1��、問題與數(shù)據(jù)
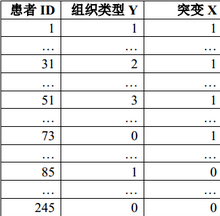
為了探討基因X突變與惡性腫瘤Y不同組織類型發(fā)生風險的關系�,某醫(yī)生設計了一項病例對照研究。該醫(yī)生納入所在科室一年收治的145名該惡性腫瘤患者����,并從醫(yī)院體檢數(shù)據(jù)庫中隨機選擇了100名未患該腫瘤的體檢者作為對照。相關信息整理成表1:
表1 各病例組織類型與突變情況
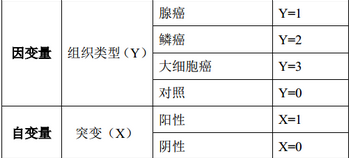
變量賦值情況如表2:
表2 變量及變量賦值情況
2���、對數(shù)據(jù)結構的分析
該研究中,“病例”與“對照”的關系不再是簡單的“患病”與“不患病”�����,而是病例分為四類(本例中包含對照組共四類)��,且各類別無次序關系。或者說�����,因變量Y不再是二分類的����,而是無序多分類的���。通過無序多分類的Logistic回歸分析可以將三種不同組織類型的病例分別與對照組進行對比���,分別得到基因X突變與三種腫瘤組織類型的暴露-風險關系��。
3���、SPSS分析方法
A. 數(shù)據(jù)錄入SPSS
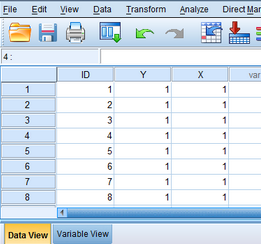
若數(shù)據(jù)格式如表1所示���,則首先在SPSS變量視圖(Variable View)中新建三個變量:ID代表患者編號����,Y代表組織類型�,X代表是否突變,賦值參考表2.
然后在數(shù)據(jù)視圖(Data View)中錄入數(shù)據(jù)��。
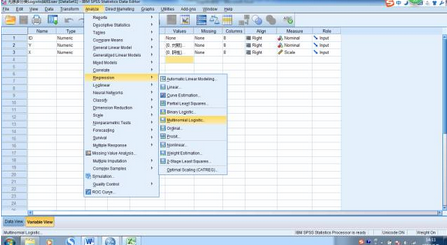
B. 選擇Analyze → Regression → Multinomial Logistic
C. 選項設置
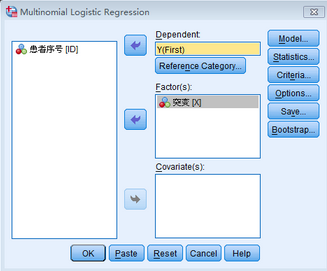
將變量Y選入因變量(Dependent)位置�����,變量X選入因子(Factors)位置���。如果自變量中還有連續(xù)型變量���,則需要放入?yún)f(xié)變量(Covariate)位置。由于因變量Y有多個分類����,而無序多分類Logistic回歸的原理是先指定一個類別為參考類別,然后將其他類別分別與參考類別對比����。故需點擊Reference
Category設置參考類別(本例中作為參考類別的為對照組)����。
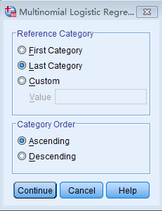
SPSS默認選擇因變量賦值中按升序排列后最后類別(即賦值最大者)為參考類別(即對照組)����,而本研究中參考類別Y賦值為0�,故可以點擊First Category 或直接在Custom中輸入0,點擊Continue����。
如果要分析的自變量不止一個,且要分析不同自變量之間的交互作用���,則需點擊Model進行設置����,否則無需進行設置�����。
Statistics��、Criteria等維持默認設置即可���。點擊OK�,SPSS生成分析結果。
4���、結果解讀
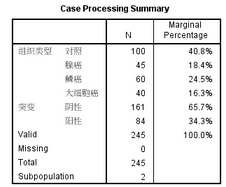
Case Processing Summary 對數(shù)據(jù)進行了總結����。
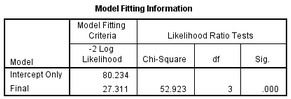
Model
Fitting Information 給出的模型擬合好壞的信息�。其中-2Log
Likelihood值越小越好,從結果中可以看出��,加入自變量后的模型比只有常數(shù)項的模型擬合要好(27.311<80.234)�����,似然比檢驗(Likelihood
Ratio Tests)結果顯示這種模型的改善是有統(tǒng)計學意義的(P<0.001)�����,說明自變量X的加入是有統(tǒng)計學意義的�����。
