SPSS分析技術(shù):二元logistic回歸
今天我們介紹另外一種應(yīng)用范圍更加廣泛的回歸分析方法:二元logistic回歸���。
應(yīng)用背景
數(shù)據(jù)分析技術(shù)在實(shí)際應(yīng)用過(guò)程中���,大量的研究都需要對(duì)只有“是”和“否”兩種選擇的結(jié)論給予解釋��,即研究中的因變量并不是常用的定距變量和定序變量�����,而是僅有兩種狀態(tài)的二分變量�。針對(duì)這種變量的回歸分析稱為二元Logistic回歸分析技術(shù)���。二元Logistic回歸分析是一種多元回歸分析��,這里的二元不是自變量個(gè)數(shù)����,而是指因變量的取值范圍,與多元回歸分析中的多元代表自變量個(gè)數(shù)截然不同����。
例如,作為汽車銷售商�����,其最關(guān)心的問(wèn)題是顧客是否會(huì)購(gòu)買(mǎi)某種品牌小汽車��,為了預(yù)測(cè)未來(lái)顧客的購(gòu)車可能性�����,汽車銷售商可以采集半年來(lái)咨詢?cè)摲N小汽車的顧客的基本信息���,以這些顧客最終是否購(gòu)買(mǎi)了小汽車作為因變量�,以顧客的職業(yè)����、文化程度、收入情況���、民族���、宗教��、喜好等因素作為自變量���、借助二元Logistic回歸分析技術(shù),構(gòu)造顧客購(gòu)買(mǎi)此品牌小汽車的回歸方程����。然后,汽車銷售商就可以以此回歸方程式為依據(jù)����,對(duì)前來(lái)咨詢的顧客做出初步判定���。這就是二元Logistic回歸分析的主要目的��。
理論基礎(chǔ)
在因變量取值只能是0和1時(shí)����,雖然從理論上講無(wú)法直接使用一般多元線性回歸模型建模�,但是如果借助普通多元線性回歸模型研究該問(wèn)題����,則在大量個(gè)案的情況下�����,所獲得的因變量的均值將是因變量取“真”值時(shí)的概率�。由此,可以得到初步想法:把因變量取值為1的概率作為新的因變量���,把二元回歸分析轉(zhuǎn)化為針對(duì)新因變量的普通多元線性回歸���。
由于在二元回歸模型中,因變量取值為1的概率P的值應(yīng)在0~1之間�����。在借助普通多元線性回歸模型解釋二元回歸中的概率P時(shí)���,模型中的因變量與概率值之間的關(guān)系是線性的�����,然而在實(shí)際應(yīng)用中��,這個(gè)概率值與因變量之間往往是一種非線性關(guān)系��。例如�,在一定的條件范圍內(nèi),購(gòu)買(mǎi)新型手機(jī)的概率與收入增長(zhǎng)情況呈正比���,但這種情況并不穩(wěn)定�,經(jīng)常是在收入增長(zhǎng)初期���,購(gòu)買(mǎi)新手機(jī)的概率增長(zhǎng)得比較緩慢��,當(dāng)收入增長(zhǎng)到一定水平后��,購(gòu)買(mǎi)新手機(jī)的概率會(huì)快速增長(zhǎng)���,但當(dāng)收入增長(zhǎng)到某個(gè)數(shù)額后����,購(gòu)買(mǎi)新手機(jī)的概率人會(huì)增長(zhǎng),但增長(zhǎng)速度已經(jīng)逐漸變緩���,對(duì)這樣的概率P進(jìn)行必要的轉(zhuǎn)化�����,使之符合常規(guī)線性模型��,例如下式:

上式就是Logistic函數(shù)����,它是在增長(zhǎng)函數(shù)的基礎(chǔ)上,針對(duì)二元回歸中的概率P值所做的專門(mén)變形�����。如果將上式推廣到多元線性回歸公式�����,就形成了針對(duì)二分變量的多元回歸分析�。
參數(shù)求解
