《數(shù)據(jù)分析專項練習題庫》
《CDA數(shù)據(jù)分析認證考試模擬題庫》
《企業(yè)數(shù)據(jù)分析面試題庫》
推薦學習書籍
《CDA一級教材》適合CDA一級考生備考,也適合業(yè)務及數(shù)據(jù)分析崗位的從業(yè)者提升自我��。完整電子版已上線CDA網(wǎng)校�����,累計已有10萬+在讀~

免費加入閱讀:https://edu.cda.cn/goods/show/3151?targetId=5147&preview=0
一��、單選題
1.統(tǒng)計圖中的散點圖主要用來( A )��。
A.觀察變量之間的相關關系 B.主要用來表示總體各部分所占的比例
C.主要用來表示次數(shù)分布 D.主要用來反映分類數(shù)據(jù)的頻數(shù)分布
2.抽樣誤差是指( D )
A.在調(diào)查過程中由于觀察��、測量等差錯所引起的誤差
B.人為原因所造成的誤差
C.在調(diào)查中違反隨機原則出現(xiàn)的系統(tǒng)誤差
D.隨機抽樣而產(chǎn)生的代表性誤差
3.檢查異常值常用的統(tǒng)計圖形:( B )
A、條形圖
B���、箱體圖
C��、帕累托圖
D�、線圖
4.線性回歸里的殘差分析不可能用于診斷( D )
A���、殘差獨立性
B����、變量分布
C��、異常值偵察
D����、最大迭代次數(shù)
5.擬合logistic回歸模型時有兩個分類變量,分別是Gender(水平為female和male)�,Class(水平為1 、2和3)����,下表為輸出結(jié)果,下面哪個選項的說法是正確的����?(C)
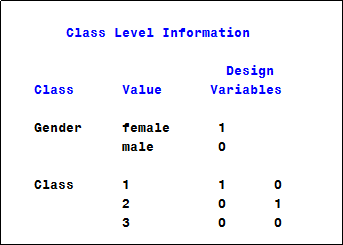
A.變量Gender和Class采用效應編碼
B.變量Gender采用引用編碼,引用水平為female
C.變量Class采用引用編碼�����,引用水平為3
D.變量Gender和Class采用全量編碼
6.因子分析的主要作用:( A )
A���、對變量進行降維
B����、對變量進行判別
C��、對變量進行聚類
D��、以上都不對
7.關于K-means 聚類過程正確的是:( A )
A��、使用的是迭代的方法
B����、均適用于對變量和個案的聚類
C、對變量進行聚類
D�、以上都不對
8.東北人養(yǎng)了一只雞和一頭豬。一天雞問豬:"主人呢?"豬說:"出去買蘑菇了����。"雞聽了撒丫子就跑。豬說:"你跑什么�?"雞叫道:“有本事主人買粉條的時候你小子別跑!"
以上對話體現(xiàn)了數(shù)據(jù)分析方法中的( A )
A. 關聯(lián) B. 聚類 C. 分類 D. 自然語言處理
9.已知甲班學生“統(tǒng)計學”的平均成績?yōu)?6分�����,標準差是12.8分�,乙班學生“統(tǒng)計學”的平均成績是90分,標準差是10.3分��,下列表述正確的是( A )
A. 乙班平均成績的代表性高于甲班
B. 甲班平均成績的代表性高于乙班
C. 甲��、乙兩班平均成績的代表性相同
D. 甲�����、乙兩班平均成績的代表性無法比較
10.根據(jù)樣本資料估計得出人均消費支出Y對人均收入X的回歸模型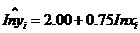 ��,表明人均收入每增加1%�����,人均消費支出將增加( B )
��,表明人均收入每增加1%�����,人均消費支出將增加( B )
A. 0.2% B. 0.75% C. 2% D. 7.5%
11.某企業(yè)根據(jù)對顧客隨機抽樣的信息得到對該企業(yè)產(chǎn)品表示滿意的顧客比率的95%置信度的置信區(qū)間是(56%,64%)���。下列正確的表述是( A )
A.總體比率的95%置信度的置信區(qū)間為(56%�,64%)
B.總體真實比率有95%的可能落在(56%�����,64%)中
C.區(qū)間(56%���,64%)有95%的概率包含了總體真實比率
D.由100次抽樣構造的100個置信區(qū)間中,約有95個覆蓋了總體真實比率
12.以下哪個語句可以將字符型數(shù)值date(示例:“2001-02-19”)轉(zhuǎn)換為數(shù)值類型? ( A )
A�����、INPUT(date�����,YYMMDD10.)
