.storage.StorageLevel對象中��,如下所示��。
object storageLevel extends scala.AnyRef with scala.Serializable {
val NONE : org.apache.spark.storage.StorageLevel
val DISK_ONLY : org.apache.spark.storage.StorageLevel
val DISK_ONLY_2 : org.apache.spark.storage.StorageLevel
val MEMORY_ONLY : org.apache.spark.storage.StorageLevel
val MEMORY_ONLY_2 : org.apache.spark.storage.StorageLevel
val MEMORY_ONLY_SER : org.apache.spark.storage.StorageLevel
val MEMORY_ONLY_SER_2 : org.apache.spark.storage.StorageLevel
val MEMORY_AND_DISK : org.apache.spark.storage.StorageLevel
val MEMORY_AND_DISK_2 : org.apache.spark.storage.StorageLevel
val MEMORY_AND_DISK_SER : org.apache.spark.storage.StorageLevel
val MEMORY_AND_DISK_SER_2 : org.apache.spark.storage.StorageLevel
val OFF_HEAP : org.apache.spark.storage.StorageLevel
Spark各緩存級別及其描述:
MEMORY_ONLY:RDD僅緩存一份到內(nèi)存��,此為默認級別
MEMORY_ONLY_2:將RDD分別緩存在集群的兩個節(jié)點上���,RDD在集群內(nèi)存中保存兩份
MEMORY_ONLY_SER:將RDD以Java序列化對象的方式緩存到內(nèi)存中���,有效減少了RDD在內(nèi)存中占用的空間���,不過讀取時會消耗更多的CPU資源
DISK_ONLY:RDD僅緩存一份到磁盤
MEMORY_AND_DISK:RDD僅緩存一份到內(nèi)存,當內(nèi)存中空間不足時會將部分RDD分區(qū)緩存到磁盤
MEMORY_AND_DISK_2:將RDD分別緩存在集群的兩個節(jié)點上�,當內(nèi)存中空間不足時會將部分RDD分區(qū)緩存到磁盤,RDD在集群內(nèi)存中保存兩份
MEMORY_AND_DISK_SER:將RDD以Java序列化對象的方式緩存到內(nèi)存中����,當內(nèi)存中空間不足時會將部分RDD分區(qū)緩存到磁盤,有效減少了RDD在內(nèi)存中占用的空間�����,不過讀取時會消耗更多的CPU資源
OFF_HEAP:將RDD以序列化的方式緩存到JVM之外的存儲空間Tachyon中����,與其他緩存模式相比,減少了JVM垃圾回收開銷�。Spark執(zhí)行程序失敗不會導致數(shù)據(jù)丟失,Spark與Tachyon已經(jīng)能較好地兼容�����,使用起來方便穩(wěn)定
(3)依賴關(guān)系
窄依賴(Narrow Dependency):父RDD的分區(qū)只對應(yīng)一個子RDD的分區(qū),如圖2-3所示����,如果子RDD只有部分分區(qū)數(shù)據(jù)損壞或者丟失,只需要從對應(yīng)的父RDD重新計算恢復����。
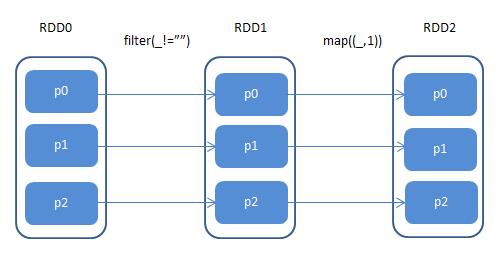
▲圖2-3 窄依賴示意圖
寬依賴(Shuffle Dependency):子RDD分區(qū)依賴父RDD的所有分區(qū),如圖2-4所示�。如果子RDD部分分區(qū)甚至全部分區(qū)數(shù)據(jù)損壞或丟失,需要從所有父RDD重新計算���,相對窄依賴而言付出的代價更高����,所以應(yīng)盡量避免寬依賴的使用���。
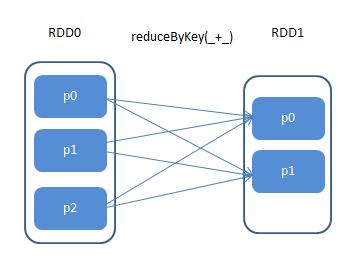