二元Logistic回歸方程的參數(shù)求解采用極大似然估計(jì)法。極大似然估計(jì)是一種在總體分布密度函數(shù)和樣本信息的基礎(chǔ)上�����,求解模型中未知參數(shù)估計(jì)值的方法���,它基于總體的分布密度函數(shù)來(lái)構(gòu)造一個(gè)包含未知參數(shù)的似然函數(shù)�����,并求解在似然函數(shù)值最大情況下的未知參數(shù)的估計(jì)值�����。在這一原則下得到的模型��,其產(chǎn)生的樣本數(shù)據(jù)的分布與總體分布相近的可能性最大�����。因此����,似然函數(shù)的函數(shù)值實(shí)際上也是一種概率值,它反映了在所確定擬合模型為真時(shí)�����,該模型能夠較好的擬合樣本數(shù)據(jù)的可能性���,所以似然函數(shù)的取值也是0~1。
Logistic回歸系數(shù)顯著性檢驗(yàn)的目的是逐個(gè)檢驗(yàn)?zāi)P椭懈鱾€(gè)自變量是否與LogitP有顯著的線性關(guān)系,對(duì)于解釋LogitP是否有重要貢獻(xiàn)�。在二元Logistic回歸分析中,對(duì)回歸系數(shù)的判定統(tǒng)計(jì)量是Wald統(tǒng)計(jì)量�����。Wald統(tǒng)計(jì)量的原理與普通線性回歸分析中的T值的概念相似����。Wald值越大,表示回歸系數(shù)的影響力越顯著��。
二元Logistic回歸分析也是一種多元回歸分析���,在面臨多個(gè)自變量時(shí)�,同樣存在著自變量的篩選標(biāo)準(zhǔn)和自變量進(jìn)入方程的順序問(wèn)題�。
自變量篩選方法
極大似然估計(jì)的方法;極大似然估計(jì)方法�����,即基于極大似然估計(jì)算法對(duì)每個(gè)待選自變量進(jìn)行評(píng)價(jià)���,以便確定該自變量是否進(jìn)入方程�。似然比檢驗(yàn)的原理是通過(guò)分析模型中自變量的變化對(duì)似然比的影響來(lái)檢驗(yàn)增加或減少自變量的值是否對(duì)因變量有統(tǒng)計(jì)學(xué)上的顯著意義。
采用Wald檢驗(yàn)方法�;這是一種類似T檢驗(yàn)的自變量篩選方法,根據(jù)二元數(shù)據(jù)處理的特點(diǎn)����,人們對(duì)T檢驗(yàn)的算法進(jìn)行了擴(kuò)展,剔提出了Wald統(tǒng)計(jì)量����,通過(guò)檢查Wald統(tǒng)計(jì)量的強(qiáng)度,以確定相對(duì)應(yīng)的自變量能否進(jìn)入方程���。
采取比分檢驗(yàn)方式�����;在已經(jīng)設(shè)計(jì)好的回歸模型的基礎(chǔ)上增加一個(gè)變量���,并假設(shè)新變量的回歸系數(shù)為0,。此時(shí)以似然函數(shù)的一階偏導(dǎo)和信息矩陣的乘積作為比分檢驗(yàn)的統(tǒng)計(jì)量S����。在樣本量較大時(shí),S服從自由度為檢驗(yàn)參數(shù)個(gè)數(shù)的卡方分布����。然后借助卡方分布的原理對(duì)自變量實(shí)施判定。
自變量進(jìn)入方程順序
直接進(jìn)入方式����;所謂直接進(jìn)入,就是所有給定自變量都進(jìn)入到回歸方程中�����。在最終的回歸方程中�����,應(yīng)該包含全部自變量���。直接進(jìn)入方式的最大缺點(diǎn)是需要用戶根據(jù)回歸分析的輸出表格��,人工判定回歸方程的質(zhì)量和各個(gè)回歸系數(shù)的質(zhì)量�����。
逐個(gè)進(jìn)入法�����;逐個(gè)進(jìn)入發(fā)�����,也叫向前法��。其思路是對(duì)于給定自變量��,按照其檢驗(yàn)概率的顯著性程度選擇最優(yōu)的自變量�,把它依次加入到方程中,然后按照選定的篩選技術(shù)進(jìn)行自變量的判定�。在SPSS的二元Logistic回歸分析中,對(duì)于自變量的篩選�����,在向前方式下�����,分別有條件���、似然和Wald三種篩選方法����。