B����、PUT(date,YYMMDD10)
C��、INPUT(date,YYMMDD10.)
D��、PUT(date�����,YYMMDD10)
13. 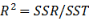 ���,取值范圍在[0,1]�,反映回歸曲線的擬合優(yōu)度���,當
���,取值范圍在[0,1]�,反映回歸曲線的擬合優(yōu)度���,當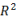 趨近于0�,則回歸曲線擬合優(yōu)度( B )
趨近于0�,則回歸曲線擬合優(yōu)度( B )
A.越好 B. 越差 C. 適中 D. 以上都不對
14.分析購買不同產(chǎn)品的頻次時��,使用以下哪個任務? ( D )
A����、列表數(shù)據(jù)
B、匯總表
C����、匯總統(tǒng)計量
D、單因子頻數(shù)
15.當你用跑步時間(RunTime)�、年齡(Age)��、跑步時脈搏(Run_Pulse)以及最高脈搏(Maximum_Pulse)作為預測變量來對耗氧量(Oxygen_Consumption )進行回歸時��,年齡(Age)的參數(shù)估計是-2.78. 這意味著什么�����?( B )
A�����、年齡每增加一歲,耗氧量就增大2.78.
B��、年齡每增加一歲,耗氧量就降低2.78.
C、年齡每增加2.78歲�,耗氧量就翻倍。
D�����、年齡每減少2.78歲��,耗氧量就翻倍�����。
16.ROC曲線凸向哪個角��,代表模型約理想����?( A )
A、左上角
B��、左下角
C��、右上角
D��、右下角
17.在所有兩位數(shù)(10-99)中任取一兩位數(shù)����,則此數(shù)能被2或3整除的概率為 ( B )
A. 6/5 B. 2/3 C. 83/100 D.均不對
18.對事件A和B,下列正確的命題是 ( D )
A.如A,B互斥����,則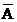 ,
,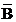 也互斥
也互斥
B. 如A,B相容�����,則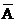 ��,
��,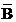 也相容
也相容
C. 如A,B互斥,且P(A)>0,P(B)>0,則A.B獨立
D. 如A,B獨立����,則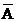 ,
,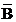 也獨立
也獨立
19.擲二枚骰子��,事件A為出現(xiàn)的點數(shù)之和等于3的概率為 ( B )
A.1/11 B. 1/18 C. 1/6 D. 都不對
20.A和B兩事件���,若 P(AUB)=0.8���,P(A)=0.2,P(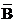 )=0.4 則下列 ( B )成立�。
)=0.4 則下列 ( B )成立�。
A. P(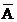
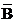 )=0.32 B. P(
)=0.32 B. P(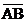 )=0.2
)=0.2
C. P(AB)=0.4 D. P(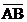 )=0.48
)=0.48
21.隨機地擲一骰子兩次�,則兩次出現(xiàn)的點數(shù)之和等于8的概率為 ( C )
A. 3/36 B. 4/36 C. 5/36 D. 2/36
22.抽樣推斷中,可計算和控制的誤差是 ( D )
A.登記誤差 B.系統(tǒng)性誤差(偏差)
C.抽樣實際誤差 D.抽樣平均誤差
23.假設檢驗中顯著性水平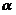 是 ( B )
是 ( B )
A.推斷時犯取偽錯誤的概率 B.推斷時犯取偽棄真的概率
C.正確推斷的概率 D.推斷時視情況而定
24.抽樣調(diào)查中��,無法消除的誤差是 ( A )
A.隨機誤差 B.工作誤差 C.登記誤差 D.偏差
25.當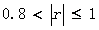 時�,兩個相關變量 ( C )
