SPSS科研統(tǒng)計(jì):數(shù)據(jù)的排序��、拆分與合并
通常在進(jìn)行統(tǒng)計(jì)分析之前����,可能要對(duì)數(shù)據(jù)文件進(jìn)行基本的處理操作����,讓數(shù)據(jù)格式更加適合用于將要用到的統(tǒng)計(jì)分析方法。數(shù)據(jù)文件的基本操作主要包括數(shù)據(jù)的排序����、數(shù)據(jù)的分組、數(shù)據(jù)的合并、數(shù)據(jù)的轉(zhuǎn)置��、對(duì)變量值的求秩���、對(duì)變量的編碼����、計(jì)算新變量���、數(shù)據(jù)的匯總與加權(quán)。整理數(shù)據(jù)文件的功能主要通過“數(shù)據(jù)”菜單和“轉(zhuǎn)換”菜單來完成����。
一、數(shù)據(jù)的排序
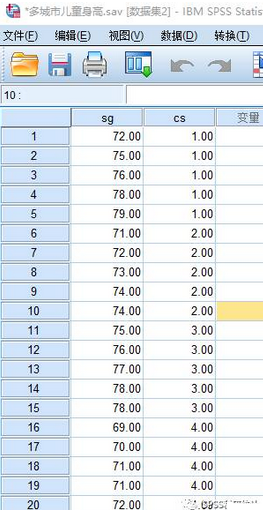
一般我們創(chuàng)建的數(shù)據(jù)文件在編輯窗口中個(gè)案的前后次序是隨機(jī)的�����,其先后順序由錄入時(shí)決定�。在做數(shù)據(jù)統(tǒng)計(jì)分析時(shí),有時(shí)希望按某種順序來觀察一批數(shù)據(jù)�,以便于更好地了解數(shù)據(jù)信息。例如:多城市兒童身高�����,希望身高是按從高到低的順序觀察。SPSS中的數(shù)據(jù)排序就是將數(shù)據(jù)編輯窗口中的數(shù)據(jù),按照指定的某一個(gè)或多個(gè)變量值的升序或降序重新排列�����,所指定的變量稱為排序變量���。當(dāng)排序變量只有一個(gè)時(shí)�����,為單值排序����,則按照排序變量取值的大小次序?qū)€(gè)案數(shù)據(jù)重新整理后顯示�����。當(dāng)排序變量有多個(gè)時(shí)�,為多重排序。多重排序的第一個(gè)排序變量稱為主排序變量�����,其他排序變量依次稱為第二排序變量、第三排序變量等���。在多重排序時(shí)�,個(gè)案先按主排序變量值的大小排序����,當(dāng)主排序變量值一致時(shí),再按第二排序變量值大小排序�,依次類推。數(shù)據(jù)排序的主要操作方法如下:
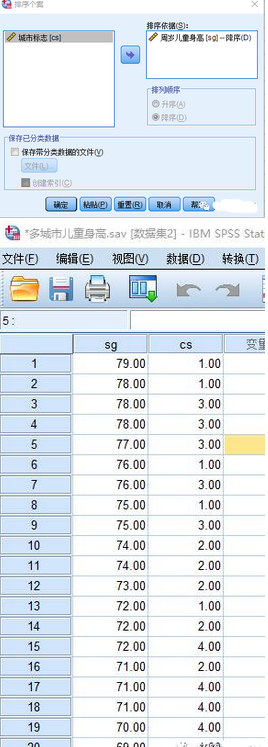
單擊“數(shù)據(jù)” |“排序個(gè)案”命令����,彈出“排序個(gè)案“對(duì)話框�����,排序前數(shù)據(jù)如下圖所示�����。將排序變量選定后����,設(shè)置好排序方式�����,如排序個(gè)案圖所示�,單擊“確定”按鈕��,會(huì)自動(dòng) 跳轉(zhuǎn)到排序后的數(shù)據(jù)編輯窗口���。
(1) “排序依據(jù)”框是選擇指定的排序變量����,若排序變量有多個(gè)��,將自動(dòng)按照它們?cè)诖肆斜淼娘@示次序���,依次對(duì)數(shù)據(jù)進(jìn)行排序�����。
二�、數(shù)據(jù)的拆分
在進(jìn)行統(tǒng)計(jì)分析時(shí)����,只需要對(duì)具有某種特性的數(shù)據(jù)進(jìn)行分析�,那么就涉及到分組分析���,則可以通過拆分?jǐn)?shù)據(jù)集來加以實(shí)現(xiàn)���,它能使數(shù)據(jù)分析過程按照分組變量進(jìn)行分組分析,得到各個(gè)組的結(jié)果��。通過拆分功能��,還可以實(shí)現(xiàn)對(duì)原始數(shù)據(jù)的重新排序��,使某一變量取值相同的個(gè)案集中在一起��,便于觀察和比較�����。具體的操作方法如下:
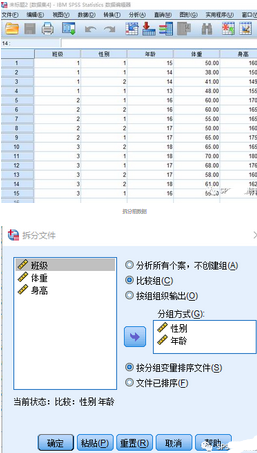