▲圖2-4 寬依賴示意圖
Lineage:每個RDD都會記錄自己依賴的父RDD信息����,一旦出現(xiàn)數(shù)據(jù)損壞或者丟失將從父RDD迅速重新恢復�����。
3. 運行模式
Spark運行模式主要有以下幾種:
Local模式:本地采用多線程的方式執(zhí)行���,主要用于開發(fā)測試�。
On Yarn模式:Spark On Yarn有兩種模式���,分別為yarn-client和yarn-cluster模式�。yarn-client模式中���,Driver運行在客戶端�,其作業(yè)運行日志在客戶端查看��,適合返回小數(shù)據(jù)量結(jié)果集交互式場景使用���。yarn-cluster模式中��,Driver運行在集群中的某個節(jié)點�����,節(jié)點的選擇由YARN調(diào)度����,作業(yè)日志通過yarn管理名稱查看:yarn logs -applicationId,也可以在YARN的Web UI中查看����,適合大數(shù)據(jù)量非交互式場景使用。
提交作業(yè)命令:
./bin/spark-submit --class package.MainClass \ # 作業(yè)執(zhí)行主類�����,需要完成的包路徑
--master spark://host:port, mesos://host:port, yarn, or local\Maste
# 運行方式
---deploy-mode client,cluster\ # 部署模式����,如果Master采用YARN模式則可以選擇使用clent模式或者cluster模式,默認client模式
--driver-memory 1g \ # Driver運行內(nèi)存�����,默認1G
---driver-cores 1 \ # Driver分配的CPU核個數(shù)
--executor-memory 4g \ # Executor內(nèi)存大小
--executor-cores 1 \ # Executor分配的CPU核個數(shù)
---num-executors \ # 作業(yè)執(zhí)行需要啟動的Executor數(shù)
---jars \ # 作業(yè)程序依賴的外部jar包��,這些jar包會從本地上傳到Driver然后分發(fā)到各Executor classpath中�。
lib/spark-examples*.jar \ # 作業(yè)執(zhí)行JAR包
[other application arguments ] # 程序運行需要傳入的參數(shù)
作業(yè)在yarn-cluster模式下的執(zhí)行過程如圖2-5所示。
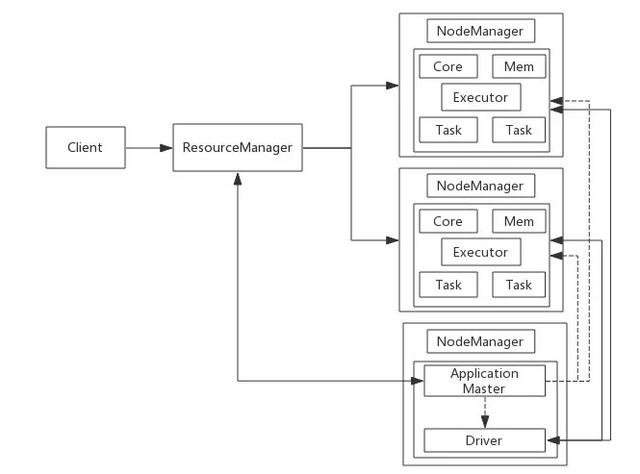
▲圖2-5 作業(yè)在yarn-cluster模式下的執(zhí)行過程
Client在任何一臺能與Yarn通信的入口機向Yarn提交作業(yè)��,提交的配置中可以設(shè)置申請的資源情況����,如果沒有配置則將采用默認配置。
ResourceManager接收到Client的作業(yè)請求后����,首先檢查程序啟動的ApplicationMaster需要的資源情況,然后向資源調(diào)度器申請選取一個能夠滿足資源要求的NodeManager節(jié)點用于啟動ApplicationMaster進程����,ApplicationMaster啟動成功之后立即在該節(jié)點啟動Driver進程。
ApplicationMaster根據(jù)提交作業(yè)時設(shè)置的Executor相關(guān)配置參數(shù)或者默認配置參數(shù)與ResourceManager通信領(lǐng)取Executor資源信息�����,并與相關(guān)NodeManager通信啟動Executor進程���。
Executor啟動成功之后與Driver通信領(lǐng)取Driver分發(fā)的任務(wù)���。
Task執(zhí)行,運行成功輸出結(jié)果����。
02 Shuffle詳解
