數(shù)據(jù)挖掘工程師筆試及答案整理
2013百度校園招聘數(shù)據(jù)挖掘工程師
《數(shù)據(jù)分析專項(xiàng)練習(xí)題庫(kù)》
《CDA數(shù)據(jù)分析認(rèn)證考試模擬題庫(kù)》
《企業(yè)數(shù)據(jù)分析面試題庫(kù)》
一、簡(jiǎn)答題(30分)
1���、簡(jiǎn)述數(shù)據(jù)庫(kù)操作的步驟(10分)
步驟:建立數(shù)據(jù)庫(kù)連接��、打開數(shù)據(jù)庫(kù)連接����、建立數(shù)據(jù)庫(kù)命令��、運(yùn)行數(shù)據(jù)庫(kù)命令�、保存數(shù)據(jù)庫(kù)命令、關(guān)閉數(shù)據(jù)庫(kù)連接��。
經(jīng)萍萍提醒��,了解到應(yīng)該把preparedStatement預(yù)處理也考慮在數(shù)據(jù)庫(kù)的操作步驟中。此外��,對(duì)實(shí)時(shí)性要求不強(qiáng)時(shí)��,可以使用數(shù)據(jù)庫(kù)緩存����。
2、TCP/IP的四層結(jié)構(gòu)(10分)
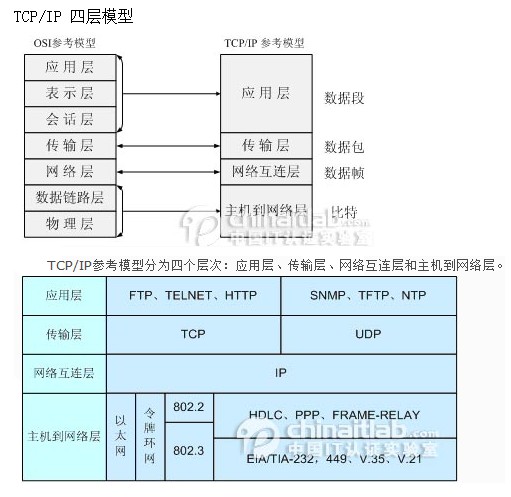
3��、什么是MVC結(jié)構(gòu)�,簡(jiǎn)要介紹各層結(jié)構(gòu)的作用(10分)
Model、view��、control��。
我之前有寫過一篇《MVC層次的劃分》
二�����、算法與程序設(shè)計(jì)(45分)
1����、由a-z�、0-9組成3位的字符密碼���,設(shè)計(jì)一個(gè)算法,列出并打印所有可能的密碼組合(可用偽代碼�、C、C++����、Java實(shí)現(xiàn))(15分)
把a(bǔ)-z,0-9共(26+10)個(gè)字符做成一個(gè)數(shù)組,然后用三個(gè)for循環(huán)遍歷即可���。每一層的遍歷都是從數(shù)組的第0位開始��。
2�����、實(shí)現(xiàn)字符串反轉(zhuǎn)函數(shù)(15分)

3��、百度鳳巢系統(tǒng)�����,廣告客戶購(gòu)買一系列關(guān)鍵詞��,數(shù)據(jù)結(jié)構(gòu)如下:(15分)
User1 手機(jī) 智能手機(jī) iphone 臺(tái)式機(jī) …
User2 手機(jī) iphone 筆記本電腦 三星手機(jī) …
User3 htc 平板電腦 手機(jī) …
(1)根據(jù)以上數(shù)據(jù)結(jié)構(gòu)對(duì)關(guān)鍵詞進(jìn)行KMeans聚類��,請(qǐng)列出關(guān)鍵詞的向量表示�����、距離公式和KMeans算法的整體步驟
KMeans方法一個(gè)很重要的部分就是如何定義距離�,而距離又牽扯到特征向量的定義,畢竟距離是對(duì)兩個(gè)特征向量進(jìn)行衡量����。
本題中,我們建立一個(gè)table�����。

只要兩個(gè)關(guān)鍵詞在同一個(gè)user的描述中出現(xiàn)���,我們就將它在相應(yīng)的表格的位置加1.