時�,兩個相關變量 ( C )
A.低度相關 B.中度相關
C.高度相關 D.不相關
26.描述一組對稱(或正態(tài))分布資料的離散趨勢時,最適宜選擇的指標是(B)
A.極差 B.標準差 C.均數(shù) D.變異系數(shù)
27.以下指標中那一項可用來描述計量資料離散程度(D)
A.算術均數(shù) B.幾何均數(shù) C.中位數(shù) D.極差
28.偏態(tài)分布資料宜用下面那一項描述其分布的集中趨勢(C)
A.算術均數(shù) B.標準差 C.中位數(shù) D.四分位數(shù)間距
29.下面那一項可用于比較身高和體重的變異度(C)
A.方差 B.標準差 C.變異系數(shù) D.全距
30.正態(tài)曲線下�,橫軸上從均數(shù)到+∞的面積為(C)
A.97.5% B.95% C.50% D.5%
31.橫軸上,標準正態(tài)曲線下從0到1.96的面積為: (D)
A.95% B.45% C.97.5% D.47.5%
32.下面那一項分布的資料,均數(shù)等于中位數(shù)��。(D)
A.對數(shù)正態(tài) B.左偏態(tài) C.右偏態(tài) D.正態(tài)
33.K-均值類別偵測要求輸入的數(shù)據(jù)類型必須是( B )��。
A整型 B數(shù)值型 C字符型 D邏輯型
34.某一特定的X水平上,總體Y分布的離散度越大���,即σ2越大��,則( A )����。
A.預測區(qū)間越寬���,精度越低 B.預測區(qū)間越寬��,預測誤差越小
C 預測區(qū)間越窄����,精度越高 D.預測區(qū)間越窄�����,預測誤差越大
35.如果X和Y在統(tǒng)計上獨立��,則相關系數(shù)等于( C )�����。
A.1 B.-1 C.0 D.∞
36.根據(jù)決定系數(shù)R2與F統(tǒng)計量的關系可知,當R2=1時�����,有( D )����。
A.F=1 B.F=-1 C.F=0 D.F=∞
37.假設兩變量線性相關,兩變量是等距或等比的數(shù)據(jù)���,但不呈正態(tài)分布�,計算它們的相關系數(shù)時應選用( B )��。
A. 積差相關 B.斯皮爾曼等級相關
C.二列相關 D.點二列相關
38.回歸模型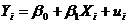 中����,關于檢驗
中����,關于檢驗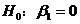 所用的統(tǒng)計量
所用的統(tǒng)計量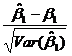 ��,下列說法正確的是( D )�。
��,下列說法正確的是( D )�。
A.服從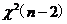 B.服從
B.服從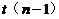
C.服從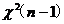 D.服從
D.服從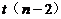
39.下面有關HAVING子句描述錯誤的是(B)。
A:HAVING子句必須與GROUP BY 子句同時使用����,不能單獨使用
B:使用HAVING子句的同時不能使用WHERE子句
C:使用HAVING子句的同時可以使用WHERE子句
D:使用HAVING子句的作用是限定分組的條件
40.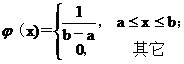 是( C )分布的密度函數(shù)��。
是( C )分布的密度函數(shù)��。
A.指數(shù) B. 二項 C. 均勻 D. 泊松
41.根據(jù)判定系數(shù)R2與F統(tǒng)計量的關系可知�,當R2=1時有( C )�。
A.F=1 B.F=-1 C.F=∞ D.F=0
42.在SQL查詢時,使用WHERE子句指出的是(C)�。
A:查詢目標
B:查詢結(jié)果
C:查詢條件
D:查詢視圖
43.SQL查詢語句中HAVING子句的作用是(C)。
A:指出分組查詢的范圍
B:指出分組查詢的值
C:指出分組查詢的條件
D:指出分組查詢的字段
44.SQL的數(shù)據(jù)操作語句不包括(D)����。
A:INSERT
B:UPDATE
C:DELETE
D:CHANGE
45.SQL語句中查詢條件短語的關鍵字是(A)。
A:WHERE