Shuffle最早出現(xiàn)于MapReduce框架中,負責連接Map階段的輸出與Reduce階段的輸入����。Shuffle階段涉及磁盤IO�����、網(wǎng)絡(luò)傳輸�、內(nèi)存使用等多種資源的調(diào)用����,所以Shuffle階段的執(zhí)行效率影響整個作業(yè)的執(zhí)行效率,大部分優(yōu)化也都是針對Shuffle階段進行的�。
Spark是實現(xiàn)了MapReduce原語的一種通用實時計算框架。Spark作業(yè)中Map階段的Shuffle稱為Shuffle Write���,Reduce階段的Shuffle稱為Shuffle Read�。
Shuffle Write階段會將Map Task中間結(jié)果數(shù)據(jù)寫入到本地磁盤�,而在Shuffle Read階段中,Reduce Task從Shuffle Write階段拉取數(shù)據(jù)到內(nèi)存中并行計算�。Spark Shuffle階段的劃分方式如圖2-6所示。
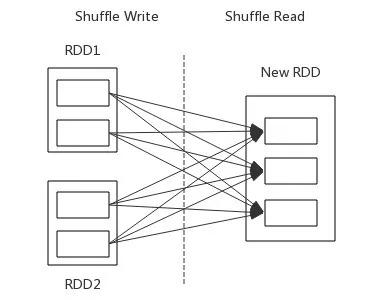
▲圖2-6 Spark Shuffle階段的劃分方式
1. Shuffle Write實現(xiàn)方式
(1)基于Hash的實現(xiàn)(hash-based)
每個Map Task都會生成與Reduce Task數(shù)據(jù)相同的文件數(shù)����,對Key取Hash值分別寫入對應(yīng)的文件中,如圖2-7所示��。
生成的文件數(shù)FileNum=MapTaskNum×ReduceTaskNum,如果Map Task和Reduce Task數(shù)都比較多就會生成大量的小文件��,寫文件過程中��,每個文件都要占用一部分緩沖區(qū)����,總占用緩沖區(qū)大小TotalBufferSize=CoreNum×ReduceTaskNum×FileBufferSize�����,大量的小文件就會占用更多的緩沖區(qū)��,造成不必要的內(nèi)存開銷�,同時,大量的隨機寫操作會大大降低磁盤IO的性能����。
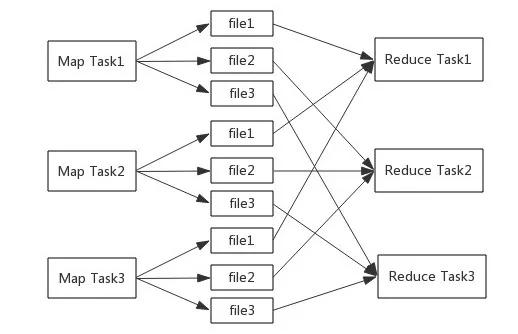
▲圖2-7 基于Hash的實現(xiàn)方式
由于簡單的基于Hash的實現(xiàn)方式擴展性較差,內(nèi)存資源利用率低���,過多的小文件在文件拉取過程中增加了磁盤IO和網(wǎng)絡(luò)開銷�,所以需要對基于Hash的實現(xiàn)方式進行進一步優(yōu)化��,為此引入了Consolidate(合并)機制。
如圖2-8所示��,將同一個Core中執(zhí)行的Task輸出結(jié)果寫入到相同的文件中�,生成的文件數(shù)FileNum=CoreNum×ReduceTaskNum,這種優(yōu)化方式減少了生成的文件數(shù)目���,提高了磁盤IO的吞吐量�,但是文件緩存占用的空間并沒有減少�����,性能沒有得到明顯有效的提高�����。
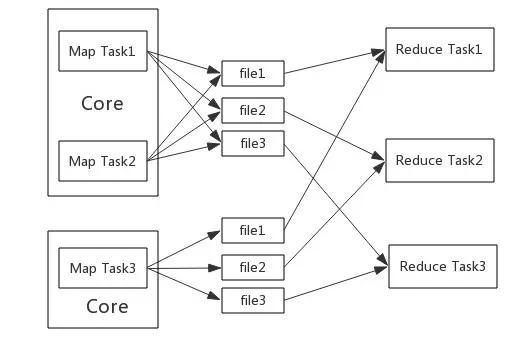
▲圖2-8 優(yōu)化后的基于Hash的實現(xiàn)方式
設(shè)置方式:
代碼中設(shè)置:conf.get("spark.shuffle.manager", "hash")
配置文件中設(shè)置:在conf/spark-default.conf配置文件中添加spark.shuffle.managerhash
基于Hash的實現(xiàn)方式的優(yōu)缺點:
優(yōu)點:實現(xiàn)簡單�,小數(shù)量級數(shù)據(jù)處理操作方便。
缺點:產(chǎn)生小文件過多��,內(nèi)存利用率低�,大量的隨機讀寫造成磁盤IO性能下降。
(2)基于Sort的實現(xiàn)方式(sort-based)
為了解決基于Hash的實現(xiàn)方式的諸多問題��,Spark Shuffle引入了基于Sort的實現(xiàn)方式�����,如圖2-9所示。該方式中每個Map Task任務(wù)生成兩個文件��,一個是數(shù)據(jù)文件���,一個是索引文件��,生成的文件數(shù)FileNum=MapTaskNum×2.
