摘要
在神經(jīng)網(wǎng)絡(luò)模型設(shè)計中�,隱藏層神經(jīng)元個數(shù)的確定是影響模型性能、訓練效率與泛化能力的關(guān)鍵環(huán)節(jié)����。本文從神經(jīng)網(wǎng)絡(luò)的基礎(chǔ)結(jié)構(gòu)出發(fā)��,系統(tǒng)梳理隱藏層神經(jīng)元個數(shù)確定的核心方法�,包括經(jīng)驗公式法���、實驗調(diào)整法�、自適應優(yōu)化法等,結(jié)合不同任務場景分析影響神經(jīng)元個數(shù)選擇的關(guān)鍵因素��,并通過實際案例驗證方法的有效性���,同時指出常見認知誤區(qū)�����,為工程師與研究者提供可落地的神經(jīng)元個數(shù)設(shè)計指南�����。
一�、引言:隱藏層與神經(jīng)元個數(shù)的核心意義
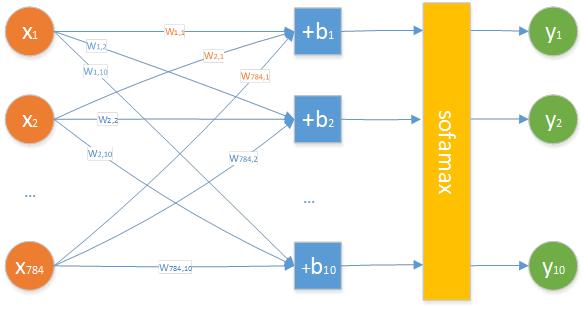
典型的神經(jīng)網(wǎng)絡(luò)由輸入層���、隱藏層與輸出層構(gòu)成�����。輸入層負責接收原始數(shù)據(jù)(如圖像像素���、文本特征)����,輸出層輸出模型預測結(jié)果(如分類標簽���、回歸值)�����,而隱藏層則通過非線性變換提取數(shù)據(jù)的深層特征 —— 這一 “特征提取” 能力的強弱��,直接取決于隱藏層的層數(shù)與每層神經(jīng)元的個數(shù)�����。
1.2 神經(jīng)元個數(shù)的關(guān)鍵影響
隱藏層神經(jīng)元個數(shù)的選擇存在 “Goldilocks 困境”:
個數(shù)過少:模型表達能力不足��,無法捕捉數(shù)據(jù)中的復雜規(guī)律�����,易出現(xiàn) “欠擬合”,表現(xiàn)為訓練集與測試集誤差均較高����;
個數(shù)過多:模型復雜度超出數(shù)據(jù)需求�����,易記憶訓練集中的噪聲��,導致 “過擬合”����,表現(xiàn)為訓練集誤差低但測試集誤差驟升�����;
個數(shù)不合理:還會增加訓練時間(如參數(shù)更新次數(shù)增多�����、梯度消失風險上升)�,浪費計算資源(如內(nèi)存占用過高)。
因此�,科學確定隱藏層神經(jīng)元個數(shù),是平衡模型性能�����、效率與泛化能力的核心前提�。
二����、隱藏層神經(jīng)元個數(shù)確定的核心方法
2.1 經(jīng)驗公式法:快速估算初始值
經(jīng)驗公式基于輸入層���、輸出層神經(jīng)元個數(shù)與數(shù)據(jù)特性���,為隱藏層神經(jīng)元個數(shù)提供初始參考范圍,適用于模型設(shè)計的初步階段���。以下為工業(yè)界常用公式及適用場景:
| 經(jīng)驗公式 |
公式表達式(為隱藏層神經(jīng)元個數(shù)�,為輸入層個數(shù)�,為輸出層個數(shù),為樣本數(shù)量) |
適用場景 |
優(yōu)缺點 |
| 基礎(chǔ)比例法 |
(為 1-10 的調(diào)整系數(shù)) |
簡單任務(如線性分類�、小規(guī)模回歸) |
計算簡單���,適合快速初始化��;忽略數(shù)據(jù)復雜度��,精度有限 |
| 數(shù)據(jù)規(guī)模法 |
或 |
樣本量較小()的場景 |
考慮數(shù)據(jù)量對泛化能力的影響���;樣本量過大時估算值偏保守 |
| 復雜度適配法 |
或 |
中等復雜度任務(如文本分類�����、簡單圖像識別) |
平衡輸入輸出層影響��,適配多數(shù)傳統(tǒng)機器學習任務��;對深度學習復雜任務適用性弱 |
注意:經(jīng)驗公式的結(jié)果僅為 “初始值”�,需結(jié)合后續(xù)實驗調(diào)整,不可直接作為最終值����。例如,在手寫數(shù)字識別任務中(輸入層 784 個神經(jīng)元���,輸出層 10 個)�,按基礎(chǔ)比例法計算得 ��,可將 80-100 作為神經(jīng)元個數(shù)的初始搜索范圍��。