這樣我們就有了每個(gè)關(guān)鍵詞的特征向量��。
例如:
<手機(jī)>=(1,1,2,1,1,1,0,0)
<智能手機(jī)> = (1,1,1,1,0,0,0,0)
我們使用夾角余弦公式來計(jì)算這兩個(gè)向量的距離�����。
夾角余弦公式:
設(shè)有兩個(gè)向量a和b���, ,
,
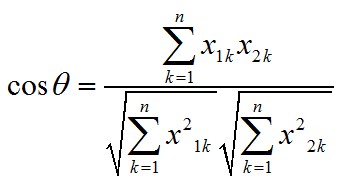
所以���,cos<手機(jī)����,智能機(jī)>=(1+1+2+1)/(sqrt(7+2^2)*sqrt(4))=0.75
cos<手機(jī)�,iphone>=(2+1+2+1+1+1)/(sqrt(7+2^2)*sqrt(2^2+5))=0.80
夾角余弦值越大說明兩者之間的夾角越小,夾角越小說明相關(guān)度越高�����。
通過夾角余弦值我們可以計(jì)算出每?jī)蓚€(gè)關(guān)鍵詞之間的距離�。
特征向量和距離計(jì)算公式的選擇(還有其他很多種距離計(jì)算方式,各有其適應(yīng)的應(yīng)用場(chǎng)所)完成后����,就可以進(jìn)入KMeans算法。
KMeans算法有兩個(gè)主要步驟:1��、確定k個(gè)中心點(diǎn)����;2、計(jì)算各個(gè)點(diǎn)與中心點(diǎn)的距離����,然后貼上類標(biāo)�����,然后針對(duì)各個(gè)類����,重新計(jì)算其中心點(diǎn)的位置�����。
初始化時(shí)����,可以設(shè)定k個(gè)中心點(diǎn)的位置為隨機(jī)值,也可以全賦值為0�����。
KMeans的實(shí)現(xiàn)代碼有很多�����,這里就不寫了。
不過值得一提的是MapReduce模型并不適合計(jì)算KMeans這類遞歸型的算法�,MR最拿手的還是流水型的算法。KMeans可以使用MPI模型很方便的計(jì)算(慶幸的是YARN中似乎開始支持MPI模型了)���,所以hadoop上現(xiàn)在也可以方便的寫高效算法了(但是要是MRv2哦)。
(2)計(jì)算給定關(guān)鍵詞與客戶關(guān)鍵詞的文字相關(guān)性���,請(qǐng)列出關(guān)鍵詞與客戶的表達(dá)符號(hào)和計(jì)算公式
這邊的文字相關(guān)性不知道是不是指非語義的相關(guān)性���,而只是詞頻統(tǒng)計(jì)上的相關(guān)性?如果是語義相關(guān)的�,可能還需要引入topic model來做輔助(可以看一下百度搜索研發(fā)部官方博客的這篇【語義主題計(jì)算】)……
如果是指詞頻統(tǒng)計(jì)的話,個(gè)人認(rèn)為可以使用Jaccard系數(shù)來計(jì)算����。
通過第一問中的表格,我們可以知道某個(gè)關(guān)鍵詞的向量�����,現(xiàn)在將這個(gè)向量做一個(gè)簡(jiǎn)單的變化:如果某個(gè)分量不為0則記為1����,表示包含這個(gè)分量元素,這樣某個(gè)關(guān)鍵詞就可以變成一些詞語的集合,記為A���。
客戶輸入的關(guān)鍵詞列表也可以表示為一個(gè)集合���,記為B
Jaccard系數(shù)的計(jì)算方法是:
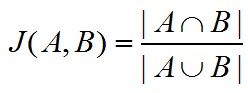
所以,假設(shè)某個(gè)用戶userX的關(guān)鍵詞表達(dá)為:{三星手機(jī)��,手機(jī)���,平板電腦}
那么��,關(guān)鍵詞“手機(jī)”與userX的關(guān)鍵詞之間的相關(guān)性為:
J("手機(jī)"����,“userX關(guān)鍵詞”)=|{三星手機(jī)�,手機(jī),平板電腦}|/|{手機(jī)����,智能手機(jī),iphone�,臺(tái)式機(jī),筆記本電腦����,三星手機(jī)��,HTC�����,平板電腦}| = 3/8
