啟用HDFS文件系統(tǒng)之前�,需要對其進行格式化;格式化只需做一次
在192.168.31.130上執(zhí)行如下命令
cd /opt/linuxsir/hadoop/bin
./hdfs namenode -format
清理hadoop日志
rm -rf /opt/linuxsir/hadoop/logs/*.*
ssh root@192.168.31.132 rm -rf /opt/linuxsir/hadoop/logs/*.*
ssh root@192.168.31.133 rm -rf /opt/linuxsir/hadoop/logs/*.*
cd /opt/linuxsir/hadoop/sbin
./start-all.sh
\如果要停止�,請執(zhí)行如下命令
cd /opt/linuxsir/hadoop/sbin
./stop-all.sh
clear
cd /opt/linuxsir/hadoop/sbin
./start-dfs.sh
./start-yarn.sh
\如果要停止,請執(zhí)行如下命令����,即分開停止HDFS和YARN
cd /opt/linuxsir/hadoop/sbin
./stop-yarn.sh
./stop-dfs.sh
現(xiàn)在,可以在三個節(jié)點上����,查看進程,驗證Hadoop是否成功啟動
[root@hd-master bin]
6262 NameNode
28630 Jps
6455 SecondaryNameNode
6618 ResourceManager
[root@hd-master bin]
3431 NodeManager
20697 Jps
3311 DataNode
[root@hd-master bin]
3313 DataNode
3431 NodeManager
20295 Jps
到目前為止�����,啟動HDFS和YARN以后,各個節(jié)點的進程���,如下圖所示
| 層級 |
hd-master |
hd-slave1 |
hd-slave2 |
| hdfs層 |
NameNode�、Secondary�����、NameNode |
DataNode |
DataNode |
| Yarn層 |
ResourceManager |
NodeManager |
NodeManager |
| hardware各個節(jié)點 |
192.168.31.131 |
192.168.31.132 |
192.168.31.133 |
在hd-master上運行如下命令��,報告HDFS的基本信息
cd /opt/linuxsir/hadoop
./bin/hdfs dfsadmin -report
[root@hd-master bin]# cd /opt/linuxsir/hadoop
[root@hd-master hadoop]# ./bin/hdfs dfsadmin -report
Configured Capacity: 63116517376 (58.78 GB)
Present Capacity: 52430880768 (48.83 GB)