2.2 實驗調(diào)整法:迭代優(yōu)化最優(yōu)值
實驗調(diào)整法通過 “控制變量 + 性能驗證” 的方式����,在經(jīng)驗公式的基礎(chǔ)上找到最優(yōu)神經(jīng)元個數(shù)���,是工業(yè)界最常用的落地方法,核心步驟如下:
2.2.1 確定搜索范圍與步長
以經(jīng)驗公式估算值為中心��,設(shè)定合理的搜索范圍(如估算值 ±50%)與步長(如步長為 10 或 20�,避免搜索效率過低)。例如�,若初始估算值為 80,可設(shè)定搜索范圍為 40-120�,步長為 20。
2.2.2 交叉驗證與性能評估
對每個候選神經(jīng)元個數(shù)�����,采用 k 折交叉驗證(通常 k=5 或 10)訓練模型���,評估指標需覆蓋 “擬合程度”(如訓練集準確率�、MSE)與 “泛化能力”(如測試集準確率�、交叉驗證均值),同時記錄訓練時間與內(nèi)存占用�����。
2.2.3 確定最優(yōu)值
繪制 “神經(jīng)元個數(shù) - 性能指標” 曲線,選擇 “測試集性能最高�、訓練效率可接受” 的點作為最優(yōu)值。例如��,在某文本分類任務中��,當神經(jīng)元個數(shù)從 40 增至 80 時����,測試集 F1 分數(shù)從 0.82 升至 0.89��;繼續(xù)增至 120 時���,F(xiàn)1 分數(shù)僅提升 0.01����,但訓練時間增加 40%��,此時 80 即為最優(yōu)值���。
2.3 自適應優(yōu)化法:智能化搜索
隨著自動機器學習(AutoML)的發(fā)展���,自適應優(yōu)化法通過算法自動搜索最優(yōu)神經(jīng)元個數(shù)�,減少人工干預��,適用于復雜模型(如深度神經(jīng)網(wǎng)絡(luò)�����、Transformer 子網(wǎng)絡(luò)):
2.3.1 網(wǎng)格搜索與隨機搜索
網(wǎng)格搜索:遍歷預設(shè)的所有神經(jīng)元個數(shù)組合(如隱藏層 1:[60,80,100]�����,隱藏層 2:[30,40,50])�,適合小范圍精細搜索;
隨機搜索:在搜索范圍內(nèi)隨機采樣候選值���,適合大范圍快速探索����,實驗表明其在高維空間中效率優(yōu)于網(wǎng)格搜索����。
基于貝葉斯定理構(gòu)建 “神經(jīng)元個數(shù) - 性能” 的概率模型,每次迭代根據(jù)歷史實驗結(jié)果����,優(yōu)先選擇 “可能帶來性能提升” 的候選值����,大幅減少搜索次數(shù)��。例如�,在 CNN 圖像分類任務中,貝葉斯優(yōu)化可將神經(jīng)元個數(shù)搜索次數(shù)從 50 次降至 15 次�,同時找到更優(yōu)值�����。
2.3.3 進化算法
模擬生物進化過程(選擇���、交叉��、變異)����,將神經(jīng)元個數(shù)作為 “基因” 構(gòu)建種群����,通過多代迭代篩選出性能最優(yōu)的 “個體”。該方法適用于多隱藏層模型�����,可同時優(yōu)化各層神經(jīng)元個數(shù)(如隱藏層 1 與隱藏層 2 的個數(shù)組合)。
三��、影響神經(jīng)元個數(shù)選擇的關(guān)鍵因素
3.1 數(shù)據(jù)特性
數(shù)據(jù)維度:高維數(shù)據(jù)(如高清圖像����、長文本)需更多神經(jīng)元捕捉特征,例如 224×224 圖像的輸入層(50176 個神經(jīng)元)對應的隱藏層個數(shù)�,通常比 28×28 圖像(784 個神經(jīng)元)多 2-3 倍;
數(shù)據(jù)分布:非結(jié)構(gòu)化數(shù)據(jù)(如語音、視頻)比結(jié)構(gòu)化數(shù)據(jù)(如表格數(shù)據(jù))需更多神經(jīng)元���,因前者特征提取難度更高����。