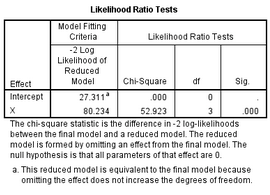
Likelihood Ratio Tests 與Model Fitting Information給出的信息一致���,不再贅述�����。
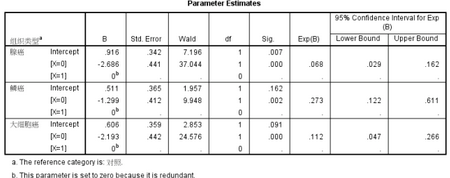
Parameter Estimates表格給出了參數(shù)估計值��。首先在表格的注釋a說明了此次回歸所使用的參考類別為“對照”�����,即數(shù)據(jù)中的對照組���。表中給出了三種組織類型腫瘤分別與對照相比的自變量X的回歸系數(shù),且三個系數(shù)均有統(tǒng)計學意義����。
以腺癌組為例,X=0相比于X=1�,系數(shù)值Exp(B)為0.068,說明基因X未突變者患腺癌的風險是突變者患腺癌風險的0.068倍�,將0.068取倒數(shù)即為基因X突變者患腺癌風險是未突變者的1/0.068=14.71倍,P(Sig.)<0.001��,說明差異有統(tǒng)計學意義��。其他兩組系數(shù)解釋同。如果想直接得到X=1 對比 X=0的結果���,可以將自變量X當作協(xié)變量放入Covariate中����,而不作為因子進行分析����。或者將自變量反過來�,如突變陽性時,X=0���;突變陰性時���,X=1。
5����、結果匯總
基因X突變患者相比于未突變患者,其發(fā)生某惡性腫瘤類型為腺癌����、鱗癌和大細胞癌的風險分別為14.71(1/0.068�,P<0.001)����,3.66(1/0.273,P=0.002)�,8.93(1/0.112�����,P<0.001)倍�,均有統(tǒng)計學意義。
6���、總結與拓展
1)SPSS結果中會給出Pseudo R-Square�,即偽R方����,或假R方,與普通線性回歸中衡量模型擬合好壞的R方概念類似���。但由于Logistic回歸中因變量為分類變量����,其計算方法與普通線性回歸中的R方不同,其值一般較小��,可不予關注���。
2)無序多分類Logistic回歸并非只用于病例對照研究中����,只要分析時指定對照�����,且與指定的對照進行比較得出的回歸結果可以說明想探究的問題即可����。如在本研究中,若研究者關注的不是基因X突變對不同類別的腫瘤發(fā)生的風險情況�,而是基因X突變對三種類別腫瘤的發(fā)生風險是否有差異,以及差異的大小�����,那么就不需要納入對照��。
在本例分析中雖然我們可以在數(shù)值上看出基因X突變對三種類別腫瘤的發(fā)生風險是不同的�����,但無法從統(tǒng)計學上進行判斷,因為這種差異并沒有進行統(tǒng)計學檢驗��。要探討這種差異�����,可以將參考類別選為三種類別腫瘤中的一中����,如想比較腺癌和鱗癌的差異�����,則可選鱗癌組為對照���,這樣得出的回歸系數(shù)即為基因X突變引起兩種類別腫瘤發(fā)生風險的比值�。
3)實際應用中可能也需要調整一些混雜因素變量�����,若變量為分類型變量則放入因子位置�,若為連續(xù)型變量則放入?yún)f(xié)變量位置����,其分析和解釋與要分析的暴露變量是一致的�����。
4)可以把無序多分類Logistic回歸看作是多個二分類Logistic回歸的同時實現(xiàn)�。
7、無序多分類Logistic回歸適用條件
1)不限于病例對照類型�����;
2)因變量為分類變量��,分類大于兩個�����,且各分類之間并無次序關系�。
來CDA學業(yè)務數(shù)據(jù)分析師,SPSS理論結合實戰(zhàn)進行項目數(shù)據(jù)分析�����,助你成為從事數(shù)據(jù)采集���、清洗�、處理、分析并能制作業(yè)務報告����、提供決策的新型數(shù)據(jù)分析人才,點擊了解課程詳情�����!
數(shù)據(jù)分析師一定要了解的大廠入門券��,CDA數(shù)據(jù)分析師認證證書��!