B:FOR
C:WHILE
D:CONDITION
46.SQL語句中修改表結(jié)構的命令是(C)�����。
A:MODIFY TABLE
B:MODIFY STRUCTURE
C:ALTER TABLE
D:ALTER STRUCTURE
47.SQL語句中刪除表的命令是(A)���。
A:DROP TABLE
B:DELETE TABLE
C:ERASE TABLE
D:DELETE DBF
二��、多選題
48.相關有以下幾種(ABC)����。
A.正相關 B.負相關 C.零相關 D.常相關
49.相關系數(shù)的取值可以是(ABC)����。
A. 0 B.-1 C. 1 D. 2
50.某種產(chǎn)品的生產(chǎn)總費用2003年為50萬元���,比2002年多2萬元,而單位產(chǎn)品成本2003年比2002年降低5%�����,則( ACDE )
A����、生產(chǎn)費用總指數(shù)為104.17% B、生產(chǎn)費用指數(shù)為108.56%
C����、單位成本指數(shù)為95% D、產(chǎn)量指數(shù)為109.65%
E���、由于成本降低而節(jié)約的生產(chǎn)費用為2.63萬元
51.三個地區(qū)同一種商品的價格報告期為基期的108%�����,這個指數(shù)是( BE )
A、個體指數(shù) B����、總指數(shù) C���、綜合指數(shù)
D、平均數(shù)指數(shù) E����、質(zhì)量指標指數(shù)
52.有關數(shù)據(jù)庫的說法正確的是(ABCD)
A.元數(shù)據(jù)是描述數(shù)據(jù)的數(shù)據(jù)
B.使用索引可以快速訪問數(shù)據(jù)庫中的數(shù)據(jù),所以可以在數(shù)據(jù)庫中盡量多的建立索引
C.數(shù)據(jù)庫中一行叫做記錄
D.數(shù)據(jù)庫中的每一個項目叫做字段
53.統(tǒng)計數(shù)據(jù)按來源分類�����,可以分為(BD)
A.類別數(shù)據(jù) B.二手數(shù)據(jù)
C.序列數(shù)據(jù) D.一手數(shù)據(jù)
E.數(shù)值數(shù)據(jù)
53.以下哪些變量代表RFM方法中的M:( AB )
A.最近3期境外消費金額
B.最近6期網(wǎng)銀平均消費金額
C.信用卡的消費額度
D.距最近一次逾期的月數(shù)
54.在作邏輯回歸時����,如果區(qū)域這個變量,當Region=A時Y取值均為1�����,無法確定是否出現(xiàn)的是哪個問題��?(ABD)
A. 共線性
B. 異常值
C. 擬完全分離(Quasi-complete separation)
D. 缺失值
55.下列Z值( BCD )可以被認為是異常值�����。
A、0 B����、-3 C、6 D��、10
56.下列問題( ABC )使用參數(shù)檢驗分析方法���。
A�����、評估燈泡使用壽命 B����、檢驗食品某種成分的含量
C��、全國小學一年級學生一學期的平均課外作業(yè)時間 D�����、全國省市小康指數(shù)高低
57.兩獨立樣本t檢驗的前提( ABC )
A�����、樣本來自的總體服從或近似服從正態(tài)分布 B、兩樣本相互獨立
C���、兩樣本的數(shù)量可以不相等 D、兩樣本的數(shù)量相等
58.兩配對樣本t檢驗的前提( ABD )
A���、樣本來自的總體服從或近似服從正態(tài)分布 B����、兩樣本觀察值的先后順序一一對應
C�����、兩樣本的數(shù)量可以不相等 D�����、兩樣本的數(shù)量相等
59.下面給出的t檢驗的結(jié)果��,( CD )表明接受原假設��,顯著性水平為0.05���。
A�、0.000 B、0.039 C�����、0.092 D��、0.124
60.方差分析的基本假設前提包括( AC )
A���、各總體服從正態(tài)分布 B����、各總體相互獨立
C��、各總體的方差應相同 D�、各總體的方差不同
61.下列( ABC )屬于多選項問題。
A����、購買保險原因調(diào)查 B、高考志愿調(diào)查
C��、儲蓄原因調(diào)查 D����、各省市現(xiàn)代化指數(shù)分析
62.層次聚類的聚類方式分為兩種��,分別是( AB )
A�、凝聚方式聚類 B�、分解方式聚類 C、Q型聚類 D���、R型聚類
——學數(shù)據(jù)分析技能一定要了解的大廠入門券,CDA數(shù)據(jù)分析師認證證書�!