數(shù)據(jù)文件中的數(shù)據(jù)按照Key分區(qū)在不同分區(qū)之間排序,同一分區(qū)中的數(shù)據(jù)不排序��,索引文件記錄了文件中每個分區(qū)的偏移量和范圍�。當Reduce Task讀取數(shù)據(jù)時,先讀取索引文件找到對應(yīng)的分區(qū)數(shù)據(jù)偏移量和范圍��,然后從數(shù)據(jù)文件讀取指定的數(shù)據(jù)�����。
設(shè)置方式:
代碼中設(shè)置:conf.get("spark.shuffle.manager", "sort")
配置文件中設(shè)置:在conf/spark-default.conf配置文件中添加spark.shuffle.manager sort
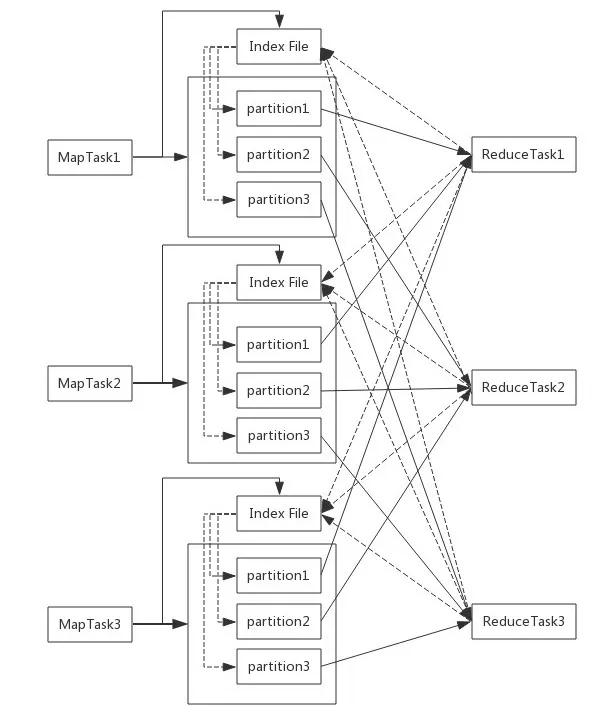
▲圖2-9 基于Sort的實現(xiàn)方式
基于Sort的實現(xiàn)方式的優(yōu)缺點:
優(yōu)點:順序讀寫能夠大幅提高磁盤IO性能����,不會產(chǎn)生過多小文件,降低文件緩存占用內(nèi)存空間大小�,提高內(nèi)存使用率�。
缺點:多了一次粗粒度的排序�。
2. Shuffle Read實現(xiàn)方式
Shuffle Read階段中Task通過直接讀取本地Shuffle Write階段產(chǎn)生的中間結(jié)果數(shù)據(jù)或者通過HTTP的方式從遠程Shuffle Write階段拉取中間結(jié)果數(shù)據(jù)進行處理。Shuffle Write階段基于Hash和基于Sort兩種實現(xiàn)方式產(chǎn)生的中間結(jié)果數(shù)據(jù)在Shuffle Read階段采用同一種實現(xiàn)方式���。
獲取需要拉取的數(shù)據(jù)信息�,根據(jù)數(shù)據(jù)本地性原則判斷采用哪種級別的拉取方式����。
判斷是否需要在Map端聚合(reduceByKey會在Map端預聚合)。
Shuffle Read階段Task拉取過來的數(shù)據(jù)如果涉及聚合或者排序��,則會使用HashMap結(jié)構(gòu)在內(nèi)存中存儲��,如果拉取過來的數(shù)據(jù)集在HashMap中已經(jīng)存在相同的鍵則將數(shù)據(jù)聚合在一起�����。此時涉及一個比較重要的參數(shù)——spark.shuffle.spill���,決定在內(nèi)存被寫滿后是否將數(shù)據(jù)以文件的形式寫入到磁盤�,默認值為true�,如果設(shè)置為false,則有可能會發(fā)生OOM內(nèi)存溢出的風險,建議開啟����。
排序聚合之后的數(shù)據(jù)以文件形式寫入磁盤將產(chǎn)生大量的文件內(nèi)數(shù)據(jù)有序的小文件,將這些小文件重新加載到內(nèi)存中����,隨后采用歸并排序的方式合并為一個大的數(shù)據(jù)文件。
本文摘編自《企業(yè)大數(shù)據(jù)處理:Spark���、Druid�����、Flume與Kafka應(yīng)用實踐》,經(jīng)出版方授權(quán)發(fā)布�����。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330