關(guān)鍵詞“三星手機(jī)”與用戶userX的關(guān)鍵詞之間的相關(guān)性為:
J("三星手機(jī)"�,“userX關(guān)鍵詞”)=|{手機(jī)��,三星手機(jī)}|/|{手機(jī)�,三星手機(jī)�����,iphone��,筆記本電腦���,平板電腦}| = 2/5
三�、系統(tǒng)設(shè)計(jì)題(25分)
一維數(shù)據(jù)的擬合�����,給定數(shù)據(jù)集{xi,yi}(i=1,…,n),xi是訓(xùn)練數(shù)據(jù)����,yi是對(duì)應(yīng)的預(yù)期值。擬使用線性����、二次、高次等函數(shù)進(jìn)行擬合
線性:f(x)=ax+b
二次:f(x)=ax^2+bx+c
三次:f(x)=ax^3+bx^2+cx+d
(1)請(qǐng)依次列出線性��、二次����、三次擬合的誤差函數(shù)表達(dá)式(2分)
誤差函數(shù)的計(jì)算公式為:
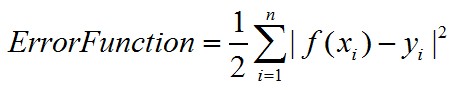
系數(shù)1/2只是為了之后求導(dǎo)的時(shí)候方便約掉而已。
那分別將線性�、二次、三次函數(shù)帶入至公式中f(xi)的位置�����,就可以得到它們的誤差函數(shù)表達(dá)式了�。
(2)按照梯度下降法進(jìn)行擬合,請(qǐng)給出具體的推導(dǎo)過程�����。(7分)
假設(shè)我們樣本集的大小為m,每個(gè)樣本的特征向量為X1=(x11,x12, ..., x1n)����。
那么整個(gè)樣本集可以表示為一個(gè)矩陣:
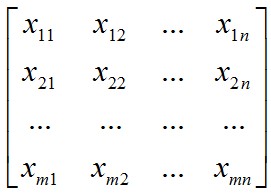 其中每一行為一個(gè)樣本向量。
其中每一行為一個(gè)樣本向量。
我們假設(shè)系數(shù)為θ�,則有系數(shù)向量:

對(duì)于第 i 個(gè)樣本,我們定義誤差變量為
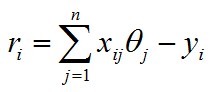
我們可以計(jì)算cost function:

由于θ是一個(gè)n維向量�����,所以對(duì)每一個(gè)分量求偏導(dǎo):
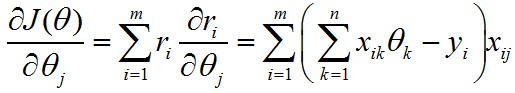
梯度下降的精華就在于下面這個(gè)式子:
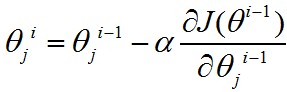
這個(gè)式子是什么意思呢�?是將系數(shù)減去導(dǎo)數(shù)(導(dǎo)數(shù)前的系數(shù)先暫時(shí)不用理會(huì)),為什么是減去導(dǎo)數(shù)�����?我們看一個(gè)二維的例子�����。
假設(shè)有一個(gè)曲線如圖所示:
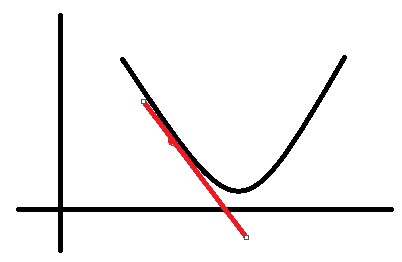
假設(shè)我們處在紅色的點(diǎn)上�����,那么得到的導(dǎo)數(shù)是個(gè)負(fù)值���。此時(shí)����,我在當(dāng)前位置(x軸)的基礎(chǔ)上減去一個(gè)負(fù)值����,就相當(dāng)于加上了一個(gè)正值,那么就朝導(dǎo)數(shù)為0的位置移動(dòng)了一些����。
如果當(dāng)前所處的位置是在最低點(diǎn)的右邊,那么就是減去一個(gè)正值(導(dǎo)數(shù)為正)�,相當(dāng)于往左移動(dòng)了一些距離,也是朝著導(dǎo)數(shù)為0的位置移動(dòng)了一些�����。
這就是梯度下降最本質(zhì)的思想�。
那么到底一次該移動(dòng)多少呢?就是又導(dǎo)數(shù)前面的系數(shù)α來決定的�����。