向后,逐漸剔除法����;逐個(gè)剔除法的基本思路是對(duì)于給定自變量,先全部進(jìn)入方程�,按照其檢驗(yàn)概率P的顯著性水平一次選擇最差的自變量�,從方程中剔除。在SPSS的二元Logistic回歸分析中��,對(duì)于自變量的剔除����,在向后方式下,也分別有條件�、LR和Wald三種篩選技術(shù)。
回歸方程質(zhì)量評(píng)價(jià)
二元Logistic回歸分析也提供了類似于線性回歸的判定系數(shù)R方��,F(xiàn)值和Sig值的專門(mén)數(shù)據(jù)指標(biāo)��。
判定系數(shù)����;在二元Logistic回歸分析中,衡量其擬合程度高低的指標(biāo)是二元回歸分析的判定系數(shù)�,它叫“Cox&Snell
R方”統(tǒng)計(jì)量����,這是一個(gè)與普通線性回歸中的判定系數(shù)R方作用相似的統(tǒng)計(jì)量���。但是��,由于它的取值范圍不易確定�����,因此在使用時(shí)并不方便����。為了解決這個(gè)問(wèn)題��,SPSS引入了NagelkerteR方統(tǒng)計(jì)量�����,它是對(duì)CS
R方的修正���,取值范圍為0~1����。它的值越接近1,越好���。
回歸系數(shù)顯著性及其檢驗(yàn)概率���;在二元Logistic回歸分析中,對(duì)于納入方程的每個(gè)自變量����,都可以計(jì)算其Wald值(相當(dāng)于線性回歸中的T值)���。利用Wald值��,可以判定該自變量對(duì)回歸方程的影響力����,通常Walds值應(yīng)大于2�����。另外����,與Walds值配套的檢驗(yàn)概率Sig值也能發(fā)揮同樣的作用�����。
錯(cuò)判矩陣����;錯(cuò)判矩陣是一個(gè)二維表格�,用于直觀的顯示出二元Logistic回歸中原始觀測(cè)數(shù)據(jù)與預(yù)測(cè)值之間的吻合程度。由于二元Logistic回歸的因變量只有2個(gè)取值��,所以錯(cuò)判矩陣的結(jié)構(gòu)很簡(jiǎn)單�。如下表:

在錯(cuò)判矩陣中,A+D的值占總數(shù)的比例越大�����,說(shuō)明二元回歸的吻合程度越高���,回歸方程的質(zhì)量越高��。
Hosmer-Lemeshow擬合度檢驗(yàn)�����;對(duì)于自變量較多且多為定距型數(shù)據(jù)的二元回歸分析��,通常在執(zhí)行回歸分析時(shí)把選項(xiàng)對(duì)話框中的【Hosmer-Lemeshow擬合度】復(fù)選框選中��,以便使系統(tǒng)自動(dòng)輸出其統(tǒng)計(jì)量���。在擬合度表格中����,檢驗(yàn)概率值越大���,表示回歸方程與觀測(cè)值的差異性越小��,回歸方差的你和程度越高���。
案例分析
現(xiàn)在有一份某個(gè)大學(xué)的學(xué)生資料���,請(qǐng)以是否喜歡數(shù)學(xué)為因變量����,以性別��、愛(ài)好、專業(yè)和數(shù)學(xué)成績(jī)?yōu)樽宰兞块_(kāi)展回歸分析����,并解釋回歸分析結(jié)果。
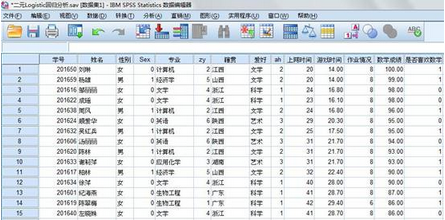
SPSS分析步驟
1���、利用菜單【轉(zhuǎn)換】-【重新編碼為不同變量】���,將性別、專業(yè)和愛(ài)好進(jìn)行數(shù)值化編碼�。
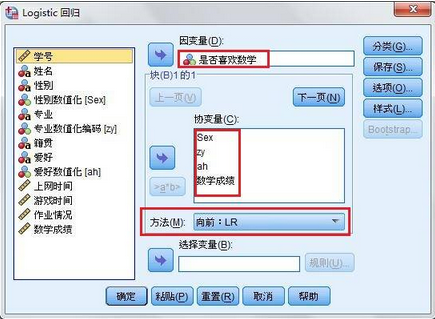