3.2 任務類型
分類任務:類別數(shù)越多�,輸出層個數(shù)越多,隱藏層個數(shù)需相應增加(如 100 類分類任務比 10 類任務的隱藏層個數(shù)多 30%-50%)���;
回歸任務:輸出值精度要求越高����,隱藏層個數(shù)需適當增加,但需控制復雜度以避免過擬合�;
生成任務(如 GAN、VAE):需更多神經(jīng)元構(gòu)建復雜的生成模型�,例如 GAN 的生成器隱藏層神經(jīng)元個數(shù)通常比判別器多 50% 以上。
3.3 網(wǎng)絡(luò)架構(gòu)
隱藏層層數(shù):多層隱藏層(深度網(wǎng)絡(luò))可減少單層神經(jīng)元個數(shù)����,例如 “2 層隱藏層(各 80 個神經(jīng)元)” 的性能可能優(yōu)于 “1 層隱藏層(160 個神經(jīng)元)”����,且更易訓練;
特殊層設(shè)計:含卷積層����、池化層的 CNN,全連接隱藏層的神經(jīng)元個數(shù)可大幅減少(因卷積層已完成特征降維)�;含注意力機制的 Transformer,隱藏層神經(jīng)元個數(shù)需與注意力頭數(shù)匹配(如頭數(shù)為 8 時�,神經(jīng)元個數(shù)通常為 512 或 1024,需被 8 整除)���。
若采用強正則化方法(如 Dropout 率 0.5����、L2 正則化系數(shù)較大),可適當增加神經(jīng)元個數(shù) —— 正則化可抑制過擬合�����,而更多神經(jīng)元能提升模型表達能力��。例如����,在使用 Dropout 的文本分類任務中,隱藏層神經(jīng)元個數(shù)可從 80 增至 120��,且無明顯過擬合����。
四、實際案例:手寫數(shù)字識別任務的神經(jīng)元個數(shù)確定
4.1 任務背景
數(shù)據(jù)集:MNIST(60000 張訓練圖��、10000 張測試圖����,每張 28×28 像素����,輸入層 784 個神經(jīng)元��,輸出層 10 個神經(jīng)元)��;
模型:2 層全連接神經(jīng)網(wǎng)絡(luò)(隱藏層 1 + 隱藏層 2)�;
目標:確定兩層隱藏層的最優(yōu)神經(jīng)元個數(shù),使測試集準確率≥98%�,訓練時間≤30 分鐘。
4.2 步驟 1:經(jīng)驗公式估算初始范圍
隱藏層 1 初始值:按基礎(chǔ)比例法 �����,設(shè)定范圍 60-120��;
隱藏層 2 初始值:按數(shù)據(jù)規(guī)模法 (因多層網(wǎng)絡(luò)可減少單層個數(shù)�����,調(diào)整為 40-80)���。
采用貝葉斯優(yōu)化工具(如 Hyperopt),以 “測試集準確率” 為目標函數(shù)�����,搜索范圍:H1∈[60,120],H2∈[40,80]����,迭代 15 次。
4.4 步驟 3:結(jié)果分析與最優(yōu)值確定
| 隱藏層 1 個數(shù) |
隱藏層 2 個數(shù) |
測試集準確率 |
訓練時間 |
結(jié)論 |
| 80 |
60 |
98.2% |
22 分鐘 |
準確率達標�,時間最優(yōu) |
| 100 |
70 |
98.3% |
28 分鐘 |
準確率略高,時間接近上限 |
| 120 |
80 |
98.3% |
35 分鐘 |
準確率無提升��,時間超上限 |
最終選擇 “隱藏層 1:80 個���,隱藏層 2:60 個”��,滿足性能與效率需求�����。
五�、常見認知誤區(qū)與規(guī)避策略
5.1 誤區(qū) 1:神經(jīng)元個數(shù)越多����,模型性能越好
規(guī)避策略:以 “測試集性能” 而非 “訓練集性能” 為核心指標,當神經(jīng)元個數(shù)增加但測試集性能無提升時,立即停止增加���;配合正則化方法�,平衡表達能力與泛化能力���。