現(xiàn)在我們?cè)賮砜刺荻认陆档氖阶?�,如果寫成矩陣?jì)算的形式(使用隱式循環(huán)來實(shí)現(xiàn)),那么就有:
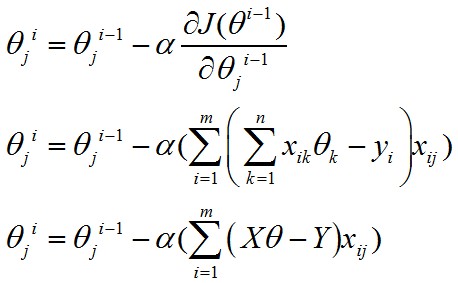
這邊會(huì)有點(diǎn)棘手���,因?yàn)閖確定時(shí)�,xij為一個(gè)數(shù)值(即�����,樣本的第j個(gè)分量)��,Xθ-Y為一個(gè)m*1維的列向量(暫時(shí)稱作“誤差向量”)�����。
括號(hào)里面的部分就相當(dāng)于:
第1個(gè)樣本第j個(gè)分量*誤差向量 + 第2個(gè)樣本第j個(gè)分量*誤差向量 + ... + 第m個(gè)樣本第j個(gè)分量*誤差向量
我們來考察一下式子中各個(gè)部分的矩陣形式����。
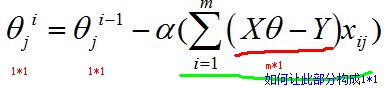
當(dāng)j固定時(shí)����,相當(dāng)于對(duì)樣本空間做了一個(gè)縱向切片,即:

那么此時(shí)的xij就是m*1向量�,所以為了得到1*1的形式,我們需要拼湊 (1*m)*(m*1)的矩陣運(yùn)算��,因此有:

如果把θ向量的每個(gè)分量統(tǒng)一考慮,則有:
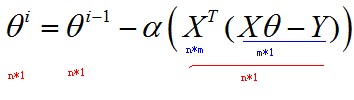
關(guān)于θ向量的不斷更新的終止條件����,一般以誤差范圍(如95%)或者迭代次數(shù)(如5000次)進(jìn)行設(shè)定。
梯度下降的有點(diǎn)是:
不像矩陣解法那么需要空間(因?yàn)榫仃嚱夥ㄐ枰缶仃嚨哪妫?/span>
缺點(diǎn)是:如果遇上非凸函數(shù)���,可能會(huì)陷入局部最優(yōu)解中�����。對(duì)于這種情況�,可以嘗試幾次隨機(jī)的初始θ�����,看最后convergence時(shí)���,得到的向量是否是相似的�。
(3)下圖給出了線性����、二次和七次擬合的效果圖。請(qǐng)說明進(jìn)行數(shù)據(jù)擬合時(shí),需要考慮哪些問題�����。在本例中�����,你選擇哪種擬合函數(shù)��。(8分)
因?yàn)槭窃诰W(wǎng)上找的題目����,沒有看到圖片是長(zhǎng)什么樣。大致可能有如下幾種情況����。
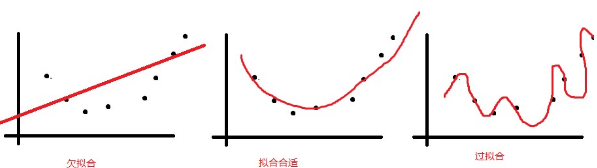
如果是如上三幅圖的話,當(dāng)然是選擇中間的模型�。
欠擬合的發(fā)生一般是因?yàn)榧僭O(shè)的模型過于簡(jiǎn)單。而過擬合的原因則是模型過于復(fù)雜且訓(xùn)練數(shù)據(jù)量太少�。
對(duì)于欠擬合,可以增加模型的復(fù)雜性����,例如引入更多的特征向量�����,或者高次方模型。
對(duì)于過擬合����,可以增加訓(xùn)練的數(shù)據(jù),又或者增加一個(gè)L2 penalty���,用以約束變量的系數(shù)以實(shí)現(xiàn)降低模型復(fù)雜度的目的���。
L2 penalty就是:
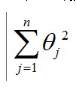
(注意不要把常數(shù)項(xiàng)系數(shù)也包括進(jìn)來,這里假設(shè)常數(shù)項(xiàng)是θ0)
另外常見的penalty還有L1型的:
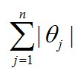
(L1型的主要是做稀疏化�,即sparsity)
兩者為什么會(huì)有這樣作用上的區(qū)別可以找一下【統(tǒng)計(jì)之都】上的相關(guān)文章看一下。我也還沒弄懂底層的原因是什么����。
(4)給出實(shí)驗(yàn)方案(8分)
2013網(wǎng)易實(shí)習(xí)生招聘 崗位:數(shù)據(jù)挖掘工程師
一、問答題
a) 欠擬合和過擬合的原因分別有哪些�����?如何避免�����?