CDA(數(shù)據(jù)分析師認證)�����,與CFA相似���,由國際范圍內(nèi)數(shù)據(jù)科學領域行業(yè)專家、學者及知名企業(yè)共同制定并修訂更新���,迅速發(fā)展成行業(yè)內(nèi)長期而穩(wěn)定的全球大數(shù)據(jù)及數(shù)據(jù)分析人才標準����,具有專業(yè)化、科學化���、國際化����、系統(tǒng)化等特性��。
同時�����,CDA全?����?荚嚥季趾驼J證體系已得到教育部直屬中國成人教育協(xié)會及大數(shù)據(jù)專業(yè)委員會認可�,并由為IBM、華為等提供全球認證服務的Pearson VUE面向全球提供靈活的考試服務���。
報名方式
登錄CDA認證考試官網(wǎng)注冊報名>>點擊報名
報名費用
Level Ⅰ:1200 RMB
Level Ⅱ:1700 RMB
Level Ⅲ:2000 RMB
考試地點
Level Ⅰ:中國區(qū)30+省市���,70+城市�����,250+考場��,考生可就近考場預約考試 >看看我所在的地哪里報名<
Level Ⅱ+Ⅲ:中國區(qū)30所城市���,北京/上海/天津/重慶/成都/深圳/廣州/濟南/南京/杭州/蘇州/福州/太原/武漢/長沙/西安/貴陽/鄭州/南寧/昆明/烏魯木齊/沈陽/哈爾濱/合肥/石家莊/呼和浩特/南昌/長春/大連/蘭州>看看我所在的地哪里報名<
報考條件
業(yè)務數(shù)據(jù)分析師 CDA Level I >了解更多<
? 報考條件:無要求。
? 考試時間:隨報隨考�����。
建模分析師 CDA Level II >了解更多<
? 報考條件(滿足任一即可):
1�、獲得CDA Level Ⅰ認證證書;
2����、本科及以上學歷�����,需從事數(shù)據(jù)分析相關工作1年以上����;
3�、本科以下學歷�,需從事數(shù)據(jù)分析相關工作2年以上。
? 考試時間:
一年四屆 3月�、6月、9月��、12月的最后一個周六�����。
大數(shù)據(jù)分析師 CDA Level II >了解更多<
? 報考條件(滿足任一即可):
1�����、獲得CDA Level Ⅰ認證證書��;
2����、本科及以上學歷,需從事數(shù)據(jù)分析相關工作1年以上����;
3、本科以下學歷,需從事數(shù)據(jù)分析相關工作2年以上���。
? 考試時間:
一年四屆 3月�、6月�����、9月��、12月的最后一個周六��。
數(shù)據(jù)科學家 CDA Level III >了解更多<
? 報考條件(滿足任一即可):
1����、獲得CDA Level Ⅱ認證證書;
2����、本科及以上學歷��,需從事數(shù)據(jù)分析相關工作3年以上�����;
3���、本科以下學歷����,需從事數(shù)據(jù)分析相關工作4年以上。
? 考試時間:
一年四屆 3月�、6月�、9月�����、12月的最后一個周六����。
(備注:數(shù)據(jù)分析相關工作不限行業(yè)�,可涉及統(tǒng)計,數(shù)據(jù)分析����,數(shù)據(jù)挖掘,數(shù)據(jù)庫���,數(shù)據(jù)管理����,大數(shù)據(jù)架構等內(nèi)容����。)
——熱門課程推薦:
想學習PYTHON數(shù)據(jù)分析與金融數(shù)字化轉型精英訓練營��,您可以點擊>>>“人才轉型”了解課程詳情�����;
想從事業(yè)務型數(shù)據(jù)分析師,您可以點擊>>>“數(shù)據(jù)分析師”了解課程詳情��;
想從事大數(shù)據(jù)分析師����,您可以點擊>>>“大數(shù)據(jù)就業(yè)”了解課程詳情�;
想成為人工智能工程師,您可以點擊>>>“人工智能就業(yè)”了解課程詳情;
想了解Python數(shù)據(jù)分析,您可以點擊>>>“Python數(shù)據(jù)分析師”了解課程詳情��;
想咨詢互聯(lián)網(wǎng)運營�,你可以點擊>>>“互聯(lián)網(wǎng)運營就業(yè)班”了解課程詳情;
想了解更多優(yōu)質課程����,請點擊>>>
推薦學習書籍
《CDA一級教材》適合CDA一級考生備考,也適合業(yè)務及數(shù)據(jù)分析崗位的從業(yè)者提升自我。完整電子版已上線CDA網(wǎng)校����,累計已有10萬+在讀~

免費加入閱讀:https://edu.cda.cn/goods/show/3151?targetId=5147&preview=0
CDA數(shù)據(jù)分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學習CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330