單擊“數(shù)據(jù)”丨“拆分文件”命令����,彈出“分割文件”對(duì)話框
(1) “分組方式”框用于選擇拆分的變量�����,此變量可以是一種及以上。
(2) 指定拆分方式����。
分析所有個(gè)案,不創(chuàng)建組:是系統(tǒng)的默認(rèn)值�,表示分析所有的個(gè)案,取消拆分����,它可恢復(fù)分組前的狀態(tài);
比較組:分組分析����,按組間比較的形式輸出結(jié)果;
按組組織輸出:分組分析�,分別顯示各組所得的結(jié)果。
(3) 指定排序方式���。
按分組變量排序文件:拆分時(shí)將數(shù)據(jù)按所用的拆分變量排序��,這是系統(tǒng)默認(rèn)選項(xiàng)���;
文件已排序:標(biāo)識(shí)數(shù)據(jù)己經(jīng)按分組變量排序了,不需要重新排序���。
拆分前數(shù)據(jù)
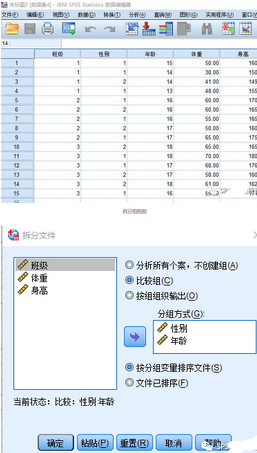
數(shù)據(jù)拆分的參數(shù)設(shè)置
選中拆分變量后���,單擊“確定”按鈕����,自動(dòng)彈出拆分后的數(shù)據(jù)編輯窗口���,如上圖所示����。右下側(cè)會(huì)出現(xiàn)“拆分條件”的提示�,表明所做的拆分正在生效,它將在以后的分析中一直有效�����,而且會(huì)被存儲(chǔ)在數(shù)據(jù)集中�����,直到再次進(jìn)行設(shè)定為止����。數(shù)據(jù)進(jìn)行拆分后,其分析結(jié)果的顯示表格����,如下圖所示
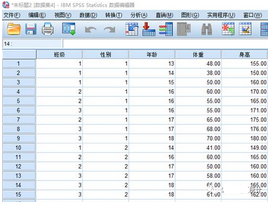
拆分后收數(shù)據(jù)
三、數(shù)據(jù)的合并
當(dāng)數(shù)據(jù)量很大時(shí)��,經(jīng)常需要將一份大的數(shù)據(jù)分成幾個(gè)小部分����,由不同的人對(duì)數(shù)據(jù)進(jìn)行錄入,以提高錄入效率��。這樣就會(huì)出現(xiàn)一份大的數(shù)據(jù)分別存儲(chǔ)在幾個(gè)不同的數(shù)據(jù)文件中的現(xiàn)象�����。因此���,將這些若干個(gè)小的數(shù)據(jù)文件合并成一個(gè)大的數(shù)據(jù)文件���,是進(jìn)行各種統(tǒng)計(jì)分析的前提。SPSS數(shù)據(jù)文件的合并方式有兩種:縱向合并和橫向合并�。在SPSS系統(tǒng)中,進(jìn)行合并的文件必須都存儲(chǔ)為SPSS數(shù)據(jù)格式。
(1)縱向合并
縱向合并指的是幾個(gè)數(shù)據(jù)集中的數(shù)據(jù)縱向相加��,組成一個(gè)新的數(shù)據(jù)集���,新數(shù)據(jù)集中的記錄數(shù)是原來幾個(gè)數(shù)據(jù)集中記錄數(shù)的總和��,實(shí)質(zhì)就是將兩個(gè)數(shù)據(jù)文件的變量列����,按照各個(gè)變量名的含義����,一一對(duì)應(yīng)進(jìn)行首尾連接合并。合并的兩個(gè)數(shù)據(jù)文件的變量相同����,合并的目的是增加分析個(gè)案。
實(shí)現(xiàn)SPSS數(shù)據(jù)文件的縱向合并應(yīng)遵循兩個(gè)條件:第一���,兩個(gè)待合并的SPSS數(shù)據(jù)文件����,其內(nèi)容合并是有實(shí)際意義的���;第二����,為方便SPSS數(shù)據(jù)文件的合并�����,在不同數(shù)據(jù)文件中���,數(shù)據(jù)含義相同的列���,最好起相同的名字,變量類型和變量長度也要盡量相同�����。這樣���,將方便SPSS對(duì)變量的自動(dòng)對(duì)應(yīng)和匹配��。