DFS Remaining: 52430462976 (48.83 GB)
DFS Used: 417792 (408 KB)
DFS Used%: 0.00%
Under replicated blocks: 2
Blocks with corrupt replicas: 0
Missing blocks: 0
Missing blocks (with replication factor 1): 0
-------------------------------------------------
Live datanodes (2):
Name: 192.168.31.133:50010 (hd-slave2)
Hostname: hd-slave2
Decommission Status : Normal
Configured Capacity: 31558258688 (29.39 GB)
DFS Used: 208896 (204 KB)
Non DFS Used: 5349883904 (4.98 GB)
DFS Remaining: 26208165888 (24.41 GB)
DFS Used%: 0.00%
DFS Remaining%: 83.05%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Fri Oct 11 01:29:14 PDT 2024
Name: 192.168.31.132:50010 (hd-slave1)
Hostname: hd-slave1
Decommission Status : Normal
Configured Capacity: 31558258688 (29.39 GB)
DFS Used: 208896 (204 KB)
Non DFS Used: 5335752704 (4.97 GB)
DFS Remaining: 26222297088 (24.42 GB)
DFS Used%: 0.00%
DFS Remaining%: 83.09%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Fri Oct 11 01:29:14 PDT 2024
使用日志
如果Hadoop啟動出問題��,可以通過查看日志來尋找原因��。每次啟動Hadoop�,應該首先清空三個節(jié)點的logs目錄,方便尋找錯誤��。
當啟動出錯���,可以到相應節(jié)點上��,查看日志文件�����。哪個節(jié)點啟動出錯�����,就看哪個節(jié)點的日志文件�。由于有無密碼ssh登錄���,可以通過主節(jié)點登錄到其它節(jié)點��,去查看所有節(jié)點的日志文件����。
日志文件分別在hd-master�、hd-slave1、hd-slave2的/opt/linuxsir/hadoop/logs目錄下�����。
啟動Hadoop之前�,刪除log文件
如果啟動出問題,log文件里就是最新的出錯信息
rm -rf /opt/linuxsir/hadoop/logs/*.*