欠擬合:模型過于簡(jiǎn)單;過擬合:模型過于復(fù)雜�����,且訓(xùn)練數(shù)據(jù)太少����。
b) 決策樹的父節(jié)點(diǎn)和子節(jié)點(diǎn)的熵的大小���?請(qǐng)解釋原因��。
父節(jié)點(diǎn)的熵>子節(jié)點(diǎn)的熵
c) 衡量分類算法的準(zhǔn)確率���,召回率,F(xiàn)1值�。

d) 舉例序列模式挖掘算法有哪些?以及他們的應(yīng)用場(chǎng)景���。
DTW(動(dòng)態(tài)事件規(guī)整算法):語音識(shí)別領(lǐng)域��,判斷兩端序列是否是同一個(gè)單詞���。
Holt-Winters(三次指數(shù)平滑法):對(duì)時(shí)間序列進(jìn)行預(yù)測(cè)�。時(shí)間序列的趨勢(shì)����、季節(jié)性���。
Apriori
Generalized Sequential Pattern(廣義序貫?zāi)J?
PrefixSpan
二�����、計(jì)算題
1) 給你一組向量a��,b
a) 計(jì)算二者歐氏距離
(a-b)(a-b)T
即:
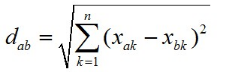
b) 計(jì)算二者曼哈頓距離
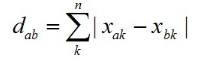
2) 給你一組向量a��,b���,c,d
a) 計(jì)算a���,b的Jaccard相似系數(shù)
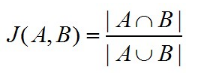
b) 計(jì)算c��,d的向量空間余弦相似度
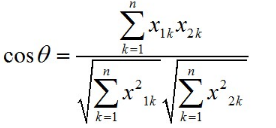
c) 計(jì)算c���、d的皮爾森相關(guān)系數(shù)
即線性相關(guān)系數(shù)�����。

或者
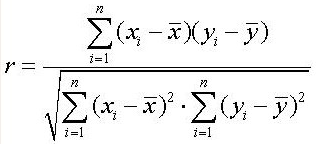
三�����、(題目記得不是很清楚)
一個(gè)文檔-詞矩陣�����,給你一個(gè)變換公式tfij’=tfij*log(m/dfi)�����;其中tfij代表單詞i在文檔f中的頻率����,m代表文檔數(shù)���,dfi含有單詞i的文檔頻率�����。
1) 只有一個(gè)單詞只存在文檔中���,轉(zhuǎn)換的結(jié)果����?(具體問題忘記)
2) 有多個(gè)單詞存在在多個(gè)文檔中���,轉(zhuǎn)換的結(jié)果?(具體問題忘記)
3) 公式變換的目的���?
四����、推導(dǎo)樸素貝葉斯分類P(c|d)�,文檔d(由若干word組成),求該文檔屬于類別c的概率��,
并說明公式中哪些概率可以利用訓(xùn)練集計(jì)算得到���。
五���、給你五張人臉圖片����。
可以抽取哪些特征���?按照列出的特征�����,寫出第一個(gè)和最后一個(gè)用戶的特征向量���。
六、考查ID3算法����,根據(jù)天氣分類outlook/temperature/humidity/windy。(給你一張離散型
的圖表數(shù)據(jù)��,一般學(xué)過ID3的應(yīng)該都知道)
a) 哪一個(gè)屬性作為第一個(gè)分類屬性�?
b) 畫出二層決策樹。
七�����、購(gòu)物籃事物(關(guān)聯(lián)規(guī)則)
一個(gè)表格:事物ID/購(gòu)買項(xiàng)�。
1) 提取出關(guān)聯(lián)規(guī)則的最大數(shù)量是多少�����?(包括0支持度的規(guī)則)
2) 提取的頻繁項(xiàng)集的最大長(zhǎng)度(最小支持>0)
3) 找出能提取出4-項(xiàng)集的最大數(shù)量表達(dá)式
4) 找出一個(gè)具有最大支持度的項(xiàng)集(長(zhǎng)度為2或更大)
5) 找出一對(duì)項(xiàng)a�,b�,使得{a}->和���->{a}有相同置信度��。
八、一個(gè)發(fā)布優(yōu)惠劵的網(wǎng)站����,如何給用戶做出合適的推薦?有哪些方法����?設(shè)計(jì)一個(gè)合適的系
統(tǒng)(線下數(shù)據(jù)處理,存放�,線上如何查詢?)
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試�����,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材��,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫(kù)����,點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情;
? 想了解CDA考試含金量��,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330