CDA(數(shù)據(jù)分析師認證),與CFA相似�����,由國際范圍內(nèi)數(shù)據(jù)科學領域行業(yè)專家�、學者及知名企業(yè)共同制定并修訂更新,迅速發(fā)展成行業(yè)內(nèi)長期而穩(wěn)定的全球大數(shù)據(jù)及數(shù)據(jù)分析人才標準�,具有專業(yè)化、科學化���、國際化�����、系統(tǒng)化等特性�����。
“CDA數(shù)據(jù)分析師認證”是一套專業(yè)化��,科學化�����,國際化�����,系統(tǒng)化的人才考核標準���,分為CDA LEVELⅠ �����,LEVEL Ⅱ��,LEVEL Ⅲ��,涉及金融����、電商、醫(yī)療����、互聯(lián)網(wǎng)、電信等行業(yè)大數(shù)據(jù)及數(shù)據(jù)分析從業(yè)者所需要具備的技能��,符合當今全球大數(shù)據(jù)及數(shù)據(jù)分析技術潮流�����,為各界企業(yè)�、機構提供數(shù)據(jù)分析人才參照標準��。
報名方式
登錄CDA認證考試官網(wǎng)注冊報名>>點擊報名
報名費用
Level Ⅰ:1200 RMB
Level Ⅱ:1700 RMB
Level Ⅲ:2000 RMB
考試地點
Level I+II:中國區(qū)30+省市���,70+城市�,250+考場�����,考生可就近考場預約考試 >看看我所在的地哪里報名<
Level III:中國區(qū)30所城市�����,北京/上海/天津/重慶/成都/深圳/廣州/濟南/南京/杭州/蘇州/福州/太原/武漢/長沙/西安/貴陽/鄭州/南寧/昆明/烏魯木齊/沈陽/哈爾濱/合肥/石家莊/呼和浩特/南昌/長春/大連/蘭州>看看我所在的地哪里報名<
報考條件
CDA Level I >了解更多<
? 報考條件:無要求。
? 考試時間:隨報隨考��。
CDA Level II >了解更多<
? 報考條件:獲得CDA Level I 認證證書����;
? 考試時間:隨報隨考。
CDA Level III >了解更多<
? 報考條件:獲得CDA Level II認證證書
? 考試時間:一年四屆 3月�����、6月����、9月、12月的最后一個周六��。
——熱門課程推薦:
想了解更多優(yōu)質(zhì)課程�����,請點擊>>>
推薦學習書籍
《CDA一級教材》適合CDA一級考生備考�����,也適合業(yè)務及數(shù)據(jù)分析崗位的從業(yè)者提升自我。完整電子版已上線CDA網(wǎng)校�����,累計已有10萬+在讀~
免費加入閱讀:https://edu.cda.cn/goods/show/3151?targetId=5147&preview=0
CDA數(shù)據(jù)分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330