ssh root@192.168.31.132 rm -rf /opt/linuxsir/hadoop/logs/*.*
ssh root@192.168.31.133 rm -rf /opt/linuxsir/hadoop/logs/*.*
管理界面
若干web管理界面�,列表如下
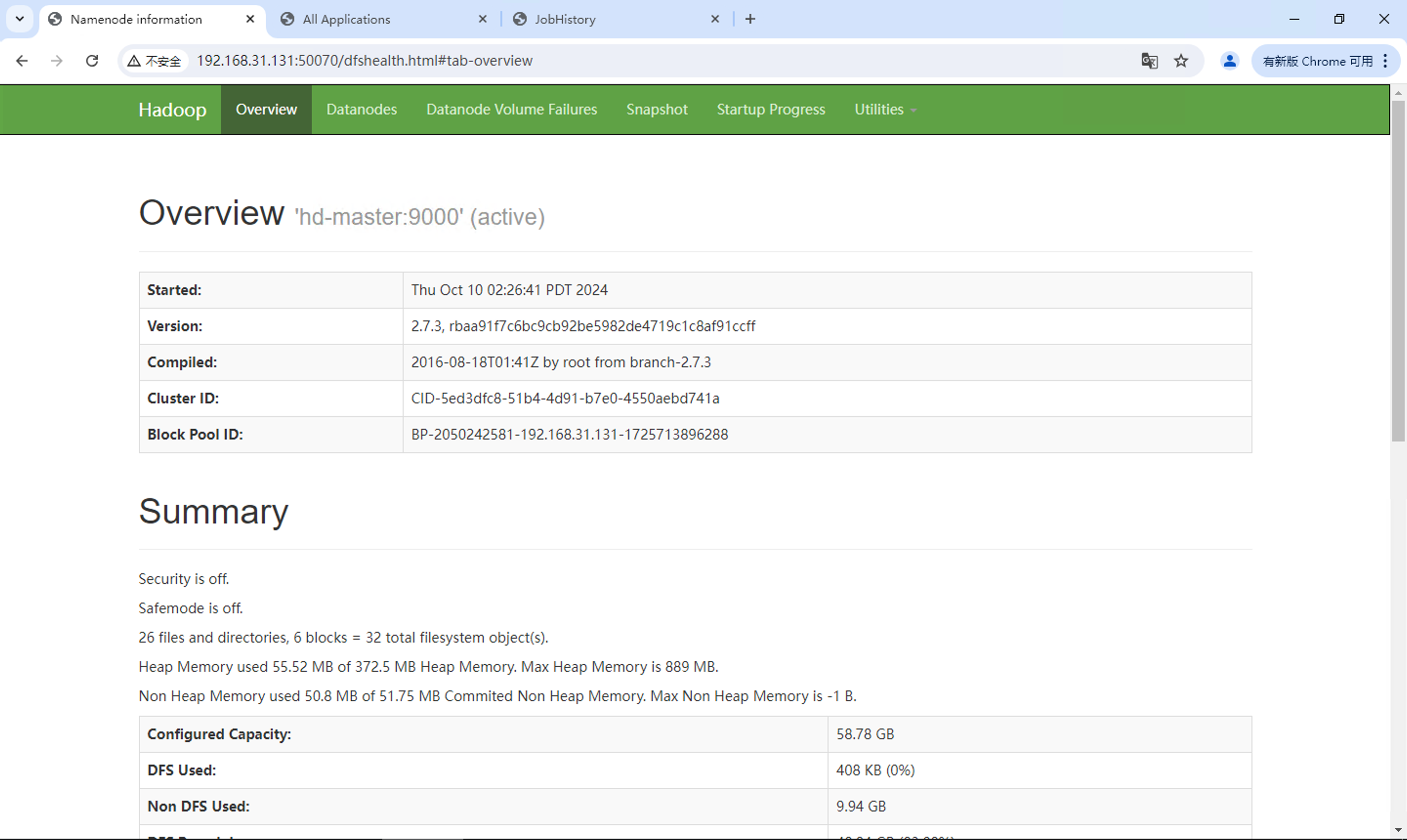
訪問NameNode管理頁面,監(jiān)控文件系統(tǒng)����。
http://192.168.31.131:50070/
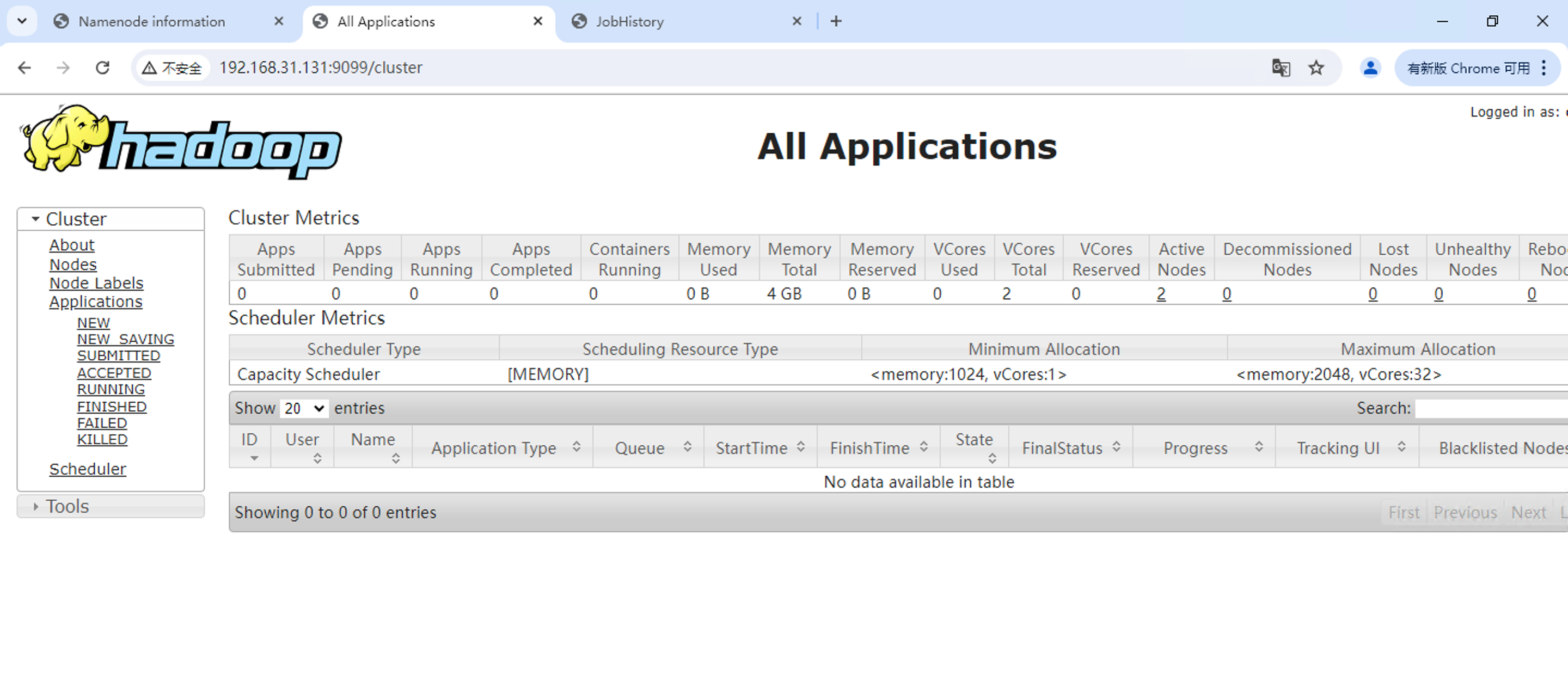
訪問ResourceManager(整個Cluster)管理頁面����,監(jiān)控集群狀況�。
http://192.168.31.131:9099/
這個端口缺省是8088,由于端口沖突���,改成9099, 參考yarn-site.xml
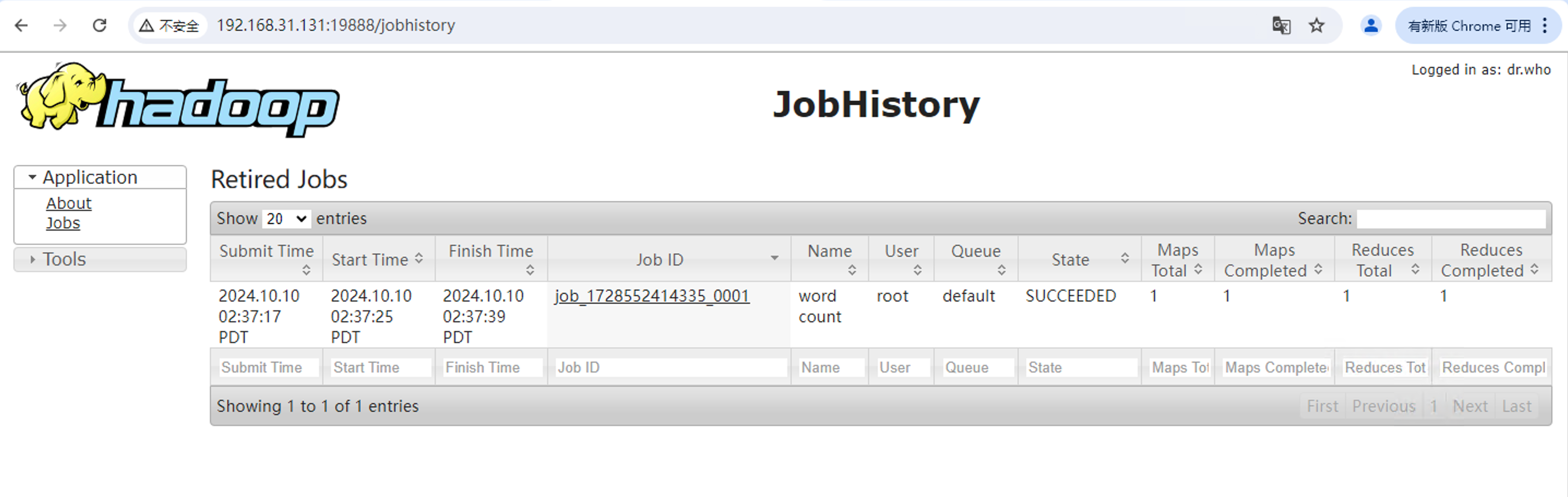
MapReduce JobHistory Server的管理頁面,查看MapReduce作業(yè)提交歷史�����;需要事先啟動JobHistory Server����。
http://192.168.31.131:19888/
HDFS 常用文件操作命令
cd /opt/linuxsir/hadoop/bin
hdfs dfsadmin -safemode leave
\ 用戶可以通過dfsadmin -safemode value 來操作安全模式,參數(shù)value的說明如下:
\ enter - 進入安全模式
\ leave - 強制NameNode離開安全模式
\ get - 返回安全模式是否開啟的信息
\ wait - 等待���,一直到安全模式結束
cd /opt/linuxsir/hadoop/bin
./hdfs dfs -rm -r /input \ 遞歸式刪除目錄
./hdfs dfs -mkdir /input \ 創(chuàng)建目錄
./hdfs dfs -chmod a+rwx /input \ 授權
./hdfs dfs -mkdir /output \ 創(chuàng)建目錄
./hdfs dfs -copyFromLocal /opt/linuxsir/test.txt /input \ 拷貝文件到HDFS
\ 或者./hdfs dfs -put /opt/linuxsir/test.txt /input
./hdfs dfs -cat /input/test.txt | head \ 顯示文件的頭幾行
查看Wordcount MapReduce程序所需的數(shù)據(jù)
注意���,需要事先啟動HDFS和YARN
cd /opt/linuxsir/hadoop/bin
./hdfs dfs -cat /input/test.txt
./hadoop jar /opt/linuxsir/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /input/test.txt /output
./hdfs dfs -ls /output