2、利用菜單【分析】-【回歸】-【二元Logistic】命令�����,啟動(dòng)Logistic回歸對(duì)話框��;如下圖所示����,將變量選入不同方框;同時(shí)在【方法】欄選擇“向前 LR”����;
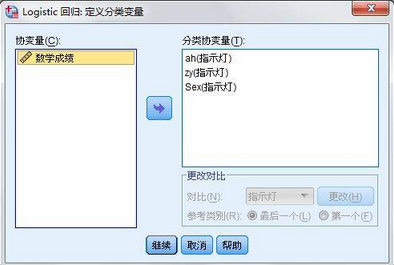
3�����、選中【分類】菜單�����,將定類變量Sex���、zy和ah選中,選中的作用是使這些變量在計(jì)算過(guò)程中成為不被關(guān)注大小值的啞元���,這些變量的每一項(xiàng)都會(huì)獨(dú)立參與到回歸分析當(dāng)中��。所有變量中����,只有數(shù)學(xué)成績(jī)是定距變量�����。
4�����、點(diǎn)擊【確定】�����,進(jìn)行二元Logistic回歸分析����,獲得回歸結(jié)果。
結(jié)果解讀
由于選擇的是向前LR�,所以分析首先是對(duì)每一個(gè)變量進(jìn)行檢驗(yàn),得出Wald值和檢驗(yàn)概率Sig����。然后根據(jù)檢驗(yàn)概率從低到高逐個(gè)代入回歸方程進(jìn)行迭代運(yùn)算,迭代運(yùn)算最高為20次�。我們接下來(lái)直接分析迭代運(yùn)算的最終結(jié)果:
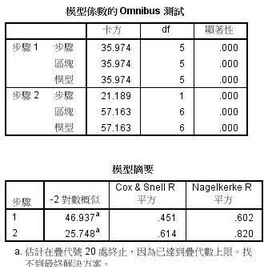
第一個(gè)表格顯示最后產(chǎn)生兩個(gè)回歸模型,顯著性都為0.000�,小于0.05,表示模型有效��,但是還不能說(shuō)明模型的質(zhì)量好壞����。第二個(gè)表格包含了NagelkerkeR方結(jié)果,兩個(gè)值都大于0.4�,表示質(zhì)量可以接受�����,但是第二個(gè)模型的R方值為0.820�,很接近1��,說(shuō)明模型二的質(zhì)量高于模型一�。
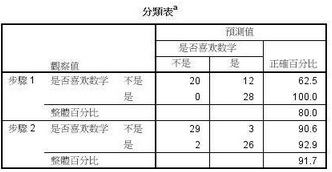
上圖是錯(cuò)判矩陣,從結(jié)果來(lái)看����,模型1的判斷正確率為80%,而模型2的為91.7%���。因此���,模型1的判定率明顯優(yōu)于模型2。
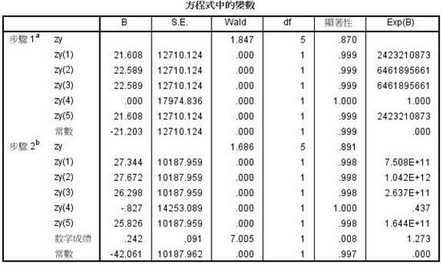
最后這個(gè)表格顯示進(jìn)入到方程中的自變量���。B列是回歸方程的系數(shù)����。Wald是各自變量對(duì)應(yīng)的Wald值�����,相當(dāng)于線性回歸中的t值��,反映該自變量在方程中的價(jià)值����。顯著性水平小于0.05,代表影響力大�,但是使用極大似然法時(shí)會(huì)出現(xiàn)顯著性大于0.05的情況,需要謹(jǐn)慎對(duì)待�。
推薦學(xué)習(xí)書(shū)籍
《CDA一級(jí)教材》適合CDA一級(jí)考生備考,也適合業(yè)務(wù)及數(shù)據(jù)分析崗位的從業(yè)者提升自我�。完整電子版已上線CDA網(wǎng)校,累計(jì)已有10萬(wàn)+在讀~

免費(fèi)加入閱讀:https://edu.cda.cn/goods/show/3151?targetId=5147&preview=0
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試�����,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情�;
? 想學(xué)習(xí)CDA考試教材,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫(kù),點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情�����;
? 想了解CDA考試含金量,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330