(2)橫向合并
橫向合并指的是按照記錄的次序�,或者某個(gè)關(guān)鍵變量的數(shù)值���,將不同數(shù)據(jù)集中的不同變量合并為一個(gè)數(shù)據(jù)集��,新數(shù)據(jù)集中的變量數(shù)是所有原數(shù)據(jù)集中不重名變量的總和����,實(shí)質(zhì)就是將兩個(gè)數(shù)據(jù)文件的記錄,按照記錄對(duì)應(yīng)��,一一進(jìn)行左右對(duì)接�����。合并的兩個(gè)數(shù)據(jù)文件的變量不同����,但具有相同個(gè)案例數(shù)。
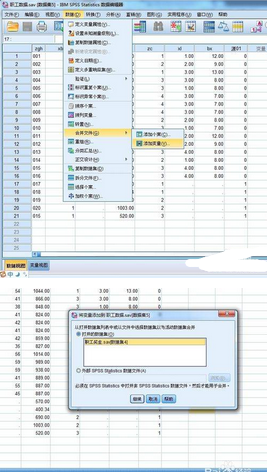
實(shí)現(xiàn)SPSS數(shù)據(jù)文件的橫向合并應(yīng)遵循三個(gè)條件��,第一�����,如果不是按照記錄號(hào)對(duì)應(yīng)的規(guī)則進(jìn)行合并�����,則兩個(gè)數(shù)據(jù)文件必須至少有一個(gè)變量名相同的公共變量,這個(gè)變量是兩個(gè)數(shù)據(jù)文件橫向?qū)?yīng)合并的依據(jù)�,稱為關(guān)鍵變量。如學(xué)號(hào)�、貴賓卡號(hào)等����,關(guān)鍵變量可以是多個(gè);第二���,如果是使用關(guān)鍵變量進(jìn)行合并的�,則兩個(gè)數(shù)據(jù)文件都必須事先按關(guān)鍵變量進(jìn)行升序排列�;第三,為方便SPSS數(shù)據(jù)文件的合并����,在不同數(shù)據(jù)文件中,數(shù)據(jù)含義不相同的列���,變量名不應(yīng)取相同的名稱���。數(shù)據(jù)合并的操作方法如下:單擊“數(shù)據(jù)”丨“合并文件”丨“添加個(gè)案”命令,彈出添加個(gè)案文件選擇對(duì)話框操作即可�。
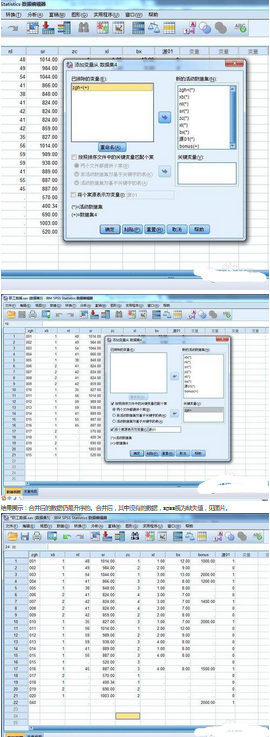
打開數(shù)據(jù)合并窗口��。因是橫向合并����,所以選擇“添加變量”�����。第二個(gè)圖片顯示合并的數(shù)據(jù)文件��。
“已排除的變量”是兩個(gè)文件中共同擁有的變量名�����,選擇它作為“關(guān)鍵變量”���?�!靶碌幕顒?dòng)數(shù)據(jù)集”是最后展示在結(jié)果中的變量名����。變量名后的“*”表示當(dāng)前數(shù)據(jù)編輯窗口中的量�,“+”表示指定文件中的變量?���!鞍凑张判蛭募械年P(guān)鍵變量匹配個(gè)案”中通常選擇第一個(gè)��,即“兩個(gè)文件都提供個(gè)案”�����。
推薦學(xué)習(xí)書籍
《CDA一級(jí)教材》適合CDA一級(jí)考生備考��,也適合業(yè)務(wù)及數(shù)據(jù)分析崗位的從業(yè)者提升自我。完整電子版已上線CDA網(wǎng)校�����,累計(jì)已有10萬+在讀~

免費(fèi)加入閱讀:https://edu.cda.cn/goods/show/3151?targetId=5147&preview=0
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試�,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材��,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫�,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量�,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營許可證編號(hào):京B2-20210330