./hdfs dfs -cat /output/part-r-00000
為了運行wordcount,必須保證hdfs分布式文件系統(tǒng)的/output不存在。如果存在可以把它刪除���,命令如下
cd /opt/linuxsir/hadoop/bin
./hdfs dfs -ls /output
./hdfs dfs -rm /output/*
./hdfs dfs -rmdir /output
配置History Server
在hd-master節(jié)點上�����,配置History Server
1�����、在.../etc/hadoop/mapred-site.xml中配置以下內容
<property>
<name>mapreduce.jobhistory.address</name>
<value>hd-master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hd-master:19888</value>
</property>
2、把hd-master的新配置分發(fā)到所有節(jié)點即hd-slave1和hd-slave2���。
clear
scp /opt/linuxsir/hadoop/etc/hadoop/mapred-site.xml hd-slave1:/opt/linuxsir/hadoop/etc/hadoop
scp /opt/linuxsir/hadoop/etc/hadoop/mapred-site.xml hd-slave2:/opt/linuxsir/hadoop/etc/hadoop
3���、啟動服務,在hd-master這臺服務器上執(zhí)行以下語句�����。
注意��,需要事先啟動HDFS和YARN
cd /opt/linuxsir/hadoop/sbin
mr-jobhistory-daemon.sh start historyserver
clear
jps
ssh root@192.168.31.132 jps
ssh root@192.168.31.133 jps
訪問MapReduce JobHistory Server
http://192.168.31.131:19888/
為了順利運行該實例���,需要編輯/opt/linuxsir/hadoop/etc/hadoop/hdfs-site.xml配置文件���,添加如下配置
<!-- for windows access linux HDFS -->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
這里分享一個你一定用得到的小程序——CDA數(shù)據(jù)分析師考試小程序���。
它是專為CDA數(shù)據(jù)分析認證考試報考打造的一款小程序?����?梢詭湍憧焖賵竺荚?����、查成績����、查證書、查積分����,通過該小程序,考生可以享受更便捷的服務����。
掃碼加入CDA小程序,與圈內考生一同學習、交流�、進步!












 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330