5.2 誤區(qū) 2:所有隱藏層神經(jīng)元個數(shù)必須相同
規(guī)避策略:根據(jù) “特征提取邏輯” 設(shè)計不同層數(shù)的神經(jīng)元個數(shù) —— 通常隱藏層從輸入到輸出呈 “遞減” 趨勢(如 784→80→60→10)��,因深層網(wǎng)絡(luò)需逐步壓縮特征維度�,減少冗余信息�����。
5.3 誤區(qū) 3:忽略硬件資源限制
規(guī)避策略:在確定搜索范圍時�����,先計算參數(shù)總量(每個神經(jīng)元的參數(shù) = 輸入維度 + 1���,如 80 個神經(jīng)元的參數(shù) = 784+1=785)����,確保參數(shù)總量不超過硬件內(nèi)存(如 GPU 內(nèi)存 8GB 時���,參數(shù)總量≤1e8)�����。
六�����、未來發(fā)展趨勢
隨著大模型與自適應架構(gòu)的興起��,隱藏層神經(jīng)元個數(shù)的確定正從 “人工設(shè)計” 向 “自動優(yōu)化” 演進:
動態(tài)架構(gòu)模型(如 Dynamic Neural Networks)可根據(jù)輸入數(shù)據(jù)實時調(diào)整神經(jīng)元個數(shù)�����,避免固定結(jié)構(gòu)的局限性���;
預訓練模型(如 BERT、ResNet)通過海量數(shù)據(jù)學習到最優(yōu)的神經(jīng)元個數(shù)配置���,微調(diào)階段僅需小幅調(diào)整�,減少設(shè)計成本���;
多目標優(yōu)化算法(如兼顧準確率���、速度���、能耗)將成為神經(jīng)元個數(shù)確定的核心方向,適配邊緣設(shè)備等資源受限場景����。
七、結(jié)論
隱藏層神經(jīng)元個數(shù)的確定并非 “一刀切” 的固定規(guī)則���,而是 “理論指導 + 實驗驗證 + 場景適配” 的迭代過程:首先通過經(jīng)驗公式確定初始范圍�,再通過實驗調(diào)整或自適應優(yōu)化找到最優(yōu)值����,最終結(jié)合數(shù)據(jù)特性、任務需求與硬件資源驗證有效性����。未來,隨著自動機器學習技術(shù)的成熟��,神經(jīng)元個數(shù)的設(shè)計將更高效���、更智能�����,但工程師仍需理解其核心邏輯�,才能在復雜場景中做出合理決策�。
參考文獻
[1] Bishop C M. Pattern Recognition and Machine Learning [M]. Springer, 2006.(經(jīng)典教材,系統(tǒng)闡述神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)設(shè)計原理)
[2] Bergstra J, Bengio Y. Random Search for Hyper-Parameter Optimization [J]. Journal of Machine Learning Research, 2012.(隨機搜索在超參數(shù)優(yōu)化中的應用)
[3] Snoek J, Larochelle H, Adams R P. Practical Bayesian Optimization of Machine Learning Algorithms [C]. NeurIPS, 2012.(貝葉斯優(yōu)化的經(jīng)典論文)
推薦學習書籍 《CDA一級教材》適合CDA一級考生備考�����,也適合業(yè)務及數(shù)據(jù)分析崗位的從業(yè)者提升自我����。完整電子版已上線CDA網(wǎng)校,累計已有10萬+在讀~ !












 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330